Multi-Agent 시스템, 정말 효과적일까?
안녕하세요, 오늘은 AI 에이전트 시스템에 관한 논문 하나를 소개해 드리려고 합니다.
최근 AI 에이전트가 화두가 되면서, "에이전트를 여러 개 쓰면 더 좋은 성능을 낼 수 있다"는 생각이 업계에 널리 퍼져 있습니다. 실제로 "More agents is all you need"라는 제목의 논문이 나올 정도로, 다중 에이전트 시스템(Multi-Agent System, MAS)에 대한 기대가 높았죠.
그런데 Google Research와 MIT 연구진이 이에 의문을 제기하는 연구 결과를 발표했습니다. "Towards a Science of Scaling Agent Systems"라는 제목의 이 논문은, 다중 에이전트 시스템이 특정 조건에서는 성능을 크게 끌어올리지만, 그렇지 않은 경우에는 오히려 비용과 오류만 키울 수 있다는 것을 정량적으로 보여줍니다.
왜 이 연구가 필요했나?

AI 에이전트란 LLM 기반으로 추론(Reasoning), 계획(Planning), 행동(Acting)을 반복적으로 수행하면서 환경이나 도구의 피드백에 따라 행동을 조정하는 시스템을 말합니다. 코드 생성, 웹 브라우징, 의료 의사결정, 금융 분석, 과학적 발견 등 다양한 분야에서 활용되고 있죠.
과제가 복잡해질수록 업계는 다중 에이전트 시스템(MAS)에 주목해왔습니다. 전문화된 에이전트들이 협업하면 단일 에이전트보다 더 나은 성능을 낼 것이라는 전제 하에요.
하지만 문제가 있었습니다.
- "언제 에이전트를 추가하면 성능이 좋아지고, 언제 나빠지는가?"에 대한 정량적 기준이 없었습니다
- 기존 MAS 평가들은 서로 다른 프롬프트, 도구, 연산 예산을 사용해 공정한 비교가 어려웠습니다
- 최종 정확도만 측정하고, 조정 오버헤드, 오류 전파, 정보 흐름 같은 과정 역학은 분석되지 않았습니다
연구진은 이 gap을 메우기 위해 180개의 통제된 실험 설정을 구성하고, 에이전트 시스템의 스케일링 원리를 정량적으로 도출했습니다.
공정한 비교를 위한 철저한 통제
에이전트 아키텍처 정의
연구진은 먼저 단일 에이전트 시스템(SAS)과 다중 에이전트 시스템(MAS)을 명확하게 정의했습니다.
단일 에이전트 시스템(SAS)
- 하나의 LLM이 인식, 계획, 행동을 순차적으로 수행
- 도구 사용, 자기 성찰(self-reflection), Chain-of-Thought 추론을 사용하더라도 단일 의사결정 주체
다중 에이전트 시스템(MAS)
- 여러 LLM 기반 에이전트가 메시지 전달, 공유 메모리, 오케스트레이션 프로토콜을 통해 협업
- 네 가지 토폴로지로 구분:

| 아키텍처 | 설명 | 특징 |
| Independent | 에이전트들이 상호작용 없이 병렬 작업 후 결과 합성 | 최대 병렬화, 최소 조정 |
| Decentralized | 에이전트 간 직접 토론을 통해 합의 도출 | P2P 정보 융합 |
| Centralized | 중앙 오케스트레이터가 하위 에이전트들을 조율 | 계층적 검증, 병목 가능성 |
| Hybrid | 계층적 통제 + 제한적 P2P 소통 결합 | 유연성과 통제의 균형 |
Independent (독립형)
각자 알아서 일하고, 마지막에 결과만 모으는 방식입니다. 에이전트끼리 대화가 없어서 빠르지만, 서로 뭘 하는지 모르니까 중복 작업이 생기거나 실수를 잡아주는 사람이 없습니다.
예) 학생 3명이 각자 조사해서 제출하면, 선생님이 그냥 합치는 조별과제
Centralized (중앙집중형)
팀장(오케스트레이터)이 있어서 일을 나눠주고, 결과를 검토하고, 최종 결정을 내립니다. 실수를 잡아낼 수 있지만, 모든 게 팀장을 거쳐야 해서 병목이 생길 수 있습니다.
예) 팀장이 업무 분배하고, 각 팀원 결과물을 검토해서 최종본 만드는 방식
Decentralized (분산형)
팀장 없이 에이전트들끼리 직접 토론하면서 합의를 도출합니다. 다양한 의견이 나올 수 있지만, 토론 시간이 오래 걸릴 수 있습니다.예) 팀원들끼리 회의하면서 서로 의견 조율해서 결론 내는 방식
Hybrid (하이브리드)
팀장도 있고, 팀원들끼리 소통도 하는 방식입니다. 가장 유연하지만, 그만큼 소통 비용이 제일 많이 듭니다.
예) 팀장이 전체 방향 잡아주면서, 팀원들도 서로 협의하는 방식
벤치마크 선정
연구진은 진정한 에이전틱(Agentic) 과제를 평가하기 위해 세 가지 필수 조건을 정의했습니다.
- 순차적 상호의존성: 이후 행동이 이전 관찰에 의존
- 부분 관찰 가능성: 핵심 정보가 숨겨져 있어 능동적 탐색 필요
- 적응적 전략 형성: 상호작용을 통해 얻은 새 증거에 따라 신념 업데이트
이 기준에 따라 네 가지 벤치마크를 선정했습니다.
| 벤치마크 | 과제 유형 | 특징 |
| Workbench | 코드 실행 및 도구 활용 | 명확한 성공/실패 기준, 결정론적 |
| Finance Agent | 금융 분석 | 다단계 정량 추론, 위험 평가 |
| PlanCraft | Minecraft 환경 계획 | 제약 조건 하 시공간 계획 |
| BrowseComp-Plus | 웹 탐색 및 정보 추출 | 동적 상태 진화, 다중 페이지 종합 |
LLM 및 실험 설정
세 가지 LLM 패밀리에서 다양한 성능 수준의 모델을 평가했습니다.
- OpenAI: GPT-5-nano, GPT-5-mini, GPT-5
- Google: Gemini 2.0 Flash, 2.5 Flash, 2.5 Pro
- Anthropic: Claude Sonnet 3.7, 4.0, 4.5
총 180개 실험 설정(5개 아키텍처 × 4개 벤치마크 × 9개 모델)에서 동일한 도구, 프롬프트, 토큰 예산을 적용하여 아키텍처 효과만 분리했습니다.
세 가지 지배적 패턴

1. 도구-조정 트레이드오프 (Tool-Coordination Trade-off)
도구가 많은 과제일수록 다중 에이전트 오버헤드로 인한 성능 저하가 심하다
연산 자원이 한정된 상황에서 에이전트 수를 늘리면, 각 에이전트가 활용할 수 있는 맥락 정보(토큰)가 줄어듭니다.
정량적 결과:
- 단일 에이전트: 효율성(𝐸𝑐) = 0.466
- 다중 에이전트: 효율성 = 0.074 ~ 0.234 (2~6배 비효율적)
- 회귀 분석 결과: 𝛽 = −0.267, p < 0.001
특히 10개 이상의 도구를 사용하는 환경에서 이 효과가 두드러졌습니다. 에이전트가 늘어날수록 각자가 도구를 효과적으로 활용할 여력이 줄어들기 때문입니다.
2. 성능 포화 현상 (Capability Saturation)
단일 에이전트 성능이 ~45%를 넘으면, 에이전트 추가는 역효과
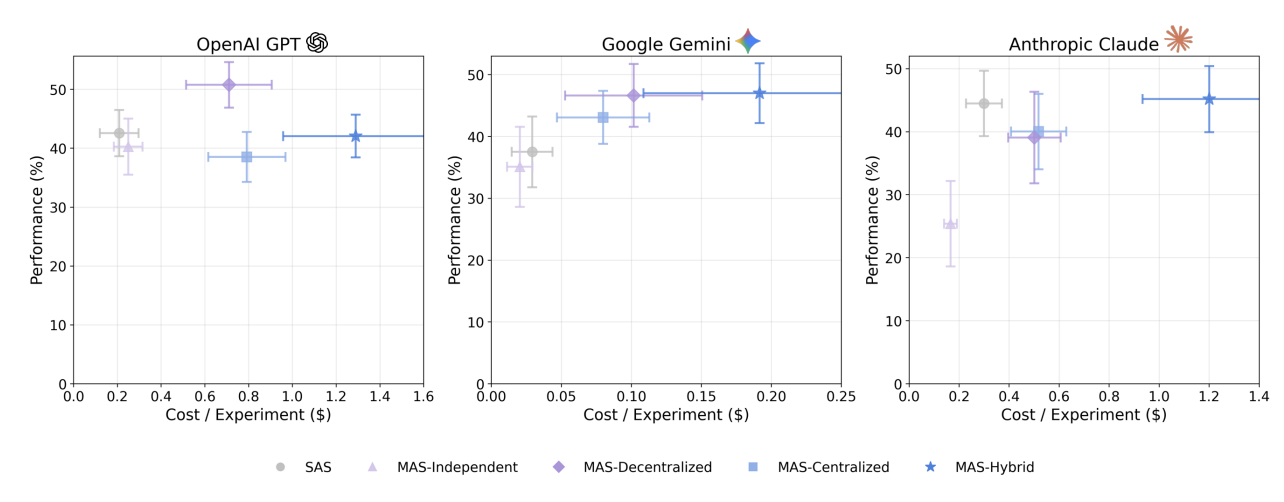
단일 에이전트 기준선이 이미 45% 정확도를 넘는 과제에서는 조정 비용이 개선 가능성을 초과합니다.
정량적 결과:
- 회귀 계수: 𝛽 = −0.404, p < 0.001 (가장 큰 효과 크기)
- 임계값: 약 45% (표준화된 단위로 0.129)
이는 "이미 잘 작동하는 것에 에이전트를 추가하지 말라"는 실용적 지침을 제공합니다.
3. 아키텍처 의존적 오류 증폭 (Architecture-Dependent Error Amplification)
협업 구조에 따라 오류 증폭 정도가 4배에서 17배까지 차이

| 아키텍처 | 오류 증폭률 (𝐴𝑒) | 설명 |
| SAS | 1.0× | 기준선 |
| Independent | 17.2× | 검증 메커니즘 없음, 오류 직접 전파 |
| Decentralized | 7.8× | P2P 토론으로 일부 검증 |
| Centralized | 4.4× | 검증 병목이 오류 차단 |
| Hybrid | 5.1× | 중간 수준 |
핵심 인사이트: Independent 아키텍처는 에이전트 간 소통이 없어 오류가 그대로 최종 결과로 전파됩니다. 반면 Centralized는 중앙에서 결과를 점검하는 단계가 있어 오류 전파를 억제합니다.
왜 같은 MAS가 다른 결과를 보이는가?
Finance Agent: MAS의 압도적으로 좋은 결과 (+57% ~ +81%)
금융 분석 과제에서는 모든 MAS 변형이 SAS를 크게 앞섰습니다.
- Centralized: +80.8%
- Decentralized: +74.5%
- Hybrid: +73.1%
왜? 금융 분석은 자연스럽게 병렬 수행이 가능한 구조입니다.
- Agent 1: 규제/뉴스 분석
- Agent 2: SEC 공시 연구
- Agent 3: 운영 영향 평가
- Orchestrator: 다중 소스 발견 종합
각 하위 과제(매출 분석, 비용 구조, 시장 비교)를 독립적으로 수행한 후 종합할 수 있어, 조정 구조가 과제 구조와 정렬됩니다.
PlanCraft: MAS의 보편적으로 좋지 않은 결과 (−39% ~ −70%)
Minecraft 환경 계획 과제에서는 모든 MAS 방법이 성능 저하를 보였습니다.
- Independent: −70.1%
- Centralized: −50.3%
- Decentralized: −41.5%
- Hybrid: −39.1%
왜? PlanCraft는 엄격한 순차적 의존성을 가진 과제입니다. 예를 들어 diorite_wall을 제작하려면
Turn 1: search("diorite_wall") → 레시피: 6 diorite in 2x3
Turn 2: move(diorite → crafting_grid)
Turn 3: craft → 완료이런 단순한 순차 과제를 MAS는 불필요하게 분해합니다.
Agent 1: 레시피 연구 (불필요 - 조회는 즉시 완료)
Agent 2: 인벤토리 확인 (불필요 - 상태는 모두에게 보임)
Agent 3: 제작 실행 (유일하게 필요한 단계)이런 인위적인 분해가 조정 메시지를 오히려 대량 생성하고, 토큰을 추론이 아닌 조정에 소비하게 만듭니다.
BrowseComp-Plus: 제한적 개선 (+0.2% ~ +9.2%)
웹 탐색 과제에서는 개선이 미미했습니다.
- Decentralized: +9.2%
- Centralized: +0.2%
왜? 동적 웹 탐색은 Information gain(ΔI)이 불확실합니다. Finance Agent에서는 ΔI와 MAS-SAS 격차가 강한 상관관계(r = 0.71)를 보였지만, BrowseComp-Plus에서는 약한 상관관계(r = 0.18)만 나타났습니다. 에이전트들이 교환하는 메시지가 검증된 정보를 제공하기 어려운 것이죠.
Workbench: 미미한 효과 (−11% ~ +6%)
도구 실행 과제에서는 MAS의 효과가 거의 없었습니다. 여러 에이전트를 써서 얻는 이점만큼 조정 비용도 늘어나서, 결국 큰 차이가 나지 않은 것입니다.
GPT-5.2에서 확인
연구진은 연구 완료 후 출시된 GPT-5.2(Intelligence Index = 75)로 모델을 검증했습니다.

연구에서 도출한 5가지 스케일링 원리 중 4가지가 GPT-5.2에서도 동일하게 적용되는 것을 확인했습니다. 성능 포화 현상, Independent 아키텍처의 성능 저하, Centralized/Decentralized의 우수성, Hybrid의 오버헤드 문제 등이 새로운 모델에서도 그대로 나타났습니다.
에이전트 수 스케일링: "4명의 법칙"

연구진은 에이전트 수(1~9명)에 따른 성능 변화도 분석했습니다. 결론부터 말하면, 에이전트는 3~4명이 최적입니다. 그 이상으로 늘리면 에이전트 간 소통 비용이 급격히 증가해서, 성능 향상보다 오버헤드가 더 커집니다. 실제로 Hybrid 시스템은 단일 에이전트보다 6.2배 더 많은 추론 턴이 필요했습니다.
더 비싼 모델이 항상 좋은가?

연구진은 서로 다른 성능의 모델을 섞어서 쓰면 어떻게 되는지도 테스트했습니다. 흥미롭게도, 비싼 모델을 모든 역할에 쓰는 것이 항상 좋은 건 아니었습니다. Anthropic 모델의 경우, 오케스트레이터에 저성능 모델을 쓰고 하위 에이전트에 고성능 모델을 쓴 조합이 전부 고성능 모델을 쓴 것보다 31% 더 좋은 결과를 보였습니다. 즉, 역할에 따라 적절한 모델을 배치하는 게 더 효과적입니다.
- Anthropic 모델: 저능력 오케스트레이터 + 고능력 하위 에이전트(0.42)가 동질적 고능력(0.32)보다 31% 우수
- Decentralized 혼합 능력: 거의 모든 모델 패밀리에서 동질적 고능력과 동등하거나 우수
- Centralized: 오케스트레이터 능력보다 하위 에이전트 능력이 더 중요
LLM 패밀리별 특성
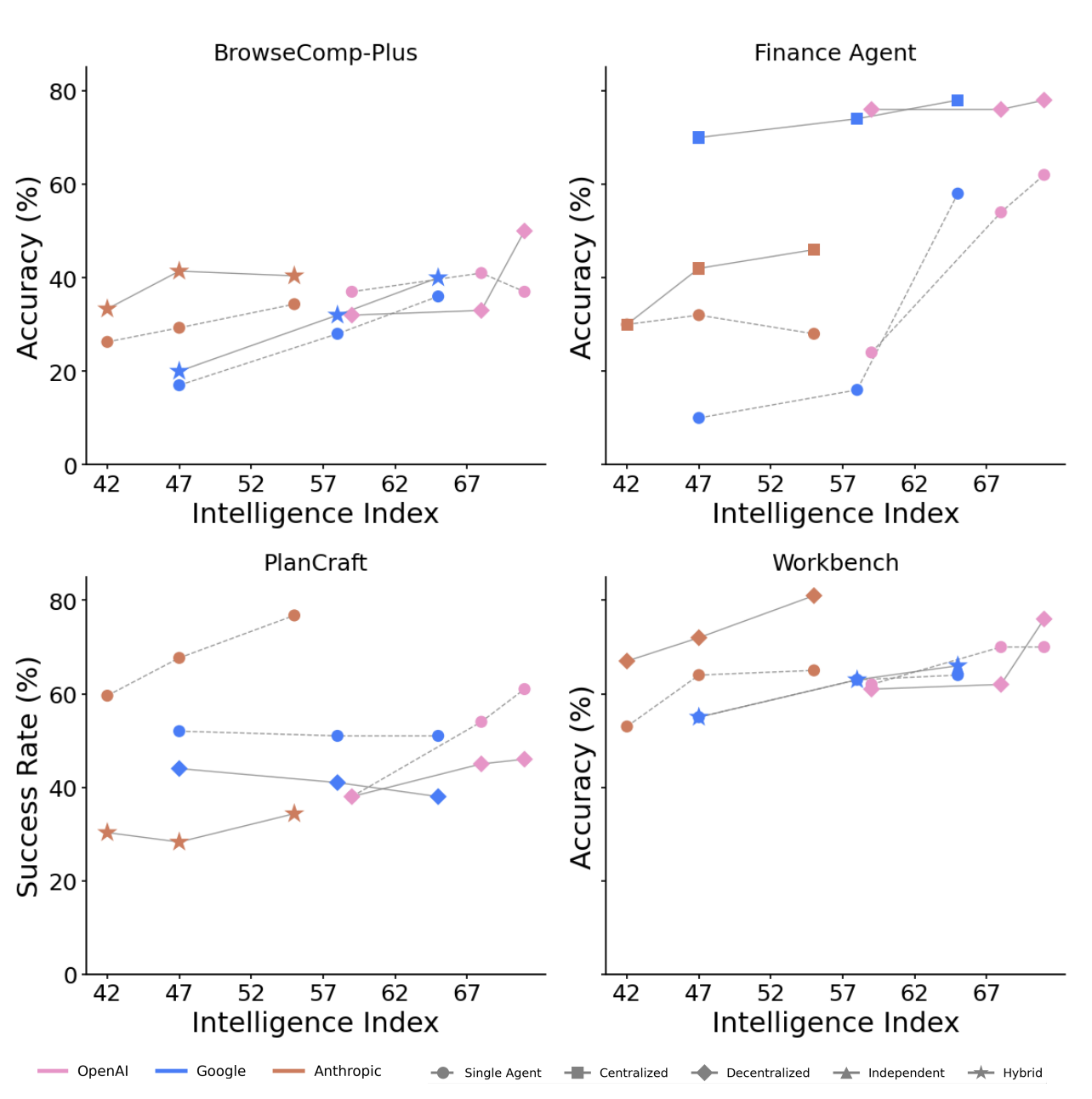
각 LLM은 각각 잘 맞는 아키텍처가 달랐습니다. OpenAI는 Hybrid에서 강한 시너지를 보였고, Google은 어떤 아키텍처를 써도 성능 차이가 5% 미만으로 안정적이었습니다. Anthropic은 Centralized에서 가장 일관된 성능을 보였습니다. 즉, 어떤 모델을 쓰느냐에 따라 최적의 아키텍처도 달라질 수 있습니다.
언제, 어떤 아키텍처를 선택할 것인가?
연구진이 제시한 실용적 지침을 정리하면 다음과 같습니다.
1단계: 단일 에이전트 기준선 먼저 측정
- 단일 에이전트로 성능을 먼저 점검
- 정확도가 45%를 넘으면 에이전트 추가는 비용만 증가시킬 가능성 높음
2단계: 과제 특성 분석
| 과제 특성 | 권장 아키텍처 |
| 병렬 분해 가능 (금융 분석 등) | Centralized 또는 Decentralized |
| 순차적 의존성 높음 (계획, 추론 등) | SAS 유지 |
| 다중 경로 탐색 필요 (웹 탐색 등) | Decentralized |
| 높은 정확성/신뢰성 필요 | Centralized (오류 억제) |
3단계: 도구 수 고려
- 도구가 많을수록 → 단순한 아키텍처가 효과적
- 10개 이상 도구 → MAS 오버헤드가 이점을 상쇄
4단계: 에이전트 수 제한
- 3~4명이 최적
- 그 이상에서는 조정 오버헤드가 급증
아키텍처 선택 의사결정 경계
연구진이 도출한 정량적 기준
단일 에이전트 성능 < 45% → MAS 고려
단일 에이전트 성능 ≥ 45% → SAS 유지여기서 45%는 해당 과제의 정확도(또는 성공률)를 의미합니다. 예를 들어 금융 분석 과제에서 단일 에이전트가 100개 중 45개 이상을 맞춘다면, 굳이 에이전트를 늘릴 필요가 없다는 뜻입니다. 이 임계값은 180개 실험 데이터에서 도출된 수치입니다.
한계점 및 향후 연구 방향
연구진은 다음 한계점을 인정했습니다.
- 에이전트 수 스케일링: 최대 9명까지만 테스트, 더 큰 집단에서의 창발적 행동은 미확인
- 모델 다양성: 동일 패밀리 내 다른 크기의 모델만 혼합, 근본적으로 다른 아키텍처 조합은 미탐구
- 도구 집약적 환경: 도구가 많은 환경을 위한 특화된 조정 프로토콜 개발 필요
- 프롬프트 최적화: 아키텍처별 프롬프트 튜닝은 수행하지 않음
- 벤치마크 범위: 4개 벤치마크로 제한, 구현된 에이전트나 다중 사용자 상호작용은 미포함
결론: "More Agents"가 아닌 "Right Agents"
이 연구는 "에이전트를 많이 쓰면 성능이 좋아진다"는 가정을 정량적으로 검증하고, 그것이 항상 참이 아님을 보여줬습니다.
핵심 메시지:
- MAS 성능은 에이전트 수가 아닌 과제 특성과 아키텍처 정렬에 의해 결정됩니다
- 성능 범위: +80.9% (Finance Agent, Centralized) ~ −70.0% (PlanCraft, Independent)
- 도구가 많거나, 기준선이 높거나, 순차적 의존성이 있는 과제에서는 SAS가 우수
- 병렬 분해 가능하고 기준선이 낮은 과제에서는 Centralized/Decentralized가 효과적
연구진이 개발한 예측 모델은 과제의 특성만 보고도 87% 정확도로 최적 아키텍처를 예측할 수 있었습니다. 이제 "에이전트를 몇 개 쓸까?"가 아니라 "이 과제에 어떤 아키텍처가 맞을까?"를 먼저 고민해야 할 것 같습니다.
참고
'Tech & Development > AI' 카테고리의 다른 글
| Claude Code 완벽 가이드 (2) - 커스텀 명령어부터 고급 활용까지 (0) | 2026.01.08 |
|---|---|
| Claude Code 완벽 가이드 (1) - 설치부터 기본 기능까지 (0) | 2026.01.08 |
| Claude Agent Skills: AI를 나만의 전문가로 만드는 방법 (0) | 2025.12.30 |
| DeepSeek R1 로컬(Local) 설치 가이드 (0) | 2025.02.03 |
| AI로 시작하는 No-code 개발: MVP부터 프로토타입까지 (0) | 2025.01.28 |