Object Detection 정리 (History)
이미지 내에서 사물을 인식하는 방법에는 다양한 유형이 존재합니다. 그중 Object Detection에 대해 정리를 하려고 합니다. 먼저 내용은 개인적인 경험을 바탕으로 한 매우 주관적인 내용이라는 점을 미리 말씀드립니다.
저는 사실 Object Detection을 처음 접한 것은 2018년이라고 해야 할 것 같습니다. 이미지에서 내가 원하는 영역만 찾으면 좋겠다는 생각은 했지만, Public Dataset이 아닌 내가 원하는 Object를 기준으로 Dataset을 만들고 학습시키는 과정이 처음에는 쉽지 않았습니다. 처음에 R-CNN을 이용하여 개발해보고 "이 결과가 잘 나온 것인가?"라는 의문도 들었던 때도 있었고, YOLO를 개발하기 위해 Darknet Framwork를 설치하고 환경설정을 하면서 꽤 애를 먹었던 기억도 있습니다.
현재 Object Detection에 대한 수많은 연구가 진행되면서 다양한 Model이 등장했습니다. Object Detection Model은 1-stage Detector와 2-stage Detector로 구분할 수 있는데 이 글에서는 언급하지 않겠습니다. 상세 내용은 이전 글을 참고하시기 바랍니다.
Object Detection 이란 무엇인가?

Object Detection은 사진이나 비디오 프레임과 같은 디지털 이미지에서 특정 클래스(예: 인간, 동물, 자동차 또는 건물)를 감지하는 데 사용되는 Computer vision 작업입니다. 간단히 말해 "어디에 어떤 객체가 있다"라고 답을 주는 것입니다.
Traditional Detection Methods
2012년 AlexNet이 등장하기 전에는 이미지 연산을 활용하거나 몇몇 전문가들에 의해 만들어진 특성(Hand-Crafted Features)을 기반으로 문제를 풀어왔습니다. 간단히 말하자면 이미지에는 색상, 연결점, 연결선 등의 다양한 특징들이 존재하는데 이러한 정보를 활용하거나 가공하여 이미지에서 "이 위치에 물체는 OO 같다"라고 추론하는 거죠.
대표적으로 HOG(Histograms of Oriented Gradients)나 DPM(Deformable Part-based Model)이 있습니다.
물론 전통적인 이미지 처리 방식은 근래의 DeepLearning 기반의 알고리즘보다 정확도는 떨어집니다. 하지만 여전히 오늘날 Object detection 연구와 매우 관련성이 깊고 유용하다고 생각합니다. 아래는 다양한 방법을 소개하는 글입니다.
- Shape Detection
- Color Detection
- Bright Spot Detection
- Template Match Detection
- Color Detection using XGBoost (M/L)
- Haar Cascades를 이용한 얼굴 인식방법
DeepLearning based Detection Methods
2012년 AlexNet이 AI Classification 대회인 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)에 등장합니다. 당시 오차율 15.3%로 다른 모델들에 비해 매우 압도적인 결과로 우승합니다. (당시 2위는 26.2%로 오차율로 10% 이상 차이가 납니다. 그리고 2011년 우승 모델 오차율이 25.8%였으니 오차율만 보자면 약 40% 이상 좋아진 겁니다.) AlexNet의 우승으로 그동안 막대한 연산량과 실용성의 문제로 외면받아 왔던 Deep Learning이 획기적인 전환점을 맞이하게 되고 CNN(Convolutional Neural Network)의 부흥이 시작됩니다.
그리고 Deep Learning을 이용한 Object Detection은 2014년(논문 기준으로 2013년 11월)을 기준으로 나타나기 시작합니다.
1. R-CNN
Rich feature hierarchies for accurate object detection and semantic segmentation
Object detection performance, as measured on the canonical PASCAL VOC dataset, has plateaued in the last few years. The best-performing methods are complex ensemble systems that typically combine multiple low-level image features with high-level context. I
arxiv.org
R-CNN은 'Regions with Convolutional Neuron Networks features'의 약자로, 설정한 Region을 CNN의 feature(입력값)로 활용하여 Object Detection을 수행하는 신경망이라는 의미를 담고 있습니다. Object Detection 분야에 딥러닝을 최초로 적용한 모델이자 이전의 Object Detection 모델들과 비교해 성능을 상당히 향상한 모델입니다. 논문은 2013년 11월에 등재되었습니다. R-CNN 구조는 3가지의 Module(Extract region proposals, Compute CNN features, Classify regions)로 구성되어 있습니다. 마지막 Classify regions는 위에서 언급한 AlexNet을 사용합니다.
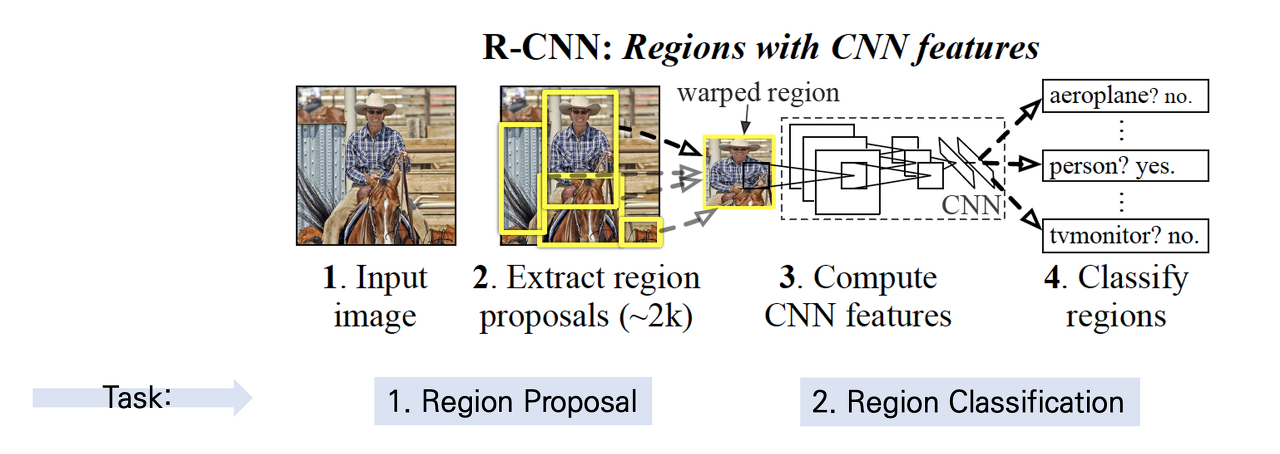
R-CNN은 Object Detection에 딥러닝을 최초로 적용시키고 이전 Object Detection 모델들에 비해 뛰어난 성능을 보였다는 것은 분명하지만 성능이 매우 나쁩니다. GPU환경에서는 이미지 한장당 13초가 걸리며 CPU로는 53초가 걸린다고 설명하고 있습니다. 실제 제 노트북 환경에서는 더 오래 걸렸습니다. 오래 걸릴 수 밖에 없는 것이 내부에서 사용되는 모델이 3개 이상이고 각 모듈이 동시에 수행되지 않고 순차적으로 진행되기때문에 Real-Time에서는 활용하기 어렵습니다.
이후 Fast R-CNN, Faster R-CNN으로 발전합니다.
2. YOLO
You Only Look Once: Unified, Real-Time Object Detection
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabili
arxiv.org
YOLO는 You Only Look Once의 약자로 2015년 6월에 처음 등장합니다. YOLO가 등장할 당시만 하더라도 Faster R-CNN 계열이 나름 매우 좋은 성능을 내고 있었습니다. 하지만 위에서 설명한 것처럼 R-CNN은 처리 속도가 매우 나빴고 이후 나온 계열들도 명칭은 Fast, Faster 가 붙었지만, 이전 R-CNN보다 빨라졌다는 뜻이지 실제 처리 속도가 빠르다는 뜻이 아녔습니다. 실제로 Fast R-CNN은 0.5 FPS (초당 프레임 수)였고, Faster R-CNN은 7 FPS였습니다.
반면 YOLO는 45 FPS를 보여주며 등장합니다. 빠른 버전은 155 FPS까지 기록하며 사람들을 놀라게 했죠. 이러한 처리 속도는 영상을 스트리밍하는 동시에 객체를 부드럽게 구분할 수 있을 정도였습니다.

사실 그럴 것이 YOLO는 R-CNN과 달리 높은 정확도를 추구하는 것이 아니라 최대한 근접한 정확도를 가지면서 더 많은 양의 이미지를 처리하여 실시간으로 객체를 탐지하는데 목표를 두고 있었습니다. 위에 설명한 것과 같이 R-CNN 다양한 전처리 모델과 인공 신경망을 결합하여 사용했지만, YOLO는 단 하나의 인공신경망으로 처리합니다. 그렇기 때문에 다른 모델보다 간단하기도 했고 실시간 객체 탐지도 가능했던 거죠.

YOLO는 조셉 레드몬(Joe Redmon)가 2015년 v1을 시작으로, 정확도를 보완하여 2016년에 v2를 발표하고 2018년에 v3까지 차례로 공개했습니다. 그리고 조셉 레드몬은 Darknet 프레임워크를 개발한 것으로도 유명합니다. Darknet은 C 기반으로 개발된 오픈 소스 신경망 프레임워크이며 빠르고 설치가 쉽고 CPU 및 GPU 계산을 지원한다는 장점이 있습니다.

YOLO는 빠른 처리 속도를 추구하고 있었기 때문에 Python보다는 C기반으로 개발했던 것 같습니다. (그렇다 보니 제가 YOLOv3를 Python으로 개발할 당시 오류가 발생하면 Darknet 코드 일부를 수정해가며 개발했던 기억이 있습니다)
하지만 조셉 레드몬은 v3를 발표하고 2년 뒤인 2020년 2월에 자신의 트윗에 자신의 연구가 공익적 목적보다 군사적으로 활용되는 것과 개인정보 침해에 대한 우려를 표하며 비전 연구 중단을 선언합니다.
중단을 선언한 2개월 뒤 2020년 4월에 Alexey Bochkovskiy가 YOLOv4를 발표합니다. YOLOv4는 YOLOv3에 다양한 기술을 추가하여 만든 모델입니다. (YOLO v4 = YOLO v3 + CSPDarknet53(backbone) + SPP + PAN + BoF + BoS)
YOLOv4가 발표되고 두 달도 채 되지 않은 2020년 6월에 YOLOv5를 발표됩니다. 참고로 YOLOv4 (Alexey Bochkovskiy)와 YOLOv5 (Glenn Jocher)는 연구개발자가 다릅니다. YOLOv5 가장 큰 변화는 Darknet이 아닌 Pytorch로 구현했다는 것이고 YOLOv5는 arXiv의 paper나 Tech Report가 아닌 개인 블로그를 통해 간략히 성능 등의 내용만 공개합니다. YOLOv5에 대해 Community에서 많은 이견이 있었고 여전히 YOLOv5는 YOLO가 아니라는 논란도 있습니다. 이후 YOLOv5는 YOLOv6로, YOLOv4는 Scaled YOLOv4로 발전해 나갑니다. Alexey와 함께 Scaled YOLOv4 함께 개발한 팀원들이 후속 연구로 개발하여 발표한 것이 YOLO R입니다.
YOLO는 버전도 많고 각 라이선스 정책도 다릅니다. 사실 v 뒤에 붙는 숫자는 연관성이 있는 버전이라기보다는 각자 다른 형태의 연구 버전이라고 보시면 됩니다.
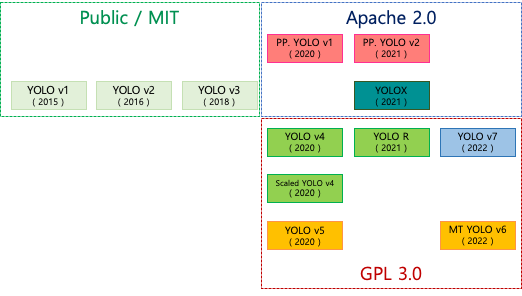
실제 최근에 나온 YOLOv7은 Github에 YOLOv7은 YOLO 계열의 후계자가 아니라고 설명하고 있습니다. detectron2에 기반으로 만들었으며 단지 7이라는 숫자는 버전 7을 의미하는 것이 아니라 마법과 행운의 숫자 7을 의미한다고 설명합니다.

최근에 저는 YOLOv5 나 YOLOv7으로 개발하면서 정말 많이 편해졌고 성능도 좋아졌다고 느꼈습니다. 속도는 빠르지만 정확도 측면에서 부족하다고 인식되던 YOLO 계열의 모델들이 이미 SOTA(State-Of-The-Art) 모델에 가까울 정도로 FPS나 Accuracy에서 모두 뛰어난 결과를 내고 있습니다. (YOLO에 대해서는 이쯤으로 하고 나중에 기회가 된다면 버전별로 다른 점을 분석하여 작성하도록 하겠습니다.)
3. EfficientDet
EfficientDet: Scalable and Efficient Object Detection
Model efficiency has become increasingly important in computer vision. In this paper, we systematically study neural network architecture design choices for object detection and propose several key optimizations to improve efficiency. First, we propose a w
arxiv.org
EfficientDet을 말하기 이전에 먼저 EfficientNet이 2019년 3월에 등장합니다. EfficientNet은 Image Classification 문제를 해결하기 위해 등장한 논문인데 논문의 부제부터 보면 "Rethinking Model Scaling for Convolutional Neural Networks"라고 되어 있습니다. CNN 모델을 Scaling 하는 방법에 대해 다시 생각해보자라고 말하고 있습니다.
AlexNet 이후 ImageNet competition에서는 연산량이 커지면서 정확도가 높아지는 Image Classification 모델들이 여럿 발표되었습니다. 기본적으로는 연산량이 늘어날수록 성능이 올라가는 것을 볼 수 있었는데, 늘어나는 연산량으로 인해 하드웨어 비용 즉 값이 비싼 GPU를 사용하여야 한다는 단점이 있었습니다. 당시 같은 연산량으로 어떻게 좋은 성능을 낼 수 있을지에 대한 많은 논의가 있었는데 그중 하나의 논문이 EfficientNet입니다.
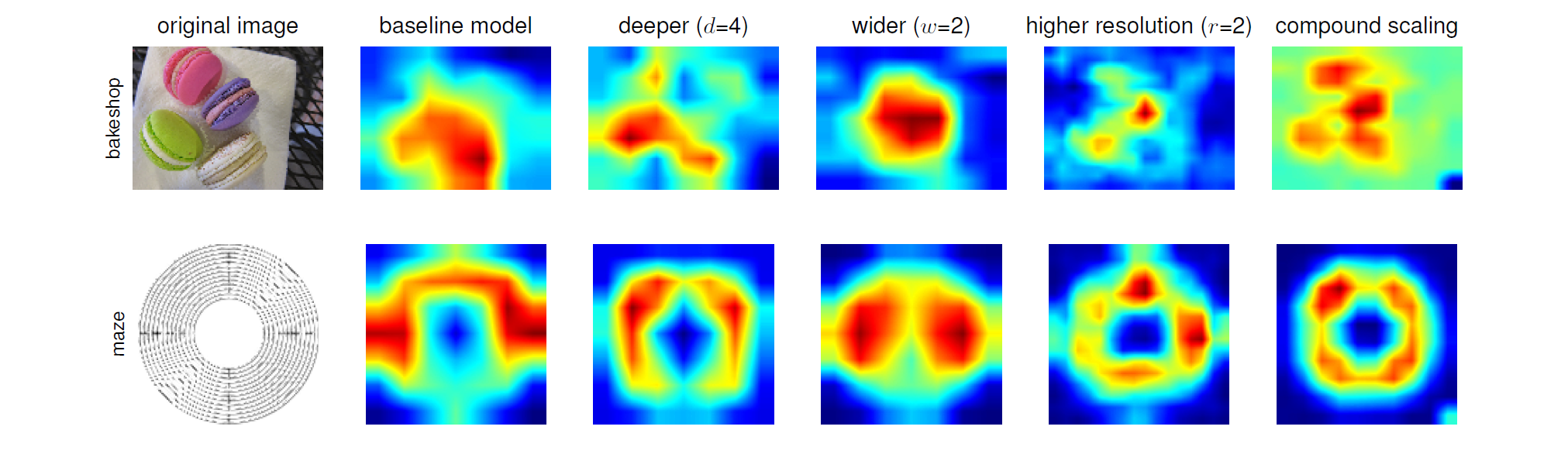
기존 모델들은 accuracy를 높이기 위해 거대한 Backbone networks 사용하거나 큰 input image size에 의존합니다. EfficientNet은 한정된 자원으로 최대의 효율을 내기 위한 방법으로 Compound Scaling Method(Width Scaling + Depth Scaling + Resolution Scaling)를 제안하고 있습니다. 기본적으로 Model을 Scaling 할 때 연산량을 늘려가며 Width Scaling(Filter), Depth Scaling(Layer), Resolution Scaling(Input resolution)을 수행하는데 AutoML을 이용하여 최적의 조합을 찾아주는 방법이죠. (그래서 이름을 Efficient + Network 효율적인 네트워크라 정한 것 같네요)
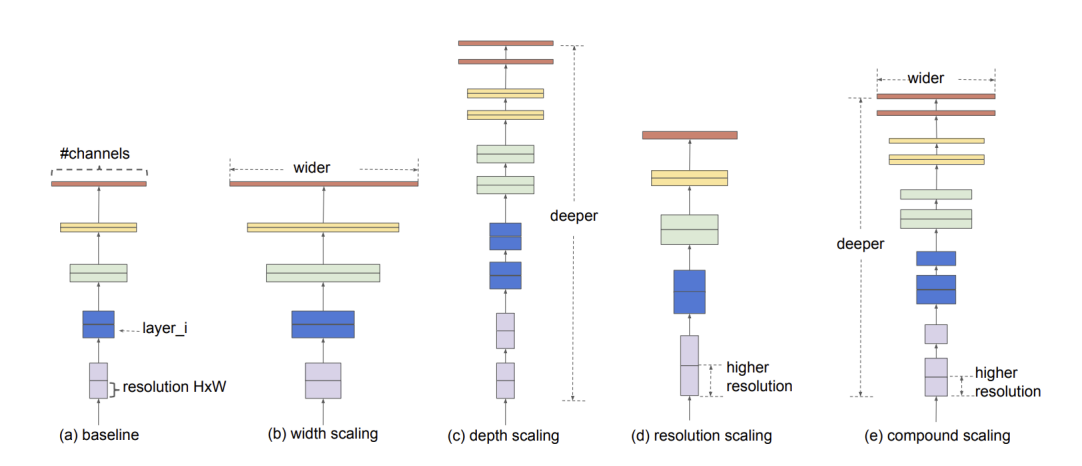
EfficientNet은 Compound Scaling Method를 통해 기존 모델들보다 훨씬 적은 파라미터의 수로 높은 성능을 내며 Classification SOTA모델이 됩니다. (기존 ConvNet 모델들보다 8.4배 작으면서 6.1배 빠르고 더 높은 정확도를 가짐)
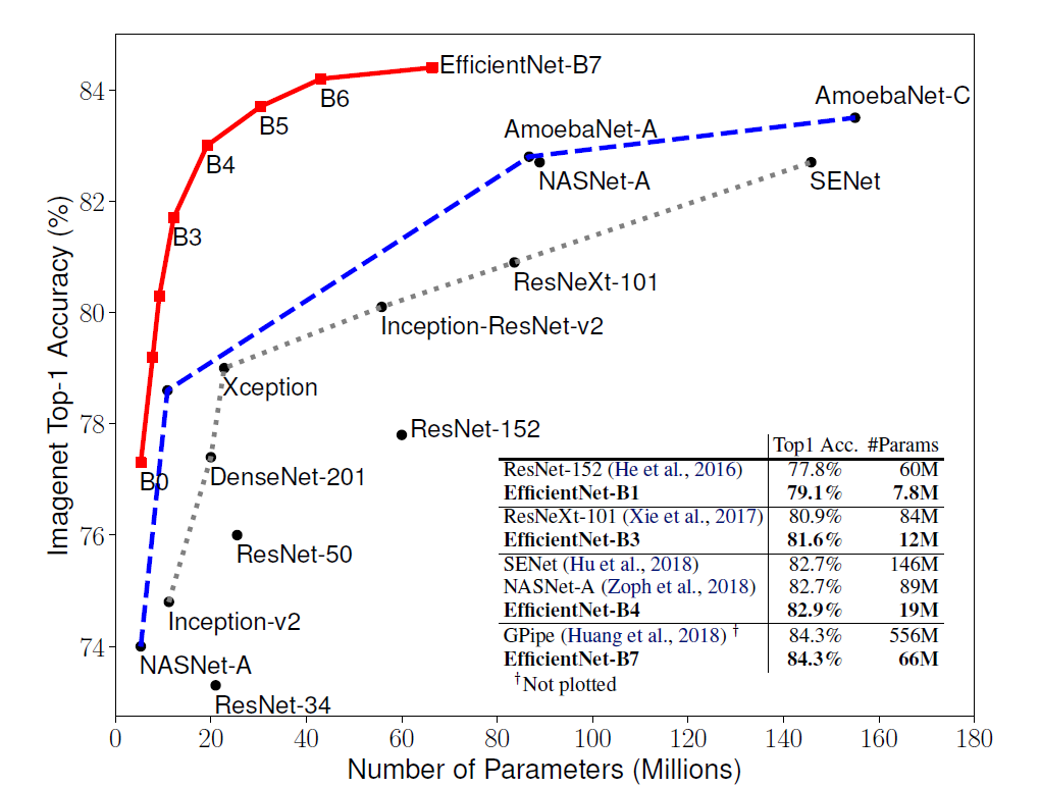
아래는 Compound Scaling이 다른 Scaling만 적용했을 때보다 얼마나 효과적인지 보여주고 있습니다.
이후 이러한 EfficientNet을 Backbone으로 하고 Cross-scale connection/weighted feature fusion을 담은 Bi-FPN을 추가하여 2019년 11월에 Object detection 모델인 EfficientDet이 등장합니다.
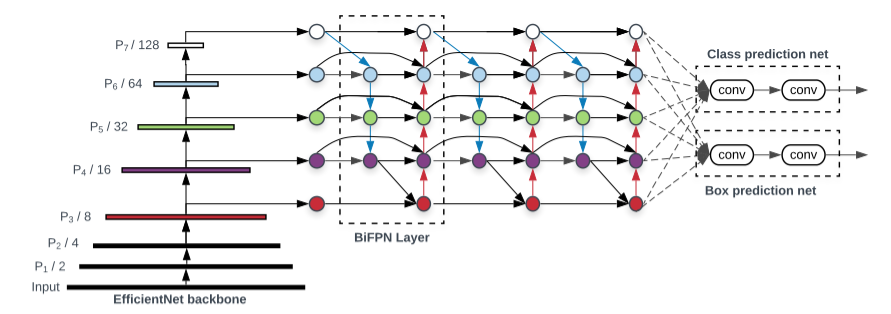
EfficientNet의 scaling에 사용된 parameter인 를 바꾸면서, EfficientDet은 D0~D7까지 만들어졌습니다.
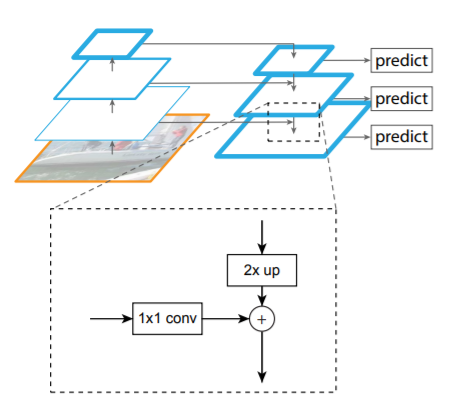
BiFPN의 기본 원리가 되는 FPN(Feature Pyramid Network)는 다양한 크기의 Object를 detection 하기 위해서 제안되었습니다. FPN의 기본 Motivation을 쉽게 설명하면, 큰 자동차에서 뽑은 Feature map을 그대로 작은 자동차에 갖다 대면, 같은 물체라고 식별하는 능력이 떨어질 수 있기 때문에, 다양한 사이즈로 학습된 Feature map을 갖다 대보자는 것이었습니다. 그런데, 각각 Feature map을 전부 학습시켜서, 저장하고 있다가, 이미지에 전부 갖다 대면, 메모리/연산량이 비효율적이기 때문에, 아래 그림처럼, 여러 층에서 뽑힌 Feature map을 재활용하여 서로 보완해주게 만들어 다양한 사이즈의 이미지를 잘 Detection 할 수 있게 되는 것입니다.
BiFPN은 위에서 설명한 FPN에 Cross-Scale Connection과 weighted feature fusion을 추가한 알고리즘입니다.
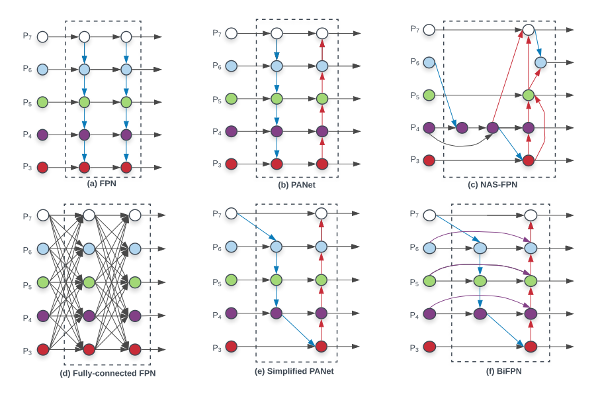
(a) FPN : 전통적인 FPN 구조
(b) PANet : bottom-up pathway를 FPN에 추가
(c) MAS-FPN : AutoML의 Neural Architecture Search를 FPN 구조에 적용 (불규칙적 구조), (c) 구조부터는 scale이 다른 경우에도 connection이 존재하는 Cross-Scale Connection 을 적용
(d) Fully-connected FPN (본 논문에서 제안한 방식) : FPN가 FC된 형태
(e) Simplified PANet (본 논문에서 제안한 방식) : Input edge가 1개인 node들은 기여도가 적을 것 → 제거
(f) BiFPN (본 논문에서 제안한 방식) : 보라색 선처럼 같은 scale에서 edge를 추가하여 더 많은 feature들이 fusion되도록 구성을 한 방식
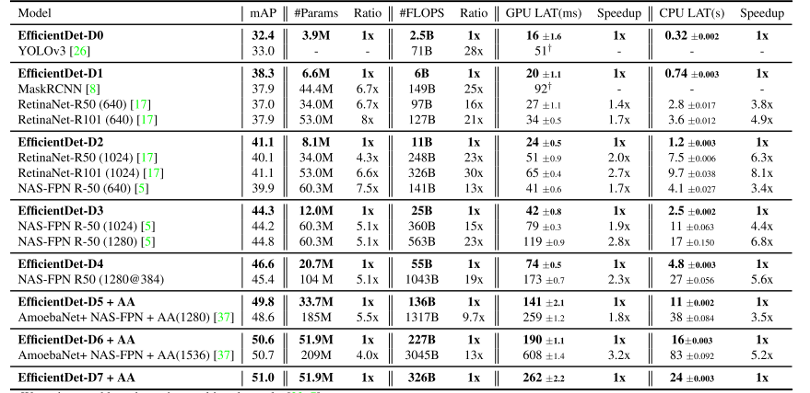
결과적으로 EfficientDet은 COCO Dataset 기준으로 50 AP를 넘기며 가장 높은 정확도를 달성하였고 기존 연구들 대비 매우 적은 연산량(FLOPS)으로 비슷한 정확도를 달성할 수 있음을 보여주었습니다. 이는 Object Detection 모델의 새로운 시작을 알렸고 2020년 초반까지 SOTA 모델의 자리를 지키게 됩니다.
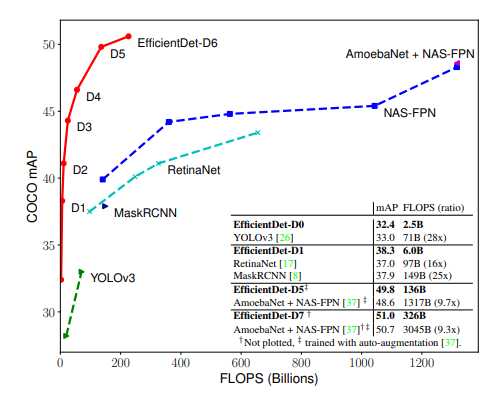
인상적인 것은 사실 이 시기에는 다양한 Object detection 모델들이 쏟아져 나왔는데, EfficientDet은 압도적인 정확도로 단숨에 서열을 정리해버린 것입니다. 거기다 적은 parameter 수와 연산량, 낮은 Latency를 보여주면서 매우 실용적인 모습도 보여줬죠.
이후 수많은 알고리즘이 등장하는데 대부분 EfficientDet을 Baseline으로 계속 언급하는 것을 보면 얼마나 훌륭한 모델인지 아실 수 있으실 것입니다.
4. DETR
End-to-End Object Detection with Transformers
We present a new method that views object detection as a direct set prediction problem. Our approach streamlines the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor gene
arxiv.org
End-to-End Object Detection with Transformers 이란 논문이 ECCV라는 Vision 연구 학회를 통해 발표됩니다. 이 논문은 출시가 되자마자 많은 이목을 끌었는데 그 이유는 구조가 매우 간단하고 경쟁력 있는 성능을 보였기 때문입니다. 간단히 DETR이라고 부르는데 Detection Transformer를 줄인 약어입니다.
기존의 Object detection 모델들은 매우 복잡하고 다양한 라이브러리를 사용하기 때문에 사용자 입장에서 고려해야 할 사항이 많았습니다. 이 논문에서는 그러한 고려 사항을 사전 지식(prior knowledge)이라고 표현합니다. 대표적으로 Region proposal, Anchor box, NMS 등이 있는데 성능을 올리기 위해서 사용자는 이런 내용을 숙지하고 해결하기 위해 코드를 작성하거나 해야 했던 거죠. 이런 개념을 모두 이해하기도 어려울 뿐만 아니라 실제로 구현하기도 쉽지 않고 코드도 길어지게 됩니다. 이를 해결하기 위해 이분 매칭(Bipartite Matching)과 Transformer 기법을 적용한 것이 특징입니다.
NMS(Non-maximum Suppression)는 하나의 Object에 여러개의 bounding box가 생겼을 경우 가장 높은 Score의 box만 남기고 나머지는 제거하는 방법

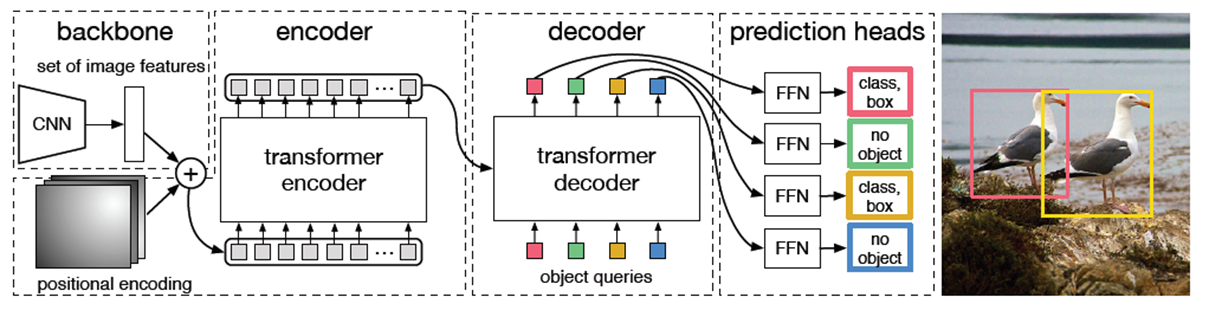
DETR은 어려운 개념들을 적용하지 않아 네트워크 구조가 단순하면서 end-to-end 학습이 가능하다고 설명하고 있습니다. 예로 NMS나 Region proposal 같은 개념 없이도 정확하게 Object를 detection 하기 위해서 이분 매칭(Bipartite Matching)을 통해 추출된 영역이 겹치거나 여러 번 검출이 되는 문제, 인스턴스 중복 문제를 충분히 해결합니다.
NMS는 몇 개의 Object가 존재하는 지 특정하지 않고 무작위로 존재 할 법한 위치를 찾은 다음 압축해 나가는 과정이라면 Bipratite Matching은 몇개의 Object가 있다고 특정하고 집합을 매칭해나가는 방법이라고 보시면 됩니다.
DETR의 네트워크 구조는 CNN Backbone + Transformer + FFN (Feed Forward Network)로 구성되어 있습니다. 이름에도 표현이 되었듯 NLP 분야에 사용되던 Attention 기반의 transfomer 기법이 Object detection 모델에 적용하려 하였습니다.
NLP 분야에 사용되던 transformer가 왜 Object detection에 사용되게 되었는지 살펴보겠습니다. Transformer는 사실 Sequnecial한 데이터가 나열되어 있을 때 그 데이터 사이의 관계를 파악하는 데 매우 효과적입니다.
이미지에서는 픽셀이 곧 데이터인데 각 픽셀이 Attention Score를 매기게 됩니다. 그 과정에서 픽셀들의 인스턴스가 분리됨과 동시에 인스턴스들은 상호작용을 통해 여러 값을 파악하고 우선순위를 매깁니다. 다시 말해 Attention을 통해 이미지 전체의 문맥 정보를 이해하는 데 사용이 된다고 보시면 됩니다.
하지만 DETR 성능은 기존 Object detection 모델들보다 높지는 않았습니다. EfficientDet의 50 AP에 비해 많이 부족하기도 했습니다. 그리고 단점으로 작은 Object에 대해서는 상대적으로 성능이 매우 낮았고 속도도 느렸죠.
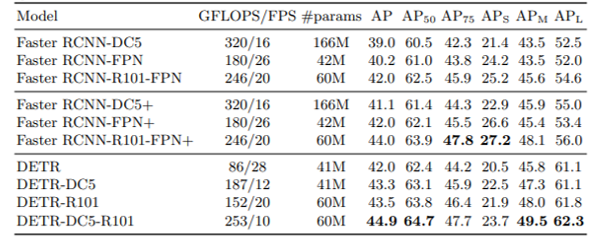
하지만 7개월 뒤인 2020년 10월에 Deformerable DETR을 발표합니다.
Deformable DETR: Deformable Transformers for End-to-End Object Detection
DETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. However, it suffers from slow convergence and limited feature spatial resolution, due to the limitation of Tra
arxiv.org
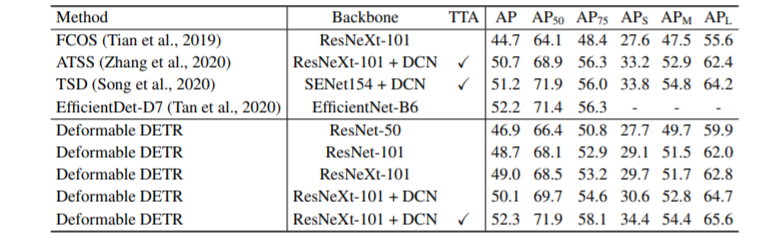
Doformable attention module을 이용하여 성능을 높이려 시도하였고 매우 뛰어난 것은 아니지만 EfficientDet보다 조금 좋아진 것을 볼 수 있습니다.
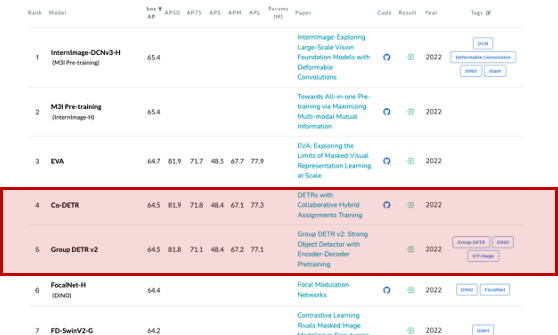
이후로 Transformer를 Object Detection에 접목하려는 연구가 활발해집니다. DETR은 후속 연구가 꾸준히 진행되며 Co-DERT, Group DETR, Group DETR v2 등으로 발전했습니다. (작성일 2022.12.13 기준으로 매우 높은 순위를 기록하고 있습니다)
5. Swin Transformer
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as
arxiv.org
2020년 하반기부터 CNN 계열의 Object detection 모델보다 Transformer 계열의 Object detection 모델 연구가 활발해집니다. 위에서 언급한 Deformable DETR이 Transformer를 적용한 Object detection 모델이고, Transformer를 적용한 Classification 모델로는 ViT 모델이 등장했는데 이 모델은 치명적인 단점이 있었습니다.
먼저 Fixed scale인데 ViT는 patch 단위로 이미지를 나누게 되는데 문제는 이 patch의 크기가 항상 고정되어 있다는 것입니다. patch의 크기는 고정되어 있지만 Object의 크기는 고정되어 있지 않기 때문에 특정 크기의 Object는 잘 탐지하지만 다른 크기의 Object는 탐지하지 못하는 문제가 있었죠. 그리고 모델이 지나치게 크기 때문에 학습시키기 위해서 많은 양의 데이터가 필요하기도 했고 이미지의 해상도, Pixel이 늘어나면 늘어날수록 모든 patch 개수도 증가하여 조합이 선형적으로 증가하는 것이 아니라 제곱에 비례하여 증가하여 모든 self-attention을 수행하는 것이 불가능하다는 단점이 있었습니다.
Swin Transformer는 ViT의 이러한 문제를 해결하기 다음과 같은 방법을 제시합니다. 첫 번째는 hierarchical feature map입니다. patch 크기를 항상 고정하지 않고 layer마다 patch의 크기를 다양하게 할 수 있게 합니다. 두 번째는 특정 영역끼리만 self-attention을 수행하도록 하여 이미지 크기에 따른 연산 수를 줄일 수 있습니다.


그리고 2021년 3월에 58 AP를 기록하면서 Object detection SOTA 모델로 등극합니다.
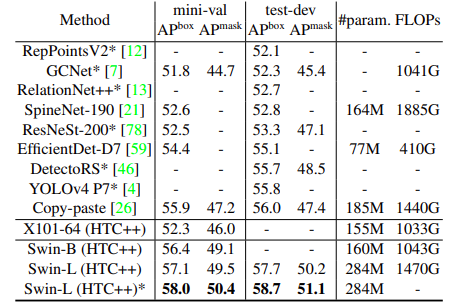
이후 나오는 Swin Transformer v2는 더 큰 모델, 고해상도의 이미지에서 안정적으로 학습할 수 있도록 개선이 되었고 62.5 AP를 기록하며 Object detection 모델도 60 AP를 넘길 수 있다는 것을 보여줍니다.
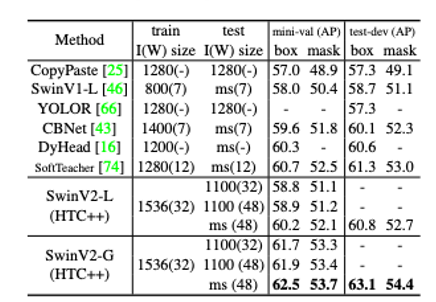
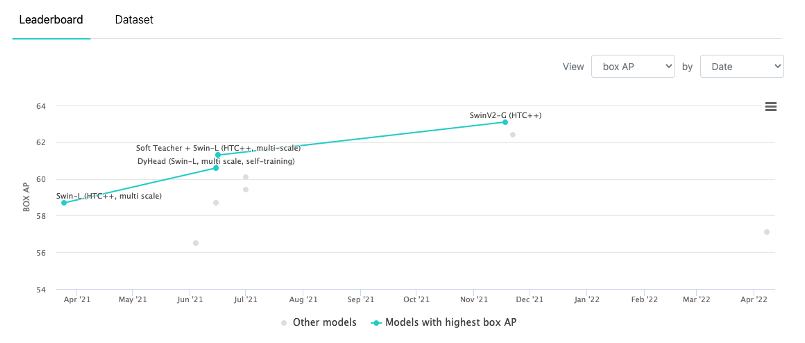
하지만 제가 가지고 있는 Dataset을 학습하였을 때는 그리 높은 성능(중복 검출)은 아녔습니다. 아무래도 Data의 양이 적어서 그런 것 같습니다. Data의 양이 충분하다면 좋은 결과가 나올 것 같습니다.

6. Soft Teacher + Swin-L
End-to-End Semi-Supervised Object Detection with Soft Teacher
This paper presents an end-to-end semi-supervised object detection approach, in contrast to previous more complex multi-stage methods. The end-to-end training gradually improves pseudo label qualities during the curriculum, and the more and more accurate p
arxiv.org
Deep Learning 모델이 우수한 성능을 내기 위해서는 많은 양의 라벨링 된 데이터(Labeled data)가 필요합니다. 지금까지 위에서 설명해 드린 모델들도 Microsoft COCO dataset(330K 이미지, 80개 카테고리)이나 Imagenet(14M 이미지, 22K 카테고리), MNIST (70K 이미지, 10 카테고리) 등과 같이 Public Dataset을 바탕으로 자신의 알고리즘 모델이 얼마나 뛰어난지 증명하는 연구 활동이라고 보시면 됩니다.
하지만 실제 현실의 문제에서는 많은 양의 라벨링 된 데이터를 확보하는 것은 어려움이 따릅니다. 예를 들면 의료 데이터의 경우 의사나 전문가에 의존하여 데이터를 생성해야 하고 자율주행을 위해 지도나 사진과 같이 복잡한 이미지에서 경계선을 라벨링 한다면 해결하고자 하는 문제의 복잡성만큼 라벨링 작업의 난이도도 증가하게 하면서 시간과 비용이 많이 소요되게 됩니다.
이러한 문제를 해결하기 위해 Transfer Learning, Meta Learning, Weakly-Supervised Learning, Self-Supervised Learning, Semi-Supervised Learning 등을 적용한 다양한 방식의 연구들이 시도되게 되는데 Soft Teachers는 이 중 Semi-Supervised Learning을 이용한 방식입니다.

데이타의 부족 문제를 Unlabed Data를 이용하여 해결하겠다는 점에서 Self-Supervised Learning과 유사하지만 Self-Supervised Learning은 기존 데이타를 가공하여 학습이 가능한 새로운 형태로 만들어 supervised-learning을 하는 것이고 Semi-Supervised Learning은 적은 양의 Labeled data로 supervised-learning을 한 후, 해당 모델로 하여금 Unlabeled data의 label을 예측합니다. 이렇게 예측한 값을 pseudo-label이라고 부르고, downstream task 학습시에는 모든 데이터셋을 labeled data로 간주하고 사용하여 학습을 진행하는 것입니다.
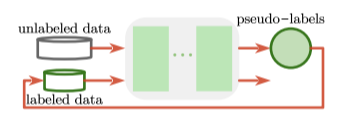
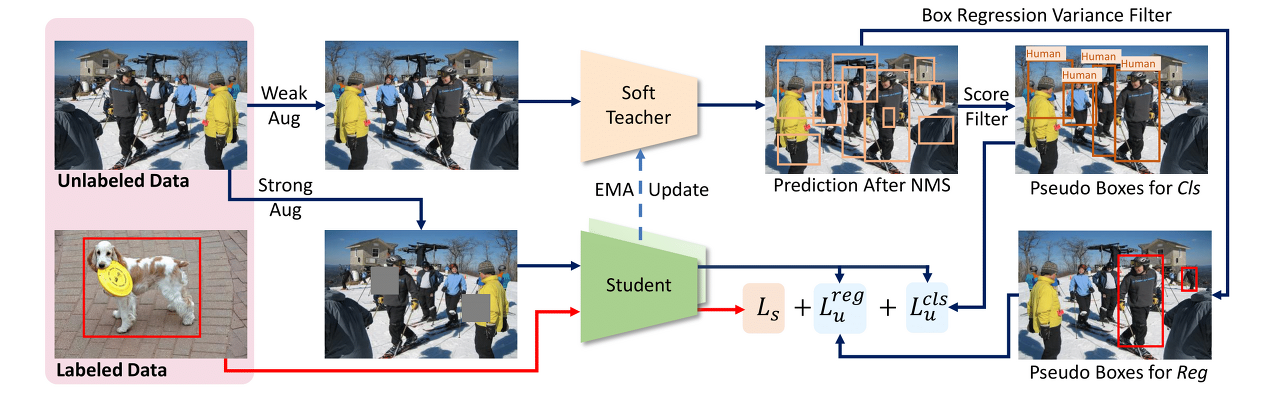
사실 Semi-Supervised Learning은 데이터의 부족으로 인한 문제를 Unlabeled Data를 사용하여 일반화 성능을 높이는 것이 목표지만 Supervised Learning 모델보다 성능이 낮았던 게 사실입니다.
하지만 Soft Teacher + Swin-L 모델이 60.4 AP를 보여주며 COCO Object detection benchmark에서 처음으로 60 AP 고지를 넘깁니다.
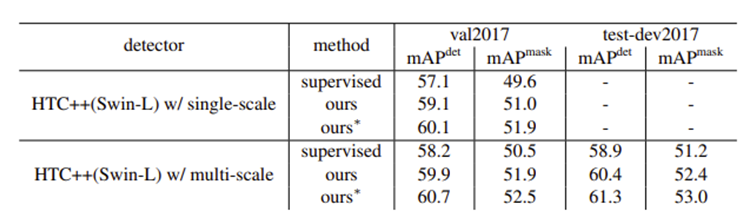
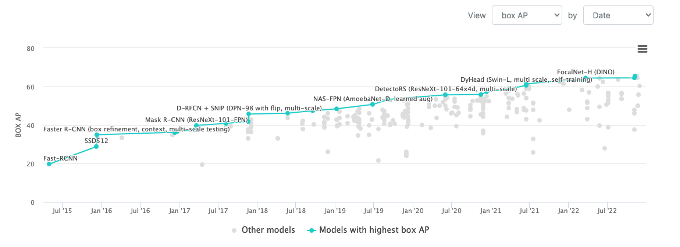
현재는 단순히 Public Dataset을 바탕으로 하는 Benchmark를 넘어서 현실 세계의 문제를 해결하기 위한 방법으로 많은 연구가 진행되고 있는 것 같습니다. 연산 속도, 이미지의 크기, 데이터의 부족 문제 등의 주제로 다양한 연구가 진행됨과 동시에 서로 영향을 주며 빠르게 발전되고 있는 것 같습니다.
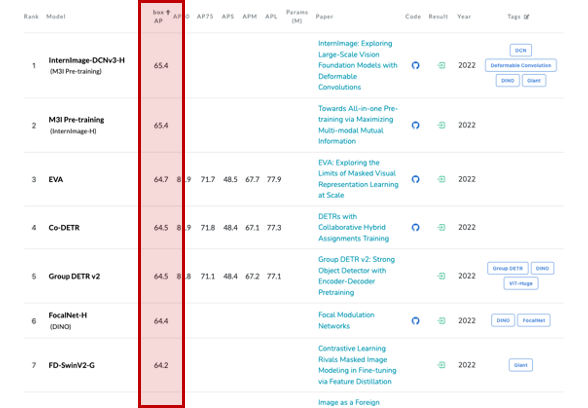
2022년 12월 13일 기준으로 65 AP를 돌파했으며 곧 80 AP를 넘기는 모델도 나오지 않을까 싶습니다.
'Tech & Development > AI' 카테고리의 다른 글
| [ Python ] 미디어파이프(Mediapipe)를 이용한 가상 마우스 (4) | 2023.01.31 |
|---|---|
| Fine tuning GPT3 Model (0) | 2023.01.04 |
| [ Python ] Object Detection using MobileNet SSD (D/L) (0) | 2022.11.29 |
| [ Python ] Color Detection using XGBoost (M/L) (0) | 2022.11.28 |
| [ Python ] Template Match Detection (0) | 2022.11.25 |
댓글을 사용할 수 없습니다.