YOLOv5 - Custom Data로 학습하기
Object Detection이란?
Classification 과 Localization 이 동시에 수행되는 것을 의미합니다. 즉 이미지에서 찾고자 하는 객체의 위치를 찾아내고 찾은 객체의 인스턴스(사람, 자동차, 동물 등)를 분류하는 일을 의미합니다. Object detection은 현재 수많은 컴퓨터 비전 분야에서 응용되고 있습니다.

사실 Object detection에 대한 연구는 Deep Learning이 유형을 끌기 훨씬 전부터 진행되고 있었습니다. 이전 글에서 소개한 Haar Cascades 를 이용한 얼굴 인식방법이나 HOG, SURF, DPM 등도 Deep Learning을 적용하기 이전 기술입니다.
2014년 이후에는 Object detection에 대한 논문이 쏟아져 나오고 있으며, 상당히 가시적인 성과가 있는 연구도 많습니다.
이 글에서는 선택한 이미지 데이터 세트로 YOLOv5 Object Detection 모델을 훈련하는 방법을 설명 드리겠습니다. YOLOv5는 YOLOv4에 비해 더 쉽게 환경을 구성하고 구현 할 수 있습니다.
YOLO는 You Only Look Once의 약자이며 실시간 Object detection 프레임워크입니다.
2020년 4월 23일 YOLOv4가 출시되었습니다. 그리고 YOLOv5는 같은 해인 2020년 6월 10일에 출시되었죠. 무려 두달도 채 되지 않는 기간이니 기술이 얼마나 빨리 발전하고 있는지 놀랍기도 합니다. 물론 YOLOv4 (Alexey Bochkovskiy)와 YOLOv5 (Glenn Jocher)의 연구개발자는 다릅니다. 그리고 YOLOv5는 YOLO가 아니라는 논란이 있기는 합니다. 매우 잘구현되었고 최신의 기법이 적용되었지만 기존의 YOLO가 가진 색을 많이 잃어버렸다는 평이 있기때문에 굳히 YOLO라 이름을 붙이는 것에 대한 갑론을박입니다. 그리고 아직 논문도 공개되지 않았죠.
YOLO는 다른 Object detection 모델에 비해 정확도 측면에서 부족하지만 속도 측면에서는 압도적입니다.
1. Download dataset
먼저 데이타셋이 필요하지만, 단기간에 데이타셋을 만드는 것은 어렵기 때문에 Roboflow 에서 데이타셋을 구해서 모델을 훈련하도록 하겠습니다.
저는 마스크 착용 데이타 세트를 활용하도록 하겠습니다. 이 이미지 데이타 세트는 대만 Eden Social Welfare Foundation의 Cheng Hsun Teng이 수집했다고 설명되어 있네요.

Download를 위해서 Images를 클릭합니다.
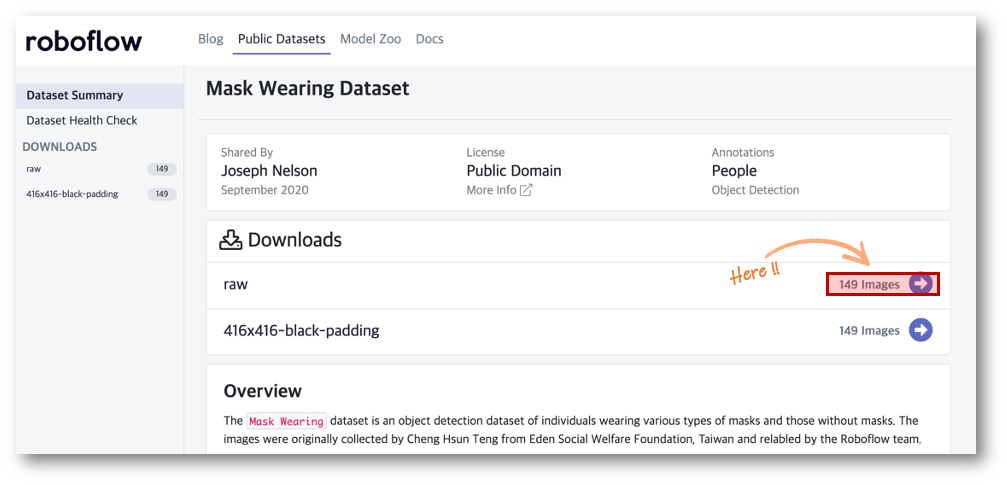
Download Format을 지정 할 수 있는데, COCO, Pascal VOC 등 다양한 Format의 형태로 Export 할 수 있는데 YOLOv5 PyTorch를 선택합니다.
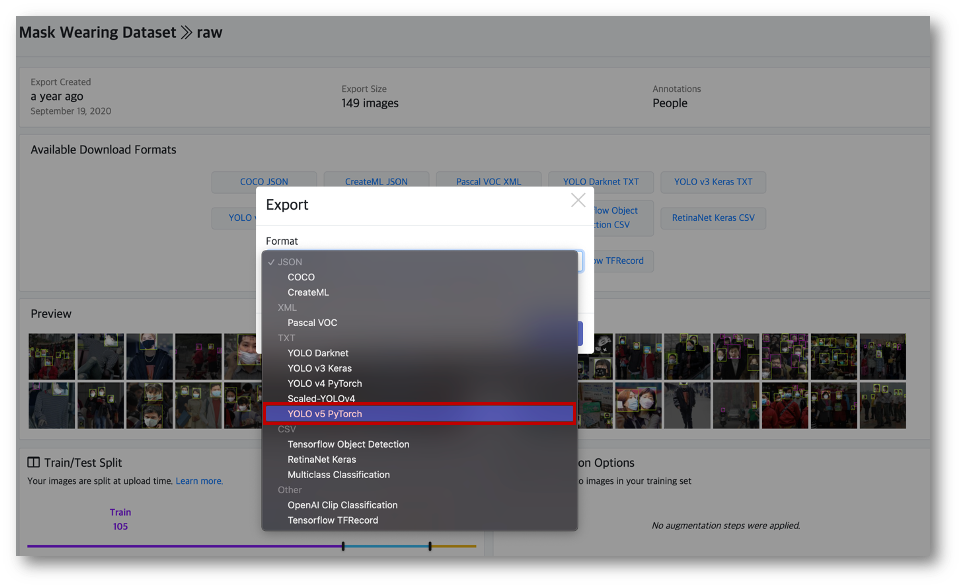
이미지 파일을 zip파일로 Local에 Download하거나 Download code를 생성 할 수 있는데, 저는 Colab에서 수행 할 예정이기때문에 Download code를 생성하여 복사합니다.

Colab의 런타임 유형은 GPU로 선택합니다. (런타임 > 런타임 유형 변경 > 하드웨어 가속기 GPU로 번경 > 저장) 위에서 복사한 Download code를 Colab에 붙여넣고 코드를 수행하여 Download를 진행합니다.
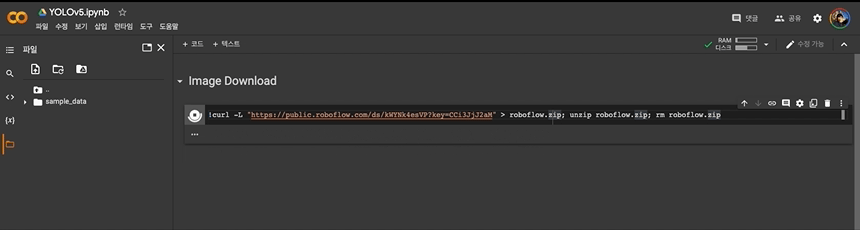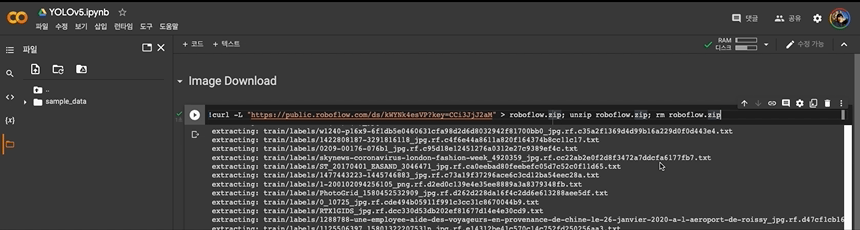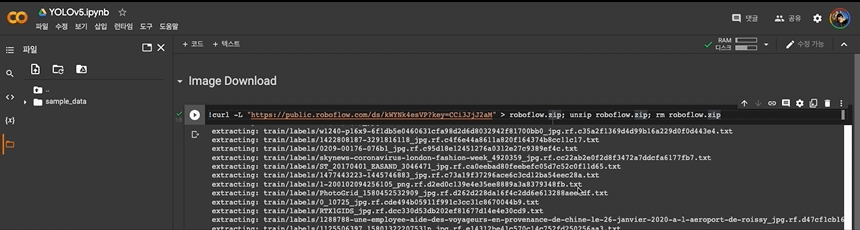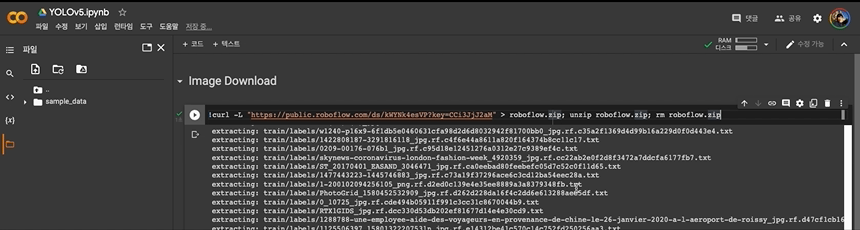
Download가 완료되면 왼쪽 파일과 디렉토리가 생성된 것을 확인 하실 수 있습니다.
2. Split Data
훈련과 검증, 테스트를 위해서 데이타세트를 나눠야 합니다. 하지만 roboflow에서 제공하는 데이타는 이미 나누어져 있기때문에 Skip하도록 하겠습니다.
content └───train │ ├── images │ │ ├── img_000001.jpg │ │ ├── img_000002.jpg │ │ ├── ...jpg │ │ └── ...jpg │ │ │ ├── labels │ │ ├── img_000001.txt │ │ ├── img_000002.txt │ │ ├── ...txt │ │ └── ...txt │ │ └───test │ ├── images │ │ ├── img_000072.jpg │ │ ├── img_000073.jpg │ │ ├── ...jpg │ │ └── ...jpg │ │ │ ├── labels │ │ ├── img_000072.txt │ │ ├── img_000073.txt │ │ ├── ...txt │ │ └── ...txt │ │ └───valid │ ├── images │ │ ├── img_000210.jpg │ │ ├── img_000211.jpg │ │ ├── ...jpg │ │ └── ...jpg │ │ │ ├── labels │ │ ├── img_000210.txt │ │ ├── img_000211.txt │ │ ├── ...txt │ │ └── ...txt └── data.yaml
- train set : 학습에 사용되는 훈련용 데이터
- valid set : 모델의 일반화 능력을 높이기 위해 학습 중에 평가에 사용되는 검증 데이터
- test set : 학습 후에 모델의 성능을 평가하기 위해서만 사용되는 테스트용 데이터
만약 데이타세트가 나눠야 한다면 splitfolders 라이브러리를 이용하여 데이타세트를 나눕니다.
다른 방식으로도 train, val, test 데이타세트를 나눌 수도 있지만 (ex.txt파일로 나누어 보관) 간혹 데이타세트가 섞이면 성능체크나 과적합이 발생 할 수 있으니 물리적으로 분할하고 시작하는 것이 좋다고 생각합니다.
예시)
import splitfolders splitfolders.ratio("data", output="dataset", seed=1337, ratio=(.8, .1, .1), group_prefix=None)
3. Label
label format은 다음과 같습니다. (roboflow에서 제공하는 데이타에는 label 파일이 존재하기때문에 별도 labeling은 필요 없습니다.)
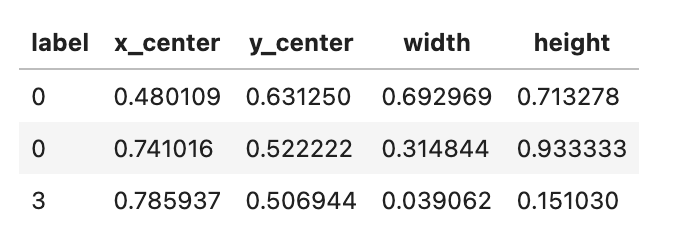
label 파일은 멀티클래스 형태로 구성할 수 있으며 여러 클래스 정보가 있을 때는 줄 단위로 구분해서 입력하면 됩니다. 각 줄은 label, 중심 X좌표, 중심 Y좌표, 너비, 높이 순서로 공백으로 구분해서 정보를 입력하며 좌표와 너비는 0~1 사이의 범위로 입력하면 됩니다.

4. Insatlling the YOLOv5 Environment
현재 colab에서 수행주이라면 %pwd 를 입력하여 현재 경로를 확인합니다. 저는 content 하위에 yolov5라는 폴더를 만들어서 진행 합니다.
%pwdimport os if not os.path.exists('content/yolov5'): !git clone https://github.com/ultralytics/yolov5 %cd yolov5 !pip install -r requirements.txt # install dependencies
5. Make yaml
함께 Download 된 data.yaml 파일을 살펴보면 아래와 같이 되어 있습니다. 만약 파일이 없는 경우 yolov5/data/coco.yaml 파일을 복사하여 수정을 진행합니다. 훈련, 검증 데이타 경로와 class정보의 수정이 필요하다면 yaml 파일을 열어서 수정합니다.
%cat /content/data.yaml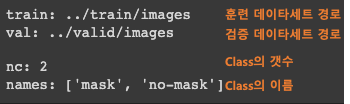
data.yaml 수정 예시
import yaml with open('detection_data/data.yaml', 'r') as f: data = yaml.load(f) print(data) data['train'] = 'detection_data/train.txt' data['val'] = 'detection_data/val.txt' with open('detection_data/data.yaml', 'w') as f: yaml.dump(data, f)
6. Train YOLOv5
Pretrained Checkpoints
| Model | size (pixels) |
mAPval 0.5:0.95 |
mAPval 0.5 |
Speed CPU b1 (ms) |
Speed V100 b1 (ms) |
Speed V100 b32 (ms) |
params (M) |
FLOPs @640 (B) |
| YOLOv5n | 640 | 28.4 | 46.0 | 45 | 6.3 | 0.6 | 1.9 | 4.5 |
| YOLOv5s | 640 | 37.2 | 56.0 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| YOLOv5m | 640 | 45.2 | 63.9 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
| YOLOv5l | 640 | 48.8 | 67.2 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
| YOLOv5n6 | 1280 | 34.0 | 50.7 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
| YOLOv5s6 | 1280 | 44.5 | 63.0 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
| YOLOv5m6 | 1280 | 51.0 | 69.0 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
| YOLOv5l6 | 1280 | 53.6 | 71.6 | 1784 | 15.8 | 10.5 | 76.7 | 111.4 |
| YOLOv5x6 + TTA | 1280 1536 |
54.7 55.4 |
72.4 72.3 |
3136 - |
26.2 - |
19.4 - |
140.7 - |
209.8 - |
!python /content/yolov5/train.py --batch 16 --epochs 100 --data "/content/data.yaml" --cfg /content/yolov5/models/yolov5s.yaml --weights yolov5s.pt --name test_yolov5s_100 --device 0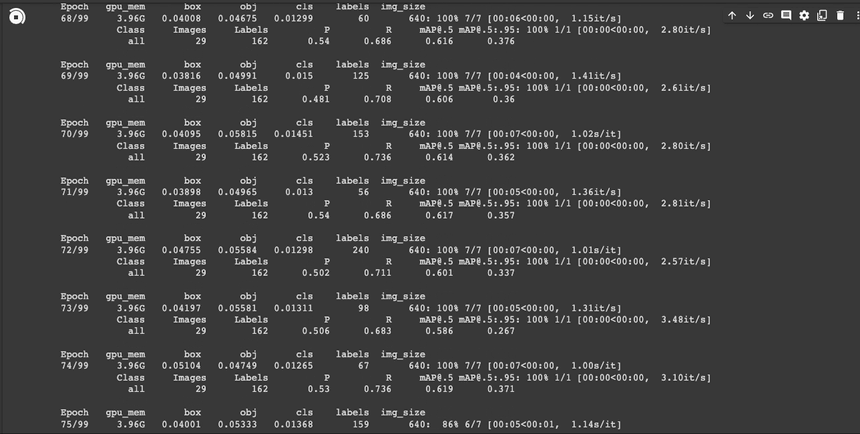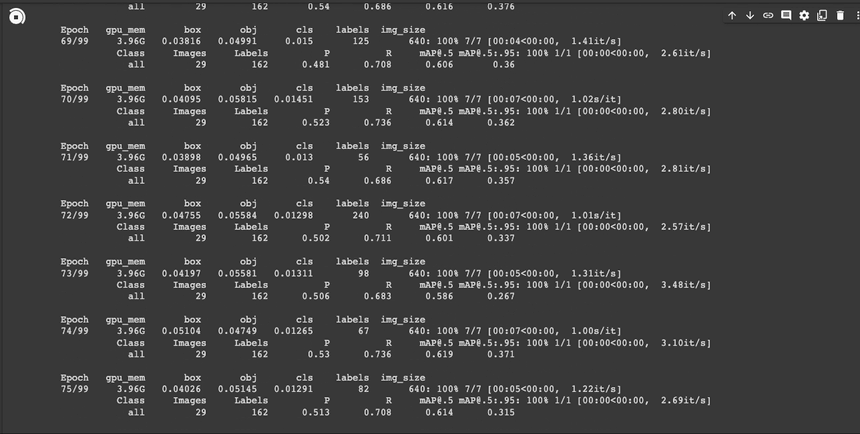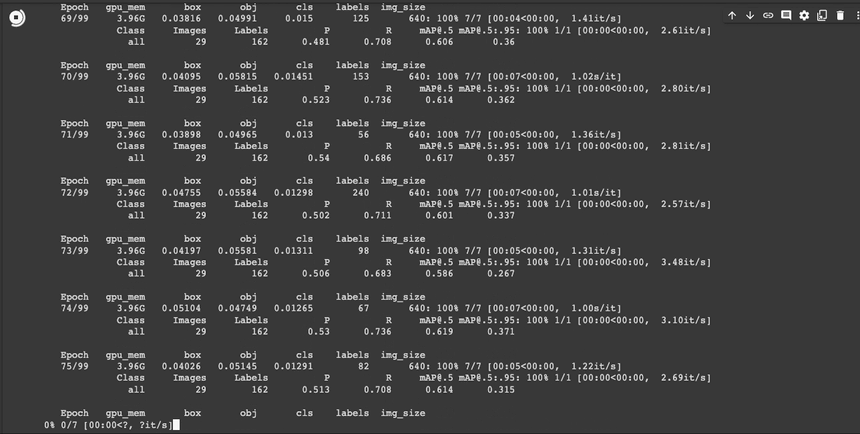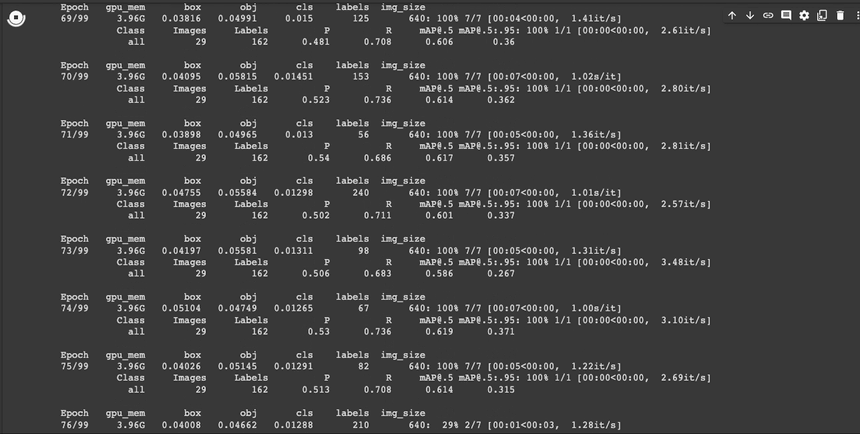
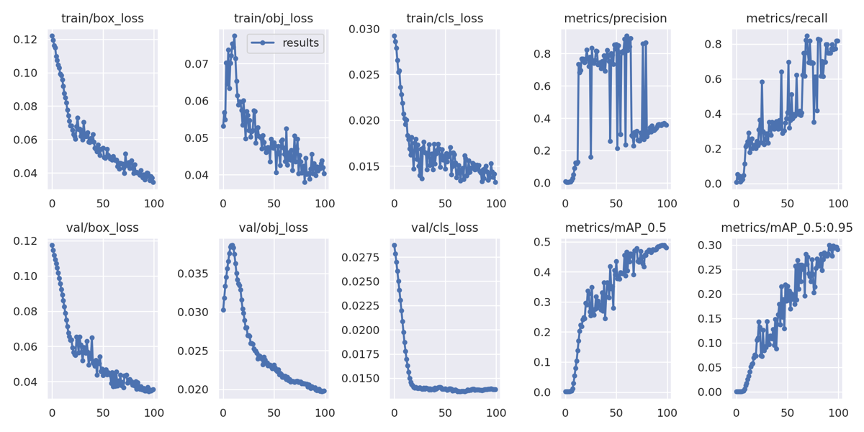
학습이 완료되었습니다. 일단 데이타 양이 부족했기때문에 성능 평가지표로 보았을 때에는 그리 좋지 않습니다.

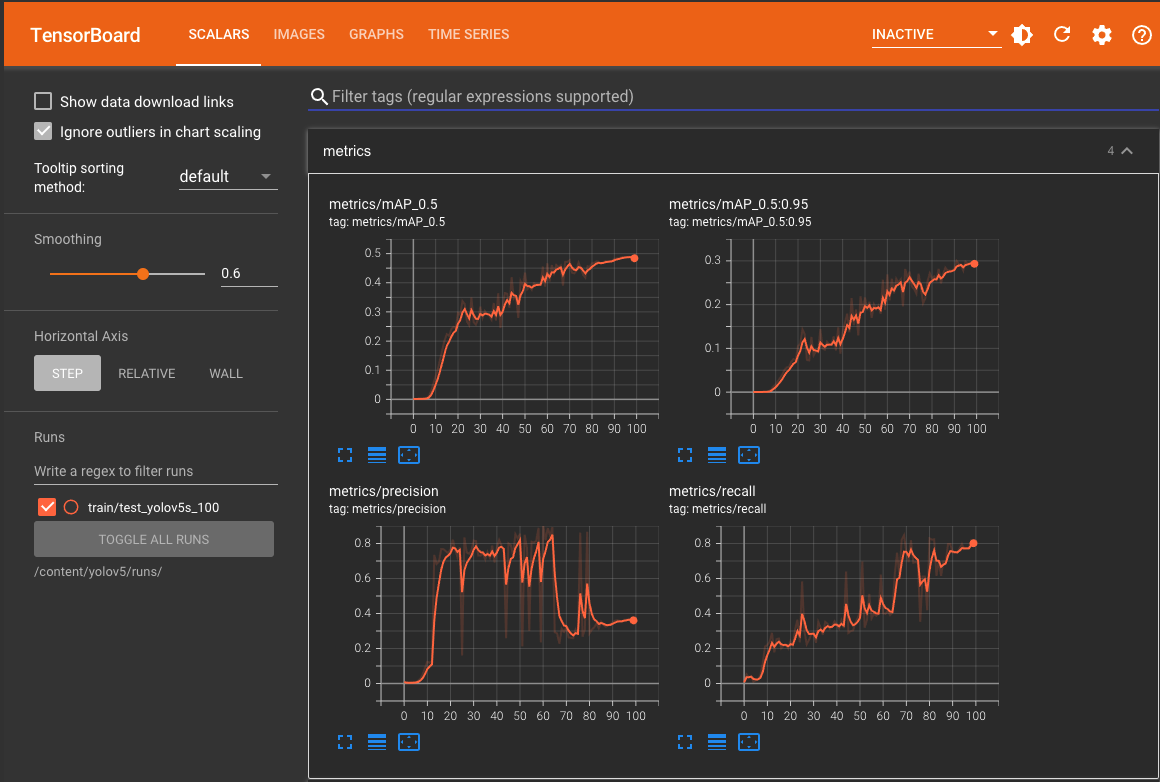
7. Performance evaluation
%load_ext tensorboard %tensorboard --logdir /content/yolov5/runs/
from IPython.display import Image from utils.plots import plot_results Image(filename='/content/yolov5/runs/train/test_yolov5s_100/results.png', width=1000)
ground truth data 를 확인합니다.
print("GROUND TRUTH TRAINING DATA:") Image(filename='/content/yolov5/runs/train/test_yolov5s_100/train_batch0.jpg', width=900)

8. Prediction
학습한 모델을 이용하여 실제 수행을 해보겠습니다. 수행하는 방법은 매우 간단합니다.
import glob val_img_list = glob.glob('/content/valid/images/*')
from IPython.display import Image import os val_img_path = val_img_list[21] !python detect.py --weights /content/yolov5/runs/train/test_yolov5s_100/weights/best.pt --img 416 --conf 0.5 --exist-ok --source "{val_img_path}" Image(os.path.join('/content/yolov5/runs/detect/exp', os.path.basename(val_img_path)))

9. Export Trained Weights
훈련된 weights를 google drive로 복사합니다.
from google.colab import drive drive.mount('/content/gdrive')
%cp /content/yolov5/runs/train/test_yolov5s_100/weights/best.pt /content/gdrive/My\ Drive'Tech & Development > AI' 카테고리의 다른 글
| CartoonGAN을 이용하여 일본 애니메이션 그림 만들기 (0) | 2022.03.15 |
|---|---|
| Object Detection Architecture - 1 or 2 stage detector (0) | 2022.02.16 |
| UGATIT (Selfie2Anime) - 사람을 애니메이션 캐릭터로 만들기 (0) | 2022.02.14 |
| Richer Convolutional Features (RCF) for Edge Detection - 윤곽선 검출 (1) | 2022.02.09 |
| Holistically-Nested Edge Detection (HED) - 윤곽선 검출 (0) | 2022.02.09 |
댓글을 사용할 수 없습니다.