YOLOv9 Custom Data 학습 가이드
LLM(Large Language Models) 모델의 등장 이전에는 머신러닝(ML) 영역에서 이미지 인식(Object Detection, Recognition, Object Tracking 등)이 크게 주목받았습니다. 그러나 LLM의 등장과 함께 많은 관심이 이 새로운 모델군으로 기울었고, 심지어는 멀티모달 모델도 등장하여 이미지 처리 분야에서도 높은 성능을 보이기 시작했습니다. 하지만, 실제 테스트를 해보면 Object Detection 같은 정밀한 측정이 필요한 영역에서는 이러한 모델들이 한계를 보이는 경우가 많습니다.
Object Detection 분야에는 다양한 모델이 존재하지만, 오늘은 YOLO에 대해 이야기해보려 합니다.
Object Detection 정리 (History)
이미지 내에서 사물을 인식하는 방법에는 다양한 유형이 존재합니다. 그중 Object Detection에 대해 정리를 하려고 합니다. 먼저 내용은 개인적인 경험을 바탕으로 한 매우 주관적인 내용이라는 점
yunwoong.tistory.com
YOLO의 역사
먼저 간단히 YOLO의 역사에 대해 소개하려고 합니다. YOLOv 뒤에 나오는 숫자는 버전을 의미하지만, 모든 YOLO가 직접적인 연관성을 가진다는 의미는 아닙니다.
YOLO (You Only Look Once)는 Joseph Redmon에 의해 제안된 실시간 객체 탐지 알고리즘입니다. 2015년 처음 발표된 이후 지속적으로 발전해 왔죠. YOLO의 발전 과정을 간략히 정리해 보겠습니다.
- YOLOv1 (2015년 6월): 최초의 YOLO 모델로, 기존의 객체 탐지 알고리즘과 달리 이미지를 그리드로 분할하고 각 셀에서 바운딩 박스와 클래스 확률을 예측하는 방식을 사용했습니다. 실시간 탐지가 가능한 속도를 보여주었지만, 작은 객체에 대한 탐지 성능이 다소 떨어지는 한계가 있었습니다.
- YOLOv2 (2016년 12월): YOLOv1의 한계를 극복하기 위해 Batch Normalization, 높은 해상도 입력, anchor box 등의 기법을 도입했습니다. 이를 통해 탐지 정확도와 속도를 모두 개선할 수 있었죠.
- YOLOv3 (2018년 4월): YOLOv2에 더해 FPN (Feature Pyramid Network) 구조를 도입하여 다양한 크기의 객체를 효과적으로 탐지할 수 있게 되었습니다. 또한 더 깊은 네트워크 구조 (Darknet-53)를 사용하여 정확도를 높였습니다.
- YOLOv4 (2020년 4월): Alexey Bochkovskiy가 개발한 모델로, Bag-of-Freebies와 Bag-of-Specials 기법을 적용하여 속도와 정확도를 개선했습니다. CSPNet 구조와 Mosaic 데이터 증강 기법 등이 사용되었죠.
- YOLOv5 (2020년 6월): Glenn Jocher가 이끄는 Ultralytics 팀이 개발한 모델로, PyTorch 프레임워크를 사용하고 다양한 최신 기법을 적용했습니다. 하지만 YOLO라는 이름 사용과 공식 논문 부재로 논란이 있었습니다.
- YOLOv6 (2022년 1월): 경량화된 backbone 네트워크를 사용하여 모바일 환경에서도 좋은 성능을 보여주었습니다.
- YOLOv7 (2022년 7월): Transformer 구조를 도입하여 정확도를 크게 향상했습니다.
- YOLOv8 (2023년 1월): 다양한 컴퓨터 비전 task를 하나의 모델로 수행할 수 있는 통합 아키텍처를 제안했습니다.
- YOLOv9 (2024년 2월): Chien-Yao Wang, I-Hau Yeh, Hong-Yuan Mark Liao가 제안한 모델로, 딥러닝 모델의 정보 손실 문제를 해결하기 위해 Programmable Gradient Information (PGI)라는 새로운 개념을 도입했습니다. PGI는 목표 task에 필요한 완전한 입력 정보를 제공하여 신뢰할 수 있는 gradient 정보를 얻을 수 있게 해 줍니다. 또한 gradient path planning에 기반한 새로운 경량 네트워크 구조인 Generalized Efficient Layer Aggregation Network (GELAN)을 설계하였습니다. GELAN은 일반적인 convolution 연산만을 사용하면서도 depthwise convolution 기반의 최신 경량 모델보다 우수한 성능을 보여주었습니다. PGI는 경량 모델부터 대형 모델까지 다양하게 적용될 수 있으며, 완전한 정보를 활용할 수 있어 대규모 데이터셋으로 사전 학습된 최신 모델보다 좋은 결과를 달성할 수 있었습니다.
YOLO 모델들의 연구진을 정리해 보면 다음과 같습니다.
- YOLOv1 (2015): Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
- YOLOv2 (2016): Joseph Redmon, Ali Farhadi
- YOLOv3 (2018): Joseph Redmon, Ali Farhadi
- YOLOv4 (2020): Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao
- Scaled-YOLOv4 (2021): Chien-Yao Wang, Alexey Bochkovskiy, Hong-Yuan Mark Liao
- YOLOv5 (2020): Glenn Jocher, Sergiuwaxmann (Ultralytics 팀)
- YOLOv6 (2022): Chuyi Li, Lulu Li, Yifei Geng, Hongliang Jiang, Meng Cheng, Bo Zhang, Zaidan Ke, Xiaoming Xu, Xiangxiang Chu
- YOLOv7 (2022): Chien-Yao Wang, Alexey Bochkovskiy, Hong-Yuan Mark Liao
- YOLOR (2022): Chien-Yao Wang, I-Hau Yeh, Hong-Yuan Mark Liao
- YOLOv8 (2023): Glenn Jocher, AyushExel (Ultralytics 팀)
- YOLOv9 (2024): Chien-Yao Wang, I-Hau Yeh, Hong-Yuan Mark Liao
이를 바탕으로 연구진 간의 협력 관계를 살펴보면, Chien-Yao Wang과 Hong-Yuan Mark Liao는 YOLOv4, Scaled-YOLOv4, YOLOv7, YOLOR, YOLOv9에서 꾸준히 협력해 왔습니다. Alexey Bochkovskiy는 YOLOv4, Scaled-YOLOv4, YOLOv7에서 Chien-Yao Wang, Hong-Yuan Mark Liao와 함께 연구했습니다. Joseph Redmon과 Ali Farhadi는 YOLOv1부터 YOLOv3까지 공동 연구를 진행했습니다. Glenn Jocher는 Ultralytics 팀을 이끌며 YOLOv5와 YOLOv8을 개발했습니다. 이처럼 YOLO 알고리즘은 다양한 연구진들의 협력과 노력으로 지속적인 발전을 이루어왔습니다. 특히 Chien-Yao Wang, Hong-Yuan Mark Liao, Alexey Bochkovskiy 등은 여러 모델에 걸쳐 협업하며 YOLO 시리즈의 진화를 주도해 왔죠. 한편, Joseph Redmon, Glenn Jocher 등은 각자의 팀을 이끌며 독자적인 모델을 개발해 온 것으로 보입니다. 이렇게 서로 다른 배경과 아이디어를 가진 연구자들의 협력과 경쟁이 YOLO 알고리즘의 발전을 이끌어 왔다고 할 수 있겠습니다.
이렇게 YOLO 시리즈는 여러 연구진에 의해 다양한 방향으로 발전해 나가고 있습니다. 각자의 아이디어와 기술을 바탕으로 객체 탐지의 정확도와 효율성을 높이기 위해 노력하고 있죠. 앞으로도 YOLO 알고리즘이 어떤 모습으로 진화해 나갈지 주목됩니다.
YOLOv9 소개
이전 글에서는 YOLOv5를 기준으로 정리한 바 있으나, YOLOv9에서 어떠한 진전이 있었는지 살펴보고자 합니다.
PGI 기술은 경량 모델부터 대형 모델에 이르기까지 다양한 모델에 적용될 수 있으며, 완전한 정보를 활용함으로써 대규모 데이터셋으로 사전 학습된 최신 모델보다 더 좋은 결과를 달성할 수 있었습니다. YOLOv9는 MS COCO 데이터셋에서의 Object Detection 성능을 검증했으며, 그 비교 결과는 아래와 같습니다.

딥 러닝 모델은 데이터가 네트워크의 깊은 층을 지날수록 중요한 정보를 잃어버릴 수 있다는 근본적인 한계를 갖고 있는데, 이를 정보 병목 현상이라고 합니다. 특히 모바일 기기 등에 적용되는 경량 모델의 경우 제한된 파라미터로 인해 이런 문제가 더욱 두드러지곤 합니다.
YOLOv9은 이 문제를 정면으로 해결하기 위해 두 가지 핵심 아이디어를 도입했습니다. 바로 프로그래밍 가능한 그래디언트 정보(PGI)와 일반화된 효율적인 계층 집계 네트워크(GELAN)인데요, 이 둘이 어떻게 정보 손실을 막고 탐지 성능을 끌어올리는지 하나씩 살펴보겠습니다.
PGI는 딥 러닝 모델의 학습 과정에서 중요한 역할을 하는 그래디언트에 착안한 기술입니다. 각 층에서 필요한 정보를 선택적으로 보존하고 안정적인 그래디언트를 생성함으로써, 모델이 효과적으로 학습할 수 있게 돕습니다. 예를 들어 "사과를 찾아라!"라는 문제를 풀 때, 사과의 색이나 모양 같은 핵심 정보를 잃어버리지 않고 끝까지 전달할 수 있게 되는 셈입니다.
또한 YOLOv9은 GELAN이라는 유연한 네트워크 구조를 통해 다양한 연산 블록을 최적으로 조합하고 파라미터를 효율적으로 활용합니다. 이렇게 하면 모델의 크기를 줄이면서도 정확도를 높일 수 있습니다.

이렇게 PGI와 GELAN은 손잡고 YOLOv9이 작지만 강력한 모델로 거듭나는 데 큰 역할을 합니다. 게다가 YOLOv9은 리버서블 함수라는 개념도 활용하는데요. 이는 정보의 손실 없이 원래 상태로 되돌릴 수 있는 변환을 의미합니다. 이런 함수를 사용하면 데이터가 네트워크를 지나면서 중요한 정보를 잃어버리는 일을 막을 수 있습니다.
YOLOv9 - Custom Data로 학습하기
YOLOv9은 강력한 객체 탐지 알고리즘이지만, 실제로 활용하기 위해서는 자신만의 데이터셋으로 모델을 학습시켜야 합니다. 이번 글에서는 Google Colab과 Roboflow를 이용하여 YOLOv9를 커스텀 데이터셋으로 학습하는 방법을 소개하겠습니다.
#1. 데이터 준비하기
데이터 수집은 프로젝트의 성공에 매우 중요한 첫 단계입니다. 과거에는 데이터의 양과 다양성을 확보하기 위해 직접 이미지를 수집하고 레이블링 하는 과정이 필요했습니다. 이 과정은 객체의 위치와 클래스를 정확하게 표시하는 데 중요합니다. 하지만 이번 프로젝트에서는 시간과 노력을 절약하기 위해 Roboflow에서 제공하는 준비된 데이터셋을 활용할 예정입니다.
Roboflow: Give your software the power to see objects in images and video
Everything you need to build and deploy computer vision models.
roboflow.com
Roboflow에서 학습 데이터를 찾는 방법을 안내해 드리겠습니다. 최근 방법이 조금 변경되었습니다. Roboflow 웹사이트로 이동한 후, 상단 메뉴에서 'Product'를 찾아 그 아래에 위치한 'Universe'를 선택하면 됩니다.

Universe 페이지에 접속하면, 화면 중앙의 "Explore Universe" 버튼을 클릭하여 'Explore the Roboflow Universe' 페이지로 이동할 수 있습니다. 이곳은 오픈 소스 컴퓨터 비전 데이터셋 및 API 안내를 위한 공간입니다.

만약 Roboflow에 아직 가입하지 않았다면, "Create Account" 버튼을 클릭하여 가입 과정을 진행할 수 있습니다. GitHub이나 Google 계정을 사용하여 간편하게 가입할 수 있습니다. 이미 계정이 있는 경우에는 "Sign In"을 클릭하여 로그인하세요.
프로젝트 타입(예: Classification, Object Detection 등), 모델 종류, 카테고리별로 데이터셋을 검색할 수 있습니다.
저는 위성 지도에서 호수를 검출하는 모델을 만들 계획입니다. (작년에 환경부 관련 담당자분들을 만났을 때, AI를 활용할 필요성에 대해 얘기를 나눴습니다. 그때 위성 지도상의 농경지나 호수 같은 요소들을 라벨링하는 작업의 중요성을 알게 되었고, 이번엔 그 아이디어를 바탕으로 이 모델을 만들어보기로 했습니다.)

선택한 데이터셋에 대해 "Download this Dataset" 버튼을 클릭합니다. 나타나는 Export 팝업에서 "Format"으로 "YOLOv9"를 선택하고, Colab에서 직접 다운로드하여 사용할 계획이므로 "show download code"를 선택한 뒤, "Continue" 버튼을 클릭합니다.
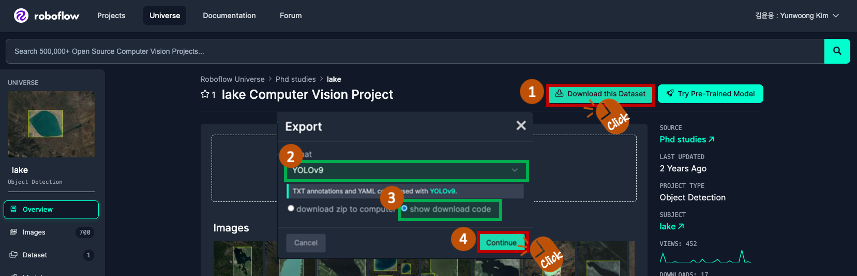
Roboflow는 데이터셋을 다운로드할 수 있는 세 가지 방법을 제공합니다: Roboflow 라이브러리를 사용하는 방법, 터미널에서 curl을 사용하는 방법, 그리고 직접 URL을 통해 다운로드하는 방법입니다. 저는 터미널을 사용하여 데이터를 다운로드하기로 결정했습니다. 'Terminal' 탭을 선택하면 다운로드에 필요한 코드가 표시됩니다. 우측에 있는 복사 버튼을 클릭하여 코드를 복사할 수 있습니다.

#2. Colab에서 학습하기
Google Colaboratory
colab.research.google.com
이제 Google Colab으로 넘어가겠습니다. Colab에서 런타임 유형을 GPU로 설정하세요. 설정 경로는 '런타임' 메뉴에서 '런타임 유형 변경'을 선택하고, '하드웨어 가속기' 옵션에서 GPU를 선택한 다음 '저장'합니다.
데이터셋 이미지 다운로드
이전 단계에서 복사한 다운로드 코드를 Colab에 붙여 넣어 실행하면 데이터셋 다운로드가 시작됩니다.
복사한 코드를 붙여 넣을 때 '>' 기호가 '>'로 표시되는 경우가 있습니다. 이 경우, '>'로 변경하여 코드를 실행하시면 됩니다. Download가 완료되면 왼쪽 파일과 디렉토리가 생성된 것을 확인하실 수 있습니다.

YOLOv9 환경 설치
YOLOv9 환경 설치는 YOLOv9의 공식 저장소를 이용하여 진행합니다.
!git clone https://github.com/SkalskiP/yolov9.git
%cd yolov9
!pip install -r requirements.txt -q
%cd ..
YAML 파일 설정
다운로드한 data.yaml 파일은 다음과 같이 구성되어 있습니다. 파일이 없을 경우, yolov9/data/coco.yaml 파일을 복사해 사용할 수 있습니다. 훈련 및 검증 데이터의 경로와 클래스 정보를 수정해야 할 경우, YAML 파일을 열어 해당 내용을 조정하세요. 현재는 별도로 수정할 사항이 없습니다. 단지, cat 명령어를 사용하여 해당 파일의 존재 여부만 확인하세요.

가중치 다운로드
YOLOv9 및 GELAN 모델의 가중치를 $HOME/weights 디렉토리에 다운로드합니다.
!wget -P "$HOME/weights" -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-c.pt
!wget -P "$HOME/weights" -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-e.pt
!wget -P "$HOME/weights" -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/gelan-c.pt
!wget -P "$HOME/weights" -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/gelan-e.ptYOLOv9 학습하기
YOLOv9 모델 학습을 시작하기 위해 아래 명령어를 실행합니다. 이 예에서는 25 에폭(epoch) 동안 학습을 진행합니다.
!python yolov9/train.py \
--batch 16 --epochs 25 --img 640 --device 0 --min-items 0 --close-mosaic 15 \
--data "$HOME"/data.yaml \
--weights "$HOME"/weights/gelan-c.pt \
--cfg yolov9/models/detect/gelan-c.yaml \
--hyp hyp.scratch-high.yaml
#3. 성능평가
학습이 완료된 후, 모델의 성능을 평가하기 위해서는 학습된 모델을 테스트 데이터셋에 적용하여 정확도, 정밀도, 재현율 등 다양한 지표를 통해 모델의 탐지 능력을 검증해야 합니다. YOLOv9 프레임워크는 학습 과정에서 자동으로 생성된 검증 데이터셋을 사용하여 성능 평가를 수행할 수 있는 기능을 제공합니다. 평가 과정을 통해 모델이 얼마나 정확하게 객체를 탐지하고 분류하는지 확인할 수 있으며, 필요한 경우 학습 파라미터를 조정하여 모델의 성능을 최적화할 수 있습니다.
# Start tensorboard
# Launch after you have started training
# logs save in the folder "runs"
%load_ext tensorboard
%tensorboard --logdir /content/yolov9/runs/
from IPython.display import Image
Image(filename=f"{HOME}/yolov9/runs/train/exp/results.png", width=1000)
실제 데이터(ground truth)를 확인합니다.
# first, display our ground truth data
print("GROUND TRUTH TRAINING DATA:")
Image(filename=f"{HOME}/yolov9/runs/train/exp/val_batch0_labels.jpg", width=900)예측된 데이터(Predicted Data)를 확인합니다.
print("PREDICTED DATA:")
Image(filename=f"{HOME}/yolov9/runs/train/exp/val_batch0_pred.jpg", width=900)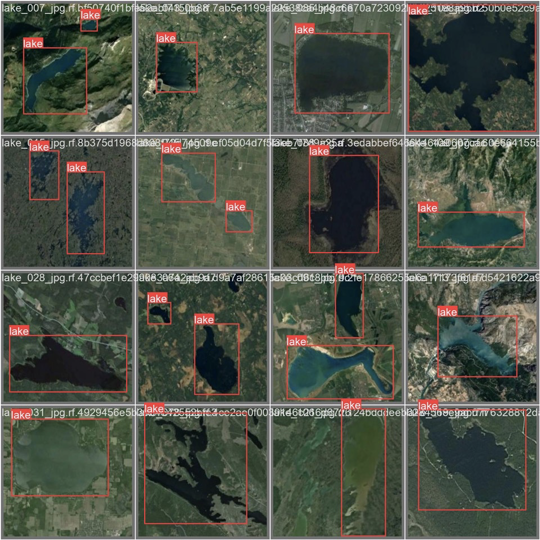

일부 오류가 있지만, 학습 기간이 짧았음을 고려해야 합니다.
#4. 예측
이제 학습된 모델을 사용하여 예측을 해보겠습니다.
from IPython.display import Image
import os
import glob
val_img_list = glob.glob(f"{HOME}/valid/images/*")
val_img_path = val_img_list[3]
!python yolov9/detect.py --weights "$HOME"/yolov9/runs/train/exp/weights/best.pt --img 640 --conf 0.5 --exist-ok --source "{val_img_path}"
Image(filename=f"{HOME}/yolov9/runs/detect/exp/"+os.path.basename(val_img_path), width=640)
#5. 훈련된 가중치 내보내기
훈련된 가중치를 Google Drive로 복사하여 저장합니다.
from google.colab import drive
drive.mount('/content/gdrive')
%cp "$HOME"/yolov9/runs/train/exp/weights/best.pt /content/gdrive/My\ Drive이번 글을 통해 YOLOv9 모델을 커스텀 데이터로 학습시키는 과정을 살펴보았습니다. 시작부터 데이터 준비, 환경 설정, 학습, 그리고 성능 평가에 이르기까지의 단계를 따라가며, 학습된 모델로 예측을 수행해 보고 마지막으로 훈련된 가중치를 저장하는 방법까지 알아보았습니다. Object Detection 모델의 지속적인 발전에 대한 기대감이 높아지고 있으며, 다양한 연구진들이 함께 협력하여 이 분야를 발전시켜 나가는 과정이 저는 매우 흥미롭습니다.
'Tech & Development > AI' 카테고리의 다른 글
| CodeGemma 활용 가이드: Gemma 기반의 코드 생성 모델 (4) | 2024.05.19 |
|---|---|
| 다양한 LLM을 이용한 웹 테스트 자동화 (LaVague) - Python (0) | 2024.03.23 |
| Claude 3 API 활용: Vision (OCR) - Python (25) | 2024.03.12 |
| Claude 3 API 활용: Vision (시각적 질문 응답) - Python (2) | 2024.03.12 |
| Claude 3 API: Python 기본 가이드 (39) | 2024.03.11 |