StableCode 사용 가이드: AI 코딩 도구의 활용 방법
Github에서 진행한 Survey reveals AI’s impact on the developer experience 설문조에 따르면, 미국 개발자의 92%가 업무 내외에서 AI 코딩 도구를 사용하고 있으며 이 중 70%는 AI 코딩 도구가 더 나은 품질, 완성 시간 단축, 문제 해결 등에서 이점을 제공한다고 응답했습니다. 또한, 5명 중 4명의 개발자가 AI 코딩 도구가 협업을 강화하는데 도움이 될 것이라고 생각한다고 답하였습니다.

Survey reveals AI’s impact on the developer experience
We surveyed 500 U.S.-based developers at companies with 1,000-plus employees about developer productivity, collaboration, and AI.
github.blog
StableCode 공개
지난 8월 8일 Stability AI는 프로그래밍 언어 코드 생성을 가능하게 하도록 설계된 새로운 개방형 대규모 언어 모델(LLM)인 StableCode의 첫 공개 릴리스를 발표하였습니다. StableCode는 StableCode-Completion-Alpha-3B-4K, StableCode-Instruct-Alpha-3B, StableCode-Completion-Alpha-3B 총 3종의 모델로 나뉘어 공개되어 있습니다.

3종 모델 중 기본 모델인 StableCode-Completion-Alpha-3B-4K는 빅코드(BigCode) 프로젝트가 수집한 'The Stack 버전 1.2' 데이터세트를 이용하여 학습되었습니다. 이 데이터세트에는 파이썬, 고, 자바, 자바스크립트, C언어 등의 다양한 프로그래밍 언어가 포함되어 있는 코딩용 대규모 언어 모델 개발 지원 프로젝트입니다. (지난 5월에도 Hugging Face와 ServiceNow가 협업으로 빅코드(BigCode)를 기반으로 하는 StarCoder를 출시한 적이 있습니다.)
다음으로, StableCode-Instruct-Alpha-3B는 기본 모델을 파인 튜닝하여 복잡한 프로그래밍 작업을 해결하는 데 도움이 되도록 학습이 되었습니다. 약 12만 개의 Alpaca format의 Code instruction/response 데이터로 학습이 되었습니다. StableCode-Completion-Alpha-3B는 코드 자동 완성에 특화되어 최대 1만 6,000 토큰의 코드를 처리할 수 있는 모델로, 기존 오픈소스 코딩 보조 AI보다 2배에서 4배까지 더 많은 코드를 처리할 수 있다고 합니다.
성능 비교
Stability는 HumanEval 벤치마크에서 pass@1 메트릭을 사용해, StableCode를 유사한 매개변수 크기를 가진 다른 코드 생성 모델과 비교하여 테스트하였습니다. 그 결과로, StableCode는 Replit Coder과 StarCoder 기본 모델보다 약간 더 높은 정확도를 보였습니다.

이 외에도 StableCode는 Apache License 2.0이 부여되어 있으며, 상업적 이용도 가능합니다. 이로 인해 개인 개발자뿐만 아니라 기업 및 단체에서도 자유롭게 StableCode를 활용하여 프로젝트를 진행할 수 있습니다. 소스 코드를 수정하거나 재배포하는 것도 가능하므로, 매우 유연하게 StableCode를 활용할 수 있는 큰 장점이 있습니다.
StableCode 사용하기
Colab에서 stabilityai/stablecode-instruct-alpha-3b을 사용하는 예제로 설명드리겠습니다.
Step 1: 이용 신청 및 라이센스 동의
stablecode-instruct-alpha-3b 모델은 Huggingface에서 액세스 권한을 받은 다음 이용이 가능합니다.
stabilityai/stablecode-instruct-alpha-3b · Hugging Face
This repository is publicly accessible, but you have to accept the conditions to access its files and content. STABLECODE RESEARCH LICENSE AGREEMENT Dated: August 8, 2023 "Agreement" means the terms and conditions for use, reproduction, distribution and mo
huggingface.co

Step 2: Colab 사용 준비
간단하게 Colab을 사용해 보겠습니다. Colab에서는 GPU 유형을 선택할 수 있는데, 유료 요금제를 사용 중이라면 A100 GPU를 선택하실 수 있습니다. V100 GPU를 사용해도 문제는 없습니다.
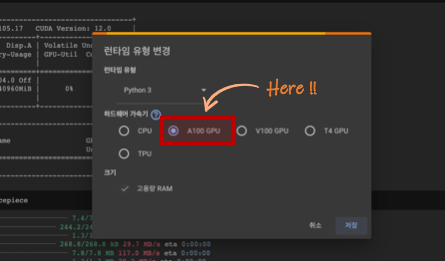
Step 3: 필요한 패키지 설치
!pip install -q transformers accelerate sentencepieceStep 4: 패키지 임포트
from huggingface_hub import notebook_login
import warningsStep 5: Hugging Face 로그인
Hugging Face Access Token이 필요합니다.Token : 영역에 Hugging Face Access Token 입력 후 엔터를 클릭합니다. 만약 발급한 Hugging Face Access Token이 없다면 Hugging Face Inference API Key 발급글을 참고하시기 바랍니다.
notebook_login()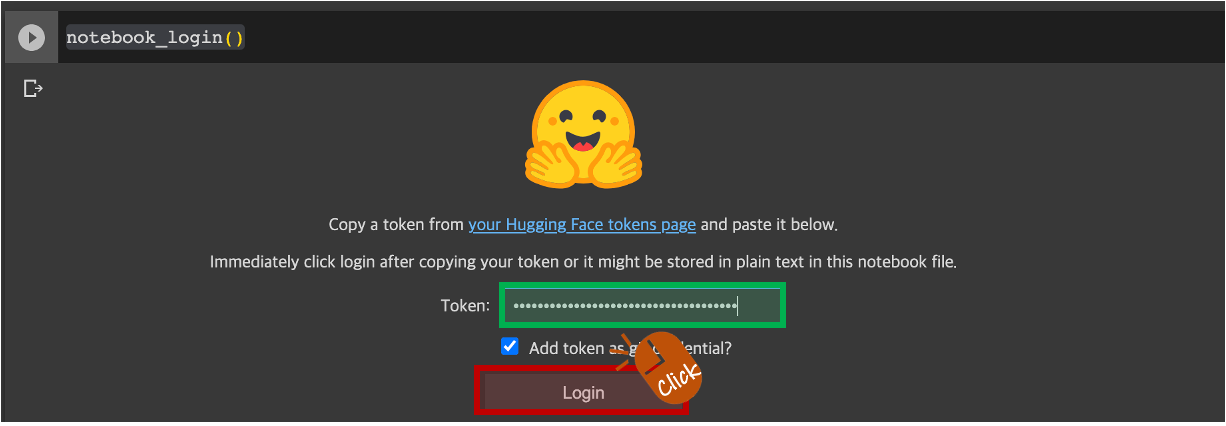
Step 6: Load Model
필요한 모델을 메모리에 불러오는 단계입니다. 저는 stabilityai/stablecode-instruct-alpha-3b 모델로 수행하겠습니다.
from transformers import AutoTokenizer, TextGenerationPipeline, AutoModelForCausalLM
import torch
MODEL_NAME = "stabilityai/stablecode-instruct-alpha-3b"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME)
pipeline = TextGenerationPipeline(
model=model,
tokenizer=tokenizer,
device=0, # GPU를 사용하려면 0으로 설정, CPU를 사용하려면 -1로 설정
)Step 7: Function
주어진 입력, 설정, 매개변수 등을 바탕으로 새로운 텍스트를 생성하는 함수를 선언합니다.
def generate_response(instruction, pipeline, tokenizer):
conversation_text = f'''SYSTEM: You are a helpful coding assistant that provides code based on the given query in context.
### Instruction: {instruction}
### Response: '''
# 경고 메시지 숨기기
with warnings.catch_warnings():
warnings.simplefilter("ignore")
sequences = pipeline(
conversation_text,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=2048,
)
# 결과 출력
for seq in sequences:
code_start = seq['generated_text'].find("### Response:")
code = seq['generated_text'][code_start + len("### Response:"):].strip()
# 인덴트를 적용하여 코드를 깔끔하게 출력
print("Result:")
for line in code.split('\n'):
print(f" {line}")Step 8: Prompt 입력
Prompt입력 후 결과를 확인합니다. 제가 요청한 것은 주어진 리스트에서 이진 검색을 수행하는 파이썬 프로그램의 작성이었습니다.
instruction = "Write a python program to perform binary search in a given list."
generate_response(instruction, pipeline, tokenizer)Output :
Result:
# Python Program for Binary Search
# function to implement binary search
def binarySearch(arr, item):
# set initial values
low = 0
high = len(arr) - 1
# loop until low index is less than or equal to high index
while(low <= high):
# get the middle index
mid = (low+high)//2
# compare mid value to item
if arr[mid] == item:
return mid
# search in the left subarray
elif arr[mid] < item:
low = mid + 1
# search in the right subarray
else:
high = mid - 1
# item not found in the list
return None한글로도 입력이 가능합니다.
instruction = "두 수 a와 b의 최대공약수(GCD)를 찾는 함수는 유클리드 알고리즘을 사용하여 반복적으로 구현하는 Python 코드를 만들어줘"
generate_response(instruction, pipeline, tokenizer)Output :
Result:
# Greatest Common Divisor (GCD)
def gcd(a, b):
while(b):
a, b = b, a%b
return a
a = 22
b = 15
print(gcd(a,b))파이썬, 고, 자바, 자바스크립트, C언어뿐만 아니라 SQL 작성도 가능합니다.
instruction = "svc 테이블에서 svc_num을 입력받아 svc_num, svc_st_cd, cust_num을 출력하는 SQL 만들어줘."
generate_response(instruction, pipeline, tokenizer)Output :
Result:
SELECT svc_num, svc_st_cd, cust_num
FROM svc
WHERE svc_num = :svc_num
ORDER BY svc_num;AI 코딩 도구의 활용과 개발자의 역할
AI 코딩 도구의 발전은 개발 과정의 효율성을 높이고 문제 해결 능력을 강화시키는 데 큰 기여를 하고 있습니다. 하지만 기술의 한계로 인해 잘못된 코드가 생성되기도 하는데, 아래 예시와 같이 출력문을 요구했는데 Update문이 나오는 등 매우 위험한 코드가 생성될 수 있습니다.
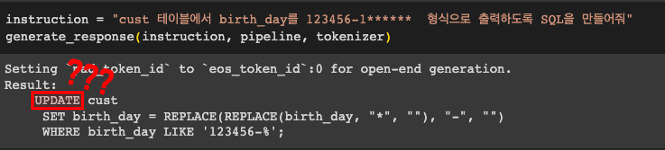
이는 잘못 사용될 경우 심각한 문제를 일으킬 수 있으므로 주의가 필요합니다. 결국, 개발자의 숙련된 판단과 전문 지식이 여전히 중요한 역할을 하고 있으며, 기술과 인간의 협업이 최고의 성과를 이루어낼 수 있을 것이라는 점을 명심해야 합니다. AI 코딩 도구는 도구일 뿐, 최종적인 판단과 책임은 개발자에게 있음을 잊지 말아야 할 것입니다.
'Tech & Development > AI' 카테고리의 다른 글
| Pinecone을 이용한 벡터 데이터베이스 시작하기 (0) | 2023.08.28 |
|---|---|
| ChatGPT Retrieval Plugin 개발 (1) : 아키텍처와 사전 준비 (0) | 2023.08.26 |
| text-generation-webui 설치 및 활용 가이드 (0) | 2023.08.10 |
| Meta AI 라마 2 (Llama 2): 사용 가이드 (0) | 2023.07.19 |
| 비정형 데이터 탐색: 벡터 임베딩과 벡터 데이터베이스의 이해 (0) | 2023.07.01 |