ChatGPT Retrieval Plugin 개발 (1) : 아키텍처와 사전 준비
인공지능과 머신러닝의 빠른 발전에 따라, 개인이나 기업이 보유한 대량의 데이터를 효율적으로 활용하는 것이 중요해지고 있습니다. ChatGPT Retrieval Plugin은 개인이나 기업, 조직의 프라이빗 데이터를 ChatGPT가 액세스 하고, 해당 데이터 내에서 검색하여 답변을 제공할 수 있는 기능을 지원합니다. 이 글에서는 ChatGPT Retrieval Plugin 설정, 개발 및 배포하는 방법에 대해 벡터 데이터베이스를 이용하여 소개하겠습니다. 이미 ChatGPT를 보강하려는 모든 개발자가 정보를 자체 호스팅할 수 있도록 OpenAI는 Retrieval plugin을 오픈 소스로 제공하고 있습니다.
GitHub - openai/chatgpt-retrieval-plugin: The ChatGPT Retrieval Plugin lets you easily find personal or work documents by asking
The ChatGPT Retrieval Plugin lets you easily find personal or work documents by asking questions in natural language. - GitHub - openai/chatgpt-retrieval-plugin: The ChatGPT Retrieval Plugin lets y...
github.com
오랫동안 미루고 있었던 ChatGPT Retrieval Plugin의 개발을 드디어 진행해 보았습니다. 아래에서는 이 플러그인의 아키텍처, 필요한 사전 준비 사항, 그리고 개발 코드에 대해 상세하게 설명하겠습니다.
# 1. Architecture

- User Query 전송: 사용자의 질문을 서비스에 보냄
- OpenAI Embedding 요청: OpenAI의 text-embedding-ada-002 모델을 사용하여 User Query를 Embedding
- Pinecone 유사도 검색: Pinecone 데이터베이스의 항목과 User Query의 코사인 유사도를 계산하여 가장 유사한 context를 검색
- 응답 생성: User Query와 검색된 context을 하나의 Prompt로 만들어 OpenAI의 gpt-3.5-turbo 모델에 요청하여 응답을 생성
- 사용자에게 응답을 반환: 생성된 응답을 사용자에게 반환
#2. 사전 준비
ChatGPT Retrieval Plugin을 구성하기 전에 OpenAI API Key, 벡터 데이터베이스, 그리고 JSON Web Token이 필요합니다.
1) OpenAI API Key 발급
OpenAI API
An API for accessing new AI models developed by OpenAI
beta.openai.com
OpenAI API 수행을 위해서는 먼저 API Key 발급이 필요합니다. OpenAI 계정이 필요하며 계정이 없다면 계정 생성이 필요합니다. 간단히 Google이나 Microsoft 계정을 연동할 수 있습니다. 이미 계정이 있다면 로그인 후 진행하시면 됩니다.
로그인이 되었다면 우측 상단 Personal -> [ View API Keys ]를 클릭합니다.
[ + Create new secret key ]를 클릭하여 API Key를 생성합니다. API key generated 창이 활성화되면 Key를 반드시 복사하여 두시기 바랍니다. 창을 닫으면 다시 확인할 수 없습니다. (만약 복사하지 못했다면 다시 Create new secret key 버튼을 눌러 생성하면 되니 걱정하지 않으셔도 됩니다.)
2) 벡터 데이터베이스
ChatGPT Retrieval Plugin은 다양한 벡터 데이터베이스를 지원합니다. 지원하는 데이터베이스는 Pinecone, Elasticsearch, Weaviate, Zilliz, Milvus, Qdrant, Redis, Llama Index, Chroma, Azure Cognitive Search, Supabase, 그리고 Postgres입니다. 본 글에서는 이 중 Pinecone을 사용하여 설명하겠습니다. 무료로 1개의 Vector Database 생성이 가능합니다.
Pinecone 벡터 데이터베이스 생성은 아래 글을 참고하세요.
Pinecone을 이용한 벡터 데이터베이스 시작하기
벡터 데이터베이스는 고차원 벡터 데이터를 효율적으로 저장하고 검색할 수 있는 데이터베이스 시스템입니다. 이 글에서는 벡터 데이터베이스 중 하나인 Pinecone의 기본적인 사용 방법을 소개하
yunwoong.tistory.com
3) JSON Web Token
ChatGPT Retrieval Plugin에서 JSON Web Token (JWT)은 주로 인증과 권한 부여를 위해 사용됩니다.
JWT.IO
JSON Web Tokens are an open, industry standard RFC 7519 method for representing claims securely between two parties.
jwt.io
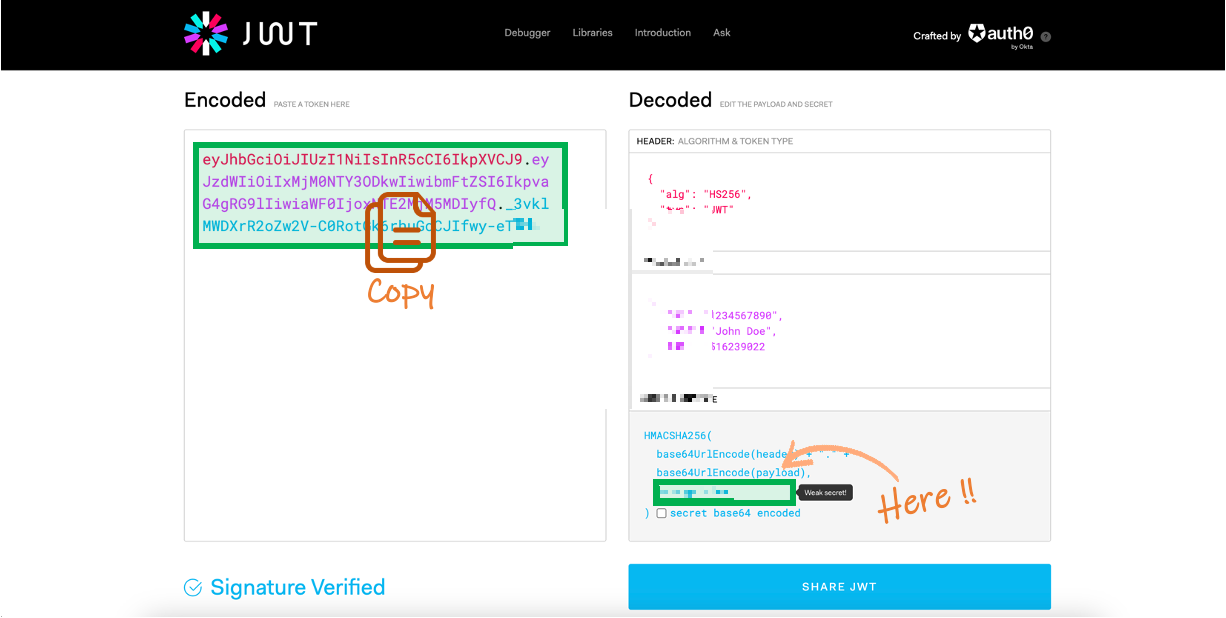
토큰을 식별할 키워드를 입력하고 Encoded 영역의 복사합니다. 밑에 BEARER_TOKEN 환경변수와 FastAPI HTTPBearer Value로 사용됩니다.
#3. 환경구성
1) python은 3.10 버전 설치 (가상환경)
conda create -n test_env python=3.102) 가상환경 활성화
conda activate test_env3) chatgpt-retrieval-plugin Fork
이후 가이드에서 DigitalOcean을 통한 App 구동까지 테스트 하기 위해선 직접 다운로드보다 Fork하여 진행하는 것이 권장합니다.
- GitHub에서 https://github.com/openai/chatgpt-retrieval-plugin 주소로 이동합니다.
- 오른쪽 상단에 있는 'Fork' 버튼을 클릭하여 자신의 계정에 Fork를 생성합니다.
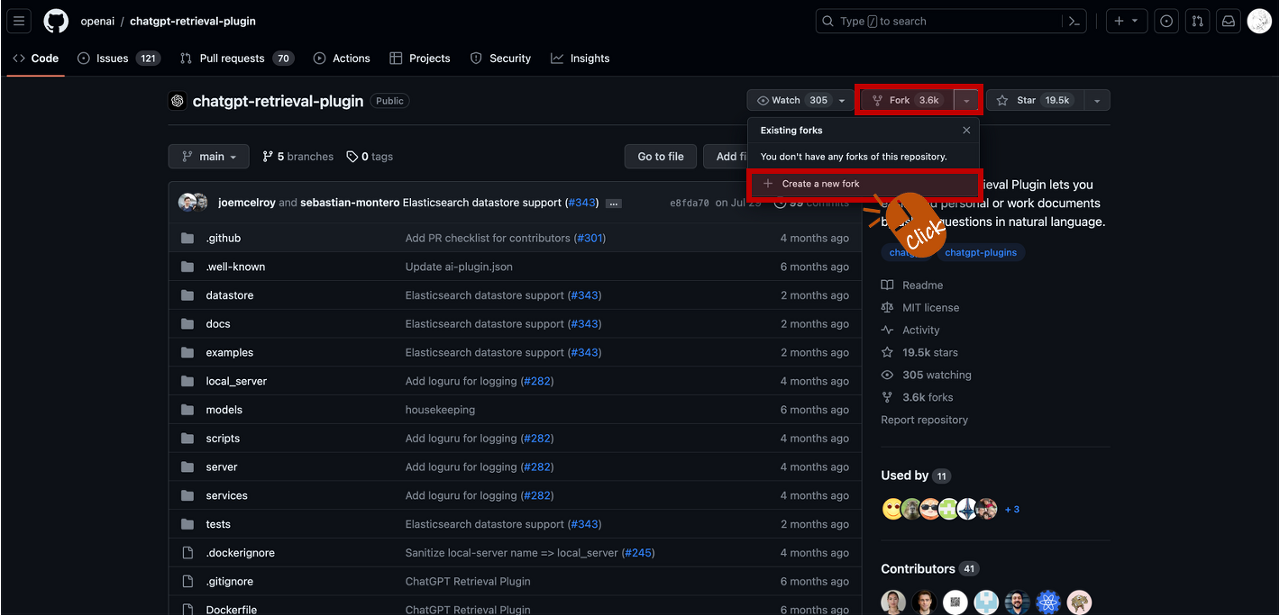
4) Fork한 chatgpt-retrieval-plugin Download
여기서 [YOUR_USERNAME]은 GitHub 사용자 이름으로 대체해주세요.
git clone https://github.com/[YOUR_USERNAME]/chatgpt-retrieval-plugin.git cd /path/to/chatgpt-retrieval-plugin
5) install package
python 패키지 관리 및 종속성 관리를 위해 Poetry를 설치합니다.
pip install poetry6) 종속성 활성화
poetry shell 명령어는 Poetry로 관리되는 프로젝트의 가상 환경(virtual environment)에 접근하기 위한 쉘(Shell)을 활성화합니다. 이 명령어를 실행하면, 해당 프로젝트의 가상 환경에 설치된 Python 인터프리터와 패키지들을 사용할 수 있게 됩니다.
poetry shellpoetry install 명령어는 Poetry로 관리되는 Python 프로젝트의 종속성을 설치하는 데 사용됩니다. 이 명령어를 실행하면, pyproject.toml 파일에 명시된 패키지와 그 버전을 가상 환경에 설치합니다.
poetry install
7) 환경변수 설정
DATASTORE는 임베딩을 저장하고 쿼리 하는 데 사용할 벡터 데이터베이스 공급자입니다. (pinecone, weaviate, zilliz, milvus, qdrant, redis, azuresearch, supabase, postgres, analyticdb 등) OPENAI_API_KEY와 PINECONE_API_KEY, PINECONE_ENVIRONMENT는 사전단계에서 준비한 값입니다. BEARER_TOKEN는 JSON Web Token (JWT)에서 복사한 TOKEN 값입니다.
export DATASTORE=<your_datastore> export OPENAI_API_KEY=<your_openai_api_key> export BEARER_TOKEN=<your_bearer_token> # Pinecone export PINECONE_API_KEY=<your_pinecone_api_key> export PINECONE_ENVIRONMENT=<your_pinecone_environment> export PINECONE_INDEX=<your_pinecone_index>
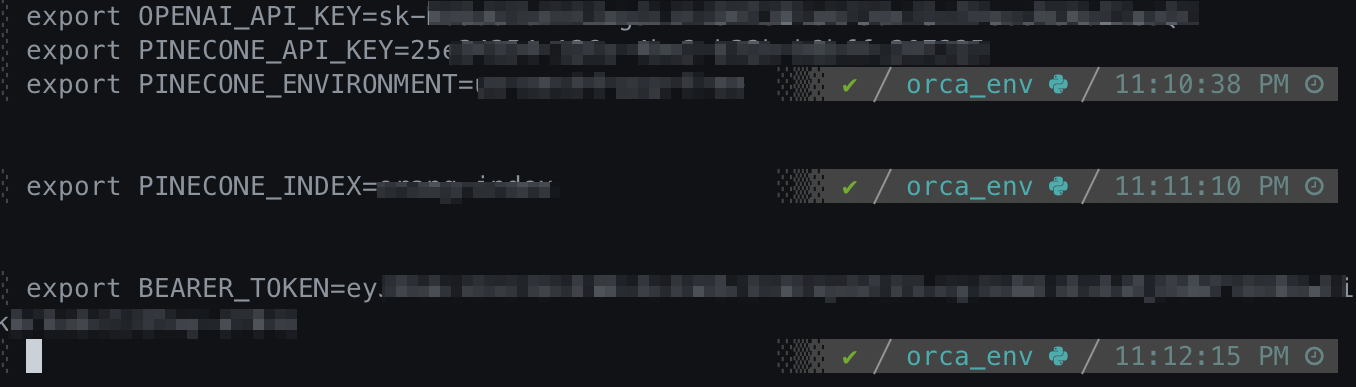
8) 서버 기동
poetry run start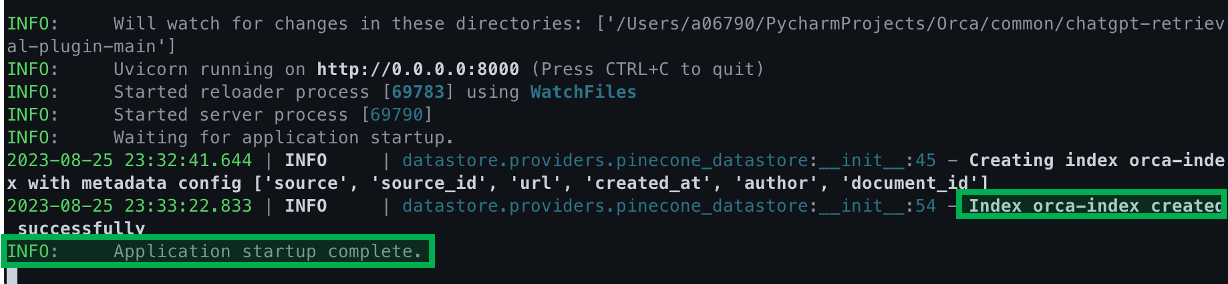
Application startup complete. 문구가 나오면 완료된 것입니다. 서버 기동과 함께 pinecone Database에 인덱스 생성되었습니다.
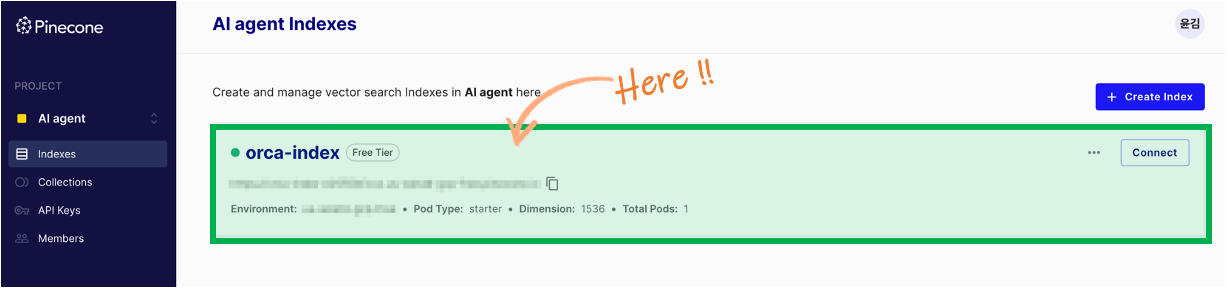
#4. 파일 업로드
FastAPI를 이용해 자신이 보유한 데이터 파일을 업로드하도록 하겠습니다.
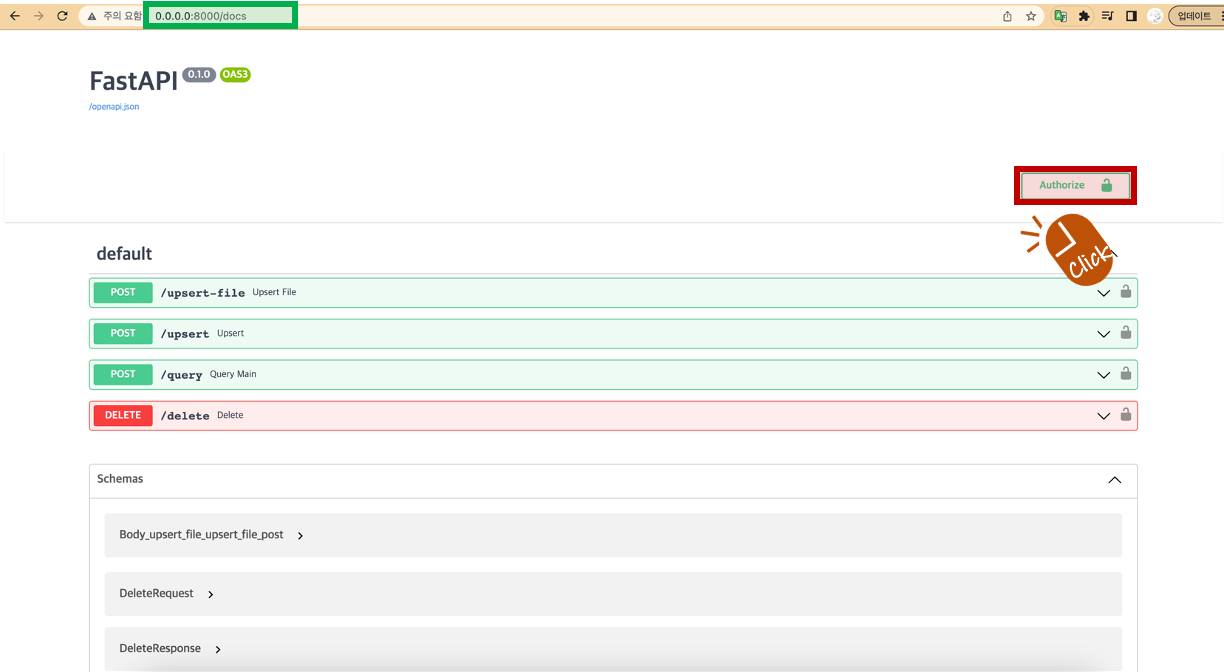
서버 가동 후 http://0.0.0.0:8000/docs에 접속하면 FastAPI 서버의 API 문서 확인할 수 있습니다. 총 4개의 엔드포인트를 확인할 수 있습니다. FastAPI 관련된 내용은 아래를 참고하시면 됩니다.
FastAPI
FastAPI framework, high performance, easy to learn, fast to code, ready for production
fastapi.tiangolo.com
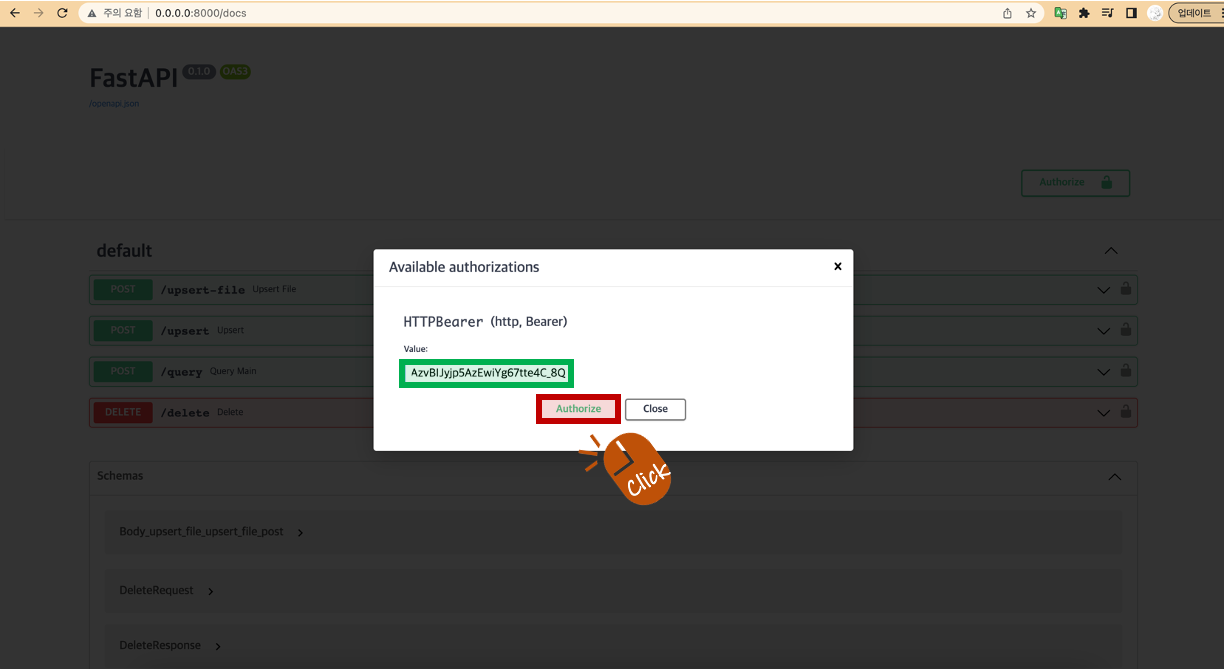
BEARER_TOKEN (https://jwt.io/에서 복사한 TOKEN)을 Value에 붙여 넣고 [ Authorize ]를 클릭합니다.
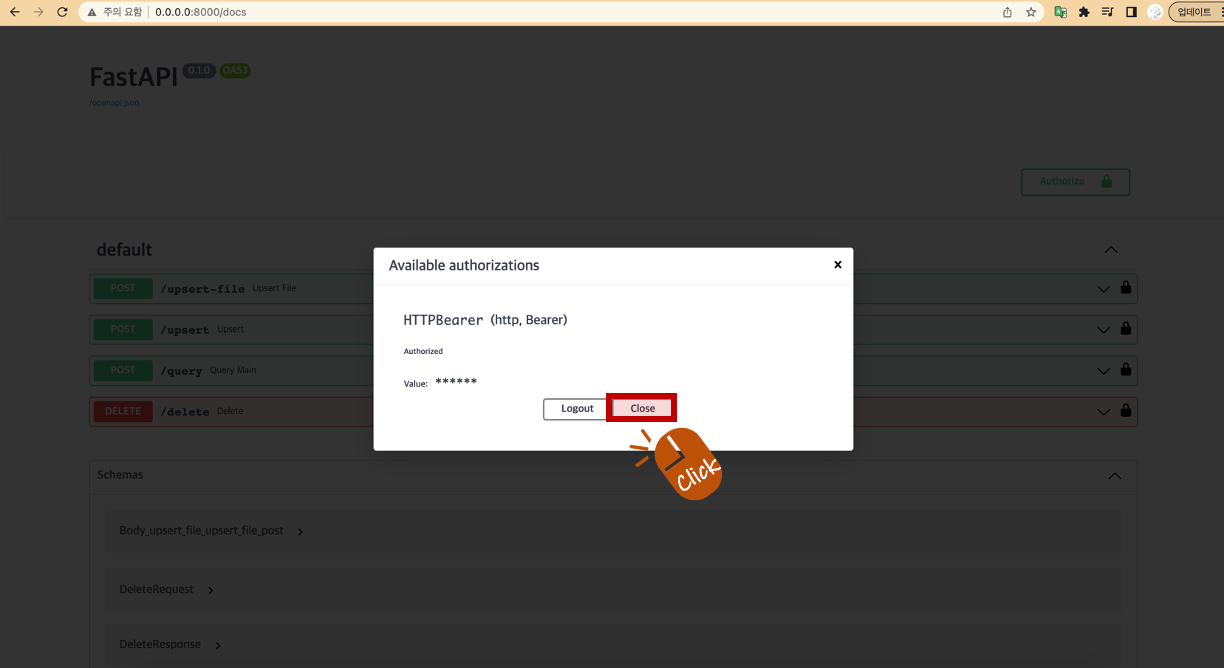
[ Close ]를 클릭합니다.
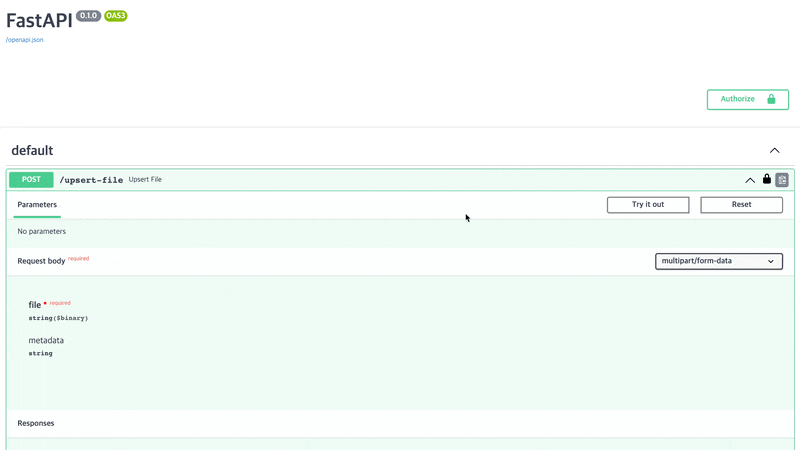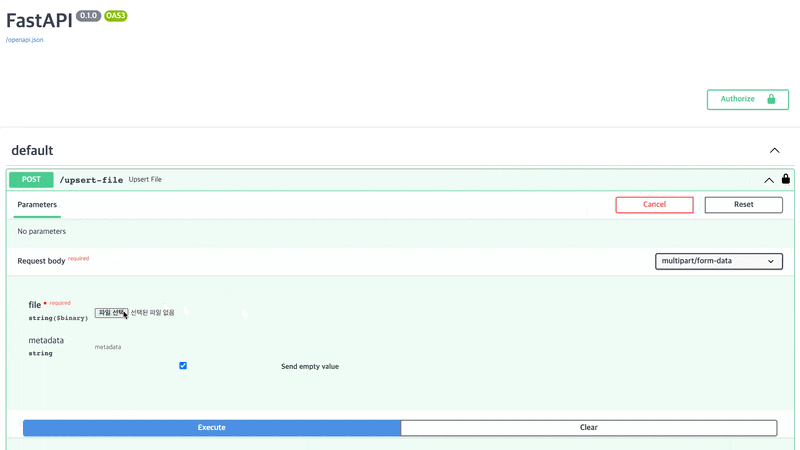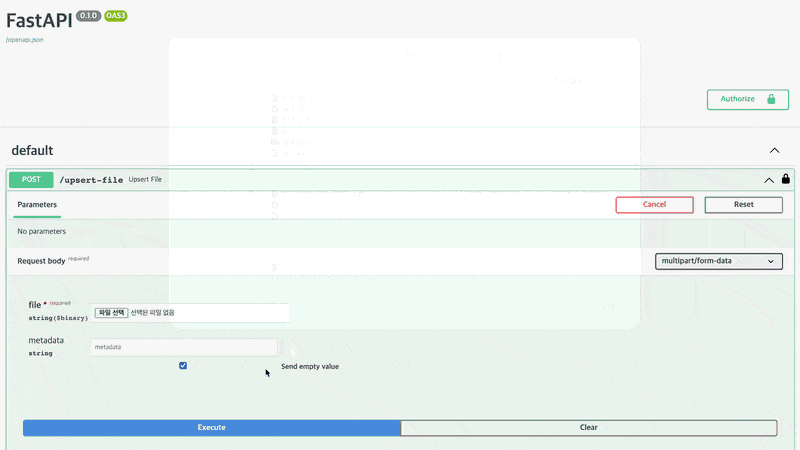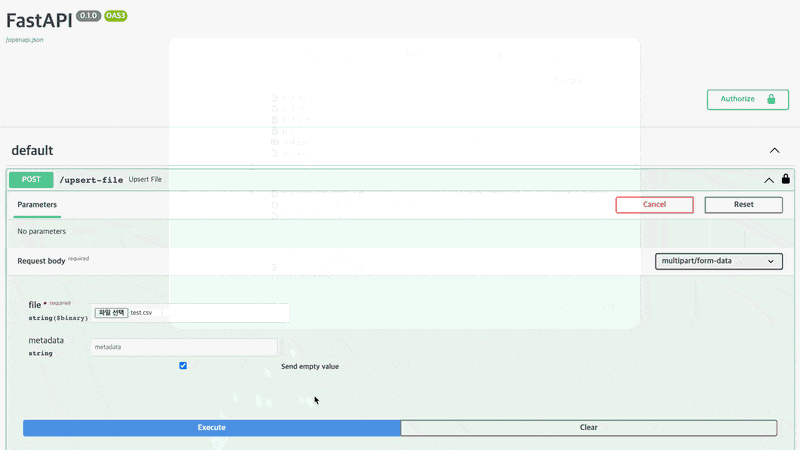
파일을 업로드해보록 하겠습니다. /upsert-file에서 [ Try it out ]을 클릭하고 파일 선택을 한 후 [ Execute ]를 클릭합니다. 저는 예시로 csv파일을 올렸으며 개인적인 정보를 포함하고 있는 파일입니다.

업로드를 수행할 때 파일이 바로 업로드되는 것이 아니라, 파일에서 텍스트를 추출합니다. 파일 크기에 따라 처리 시간이 다를 수 있습니다. "POST /upsert-file HTTP/1.1" 200 OK 가 나왔다면 정상적으로 업로드된 것입니다.
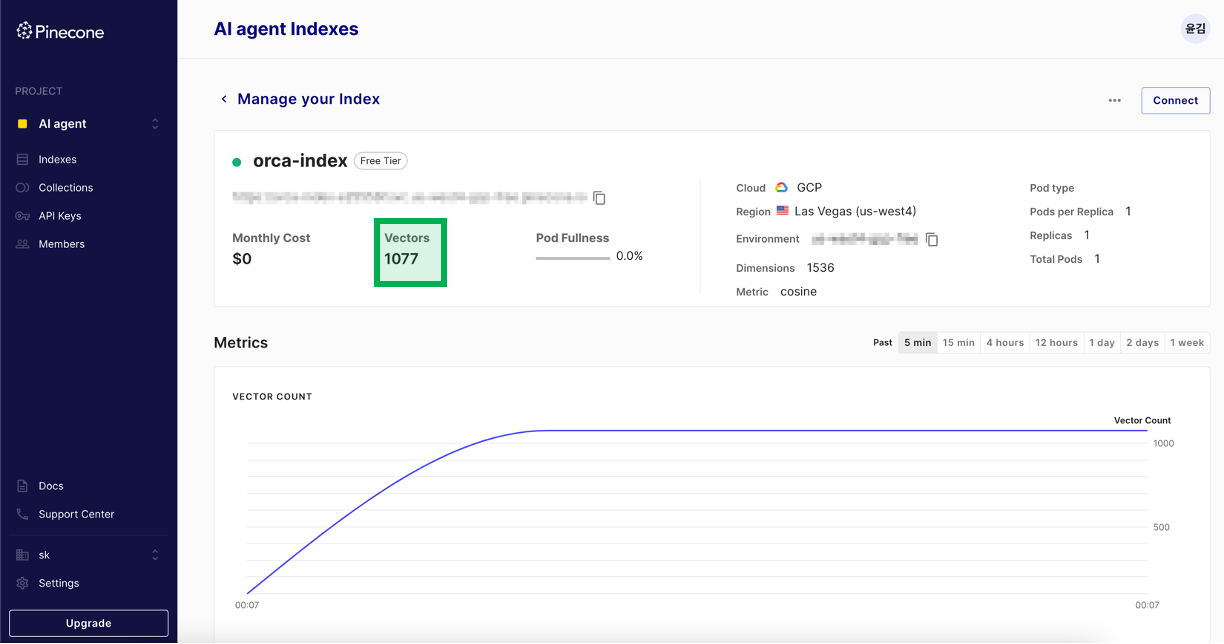
정상적으로 업로드되었다면 Vectors 수가 증가되었습니다.
이번 글에서는 ChatGPT Retrieval Plugin의 기본 구조와 설정 방법에 대해 알아보았습니다. OpenAI API 키와 벡터 데이터베이스 설정 등 필요한 사전 준비 사항도 함께 살펴봤습니다. 다음 글에서는 이러한 준비를 바탕으로 실제로 벡터 데이터베이스를 활용하여 어떻게 더 정확하고 효율적인 검색과 응답을 제공할 수 있는지에 대해 자세히 다룰 예정입니다. 특히, 벡터 데이터베이스를 활용한 검색 알고리즘과 응답 생성 과정을 중점적으로 살펴보겠습니다.
ChatGPT Retrieval Plugin 개발 (2) : 배포 및 실용 가이드
이번 글에서는 벡터 데이터베이스를 활용해 ChatGPT Retrieval Plugin의 개발과 배포를 어떻게 더 효율적으로 할 수 있는지에 대해 깊게 다룰 예정입니다. 환경 설정과 사전 준비는 이전 글에서 확인하
yunwoong.tistory.com
'Tech & Development > AI' 카테고리의 다른 글
| ChatGPT Retrieval Plugin 개발 (2) : 배포 및 실용 가이드 (0) | 2023.08.28 |
|---|---|
| Pinecone을 이용한 벡터 데이터베이스 시작하기 (0) | 2023.08.28 |
| StableCode 사용 가이드: AI 코딩 도구의 활용 방법 (0) | 2023.08.16 |
| text-generation-webui 설치 및 활용 가이드 (1) | 2023.08.10 |
| Meta AI 라마 2 (Llama 2): 사용 가이드 (0) | 2023.07.19 |
댓글을 사용할 수 없습니다.