비정형 데이터 탐색: 벡터 임베딩과 벡터 데이터베이스의 이해
최근 벡터 데이터베이스에 대한 투자자들의 관심이 눈에 띄게 증가하였습니다. 지난 몇 달 동안 벡터 데이터베이스 스타트업인 Weaviate는 시리즈 B 펀딩에서 5000만 달러를, Pinecone은 7500만 달러의 가치 평가를 받아 시리즈 B 펀딩에서 1억 달러를 모금하였습니다. 또한 Chroma, 임베딩 데이터베이스를 위한 오픈 소스 프로젝트는 1800만 달러를 모금하였죠. 이처럼 관심이 높아지고 있는 벡터 데이터베이스에 대해 알아보도록 하겠습니다.
인터넷 초기에는 데이터가 대부분 정형데이터였기 때문에 관계형 데이터베이스(relational databases)를 이용하여 쉽게 저장하고 관리할 수 있었습니다. 하지만 인터넷이 성장하고 발전하면서 비정형 데이터(소셜미디어 게시물, 기사, 이미지, 비디오 등)가 점점 증가하였고 정형 데이터와 달리, 비정형 데이터는 내용을 관계형 데이터베이스에 저장할 방법이 없었습니다. 예를 들어, 인터넷에서 사고 싶은 상품의 사진을 바탕으로 유사한 상품을 검색하다고 생각해 보시면 이미지의 픽셀 값만으로 상품의 스타일, 사이즈, 색상 등을 이해하고 검색하는 것은 관계형 데이터베이스에서는 불가능합니다. 이를 해결하기 위해 이미지에 태그를 달거나 키워드, 속성들을 매핑하여 관리하기도 합니다.

비정형 데이터의 증가에 따라 이러한 데이터를 이해하기 위한 머신러닝 모델의 사용이 증가하게 됩니다. 그러면서 자연스럽게 벡터 임베딩과 벡터 데이터베이스에 주목하게 되고 머신러닝 분야에서 필수적인 요소로 자리 잡게 됩니다. 먼저 벡터 데이터베이스를 이해하기 전에, 먼저 벡터 임베딩이 무엇인지 알아보겠습니다.
벡터 임베딩(Vector Embeddings)
머신러닝에서 벡터 임베딩은 데이터 점들의 집합으로, 그들의 기본적인 관계와 패턴을 보여주는 저차원 공간에 수학적으로 표현하는 것입니다. 이미지, 텍스트, 오디오와 같은 복잡한 데이터 유형을 머신러닝 알고리즘이 쉽게 처리할 수 있도록 표현하는데 임베딩이 자주 활용됩니다. 이는 전문가가 직접 정의하는 것이 아니라, 모델이 대규모 데이터셋을 학습하는 과정에서 자체적으로 발견하며 사람이 식별하기 어려운 복잡한 패턴과 관계를 학습하게 됩니다. 학습이 완료된 후에는, 임베딩은 분류나 회귀와 같은 다른 머신러닝 모델의 특징으로 사용될 수 있습니다. 이를 통해 모델은 원시 입력이 아닌, 임베딩된 데이터를 활용하여 데이터 간의 근본적인 패턴과 관계를 기반으로 예측이나 결정을 내릴 수 있습니다.
이러한 변환의 가능성은 머신 러닝, 특히 신경망의 발전 덕분입니다. 비정형 데이터를 임베딩으로 빠르고 정확하게 변환할 수 있는 능력은 BERT와 같은 텍스트 모델 또는 Vision Transformer와 같은 이미지 모델의 발전 덕분에 가능해졌습니다. 이러한 모델들 덕분에, 데이터를 벡터로 변환했을 때 각 특성이 잘 표현되게 되었습니다.
워드 임베딩 (Word Embeddings)
워드 임베딩은 단어를 저차원 공간에서 벡터로 표현하는 데 사용됩니다. 이러한 임베딩은 단어 간의 의미와 관계를 포착하여 머신러닝 모델이 자연어를 더욱 효과적으로 이해하고 처리할 수 있게 돕습니다. 대표적인 워드 임베딩 모델에는 Word2Vec, GloVe, FastText, ELMo, BERT, GPT 등이 있습니다. 아래는 Word2Vec를 시각화한 모습입니다.
간단한 예로, 우리는 단어 세트를 가지고 있을 수 있습니다. 이 단어들은 벡터이므로 어떤 공간에서 점으로 표현될 수 있 고 각 단어는 특징에 따라 원점으로부터의 위치를 가지게 됩니다. 아래와 같이 'apple'을 기준으로 검색하면 비슷한 위치에 있는 다른 단어들을 확인할 수 있습니다.
아래는 예시입니다. 예시를 위해서는 먼저 GoogleNews-vectors-negative300 파일 다운로드가 필요합니다.
pip install gensimfrom gensim.models import KeyedVectors EMBEDDING_FILE = 'GoogleNews-vectors-negative300.bin' word_vectors = KeyedVectors.load_word2vec_format(EMBEDDING_FILE, binary=True) print(word_vectors.most_similar(positive=['king', 'woman'], negative=['man'], topn=1))
Output :
[('queen', 0.7118193507194519)]OpenAI도 데이터에서 임베딩을 추출하는 서비스를 제공합니다.
Introducing text and code embeddings
We are introducing embeddings, a new endpoint in the OpenAI API that makes it easy to perform natural language and code tasks like semantic search, clustering, topic modeling, and classification.
openai.com
이미지 임베딩(Image Embeddings)
벡터 임베딩은 자연어에만 국한되지 않습니다. 이미지 임베딩은 저차원 공간에서 이미지를 표현하는 데 사용되며 색상 및 질감과 같은 이미지의 시각적 특징을 캡처하여 머신러닝 모델이 이미지 분류나 객체 감지와 같은 컴퓨터 비전 작업을 수행할 수 있도록 합니다. 아래는 Mnist를 시각화한 모습입니다.
아래 예에서 3개의 서로 다른 이미지에 대한 임베딩 벡터를 생성해 보겠습니다. 이 중 2개는 콘텐츠가 유사합니다.



예시는 아래와 같습니다. 예시를 위해 Towhee를 사용합니다. Towhee는 구조화되지 않은 데이터를 임베딩으로 인코딩하는 데 도움이 되는 오픈 소스 기계 학습 파이프라인입니다.
pip install towhee towhee.modelsfrom towhee import pipeline import numpy as np p = pipeline('image-embedding') dog0 = p('https://farm6.staticflickr.com/5012/5493808033_eb1dfcd98f_q.jpg') dog1 = p('https://farm1.staticflickr.com/29/60515385_198df3b357_q.jpg') car = p('https://farm2.staticflickr.com/1171/1088524379_7a150cef81_q.jpg') dog0_vec = dog0 / np.linalg.norm(dog0) dog1_vec = dog1 / np.linalg.norm(dog1) car_vec = car / np.linalg.norm(car) print('dog0 to dog1 distance:', np.linalg.norm(dog0_vec - dog1_vec)) print('dog0 to car distance:', np.linalg.norm(dog0_vec - car_vec))
Output :
dog0 to dog1 distance: 0.80871606 dog0 to car distance: 1.280709
그래프 임베딩 / Graph Embeddings
또한, 그래프 임베딩도 가능합니다. 그래프 임베딩은 서로 연결된 노드들의 네트워크인 그래프를 저차원 벡터 공간으로 표현하는 방법을 제공합니다. 이 임베딩은 그래프 내의 노드 간의 관계를 포착하여 머신러닝 모델이 노드 분류나 링크 예측 같은 작업을 수행하는 데 도움을 줍니다. 아래 왼쪽 이미지는 잘 알려진 Karate 그래프로, 소셜 네트워크를 나타냅니다. 오른쪽 이미지는 DeepWalk를 사용하여 그래프의 노드를 연속 공간에 임베딩한 모습을 보여줍니다.
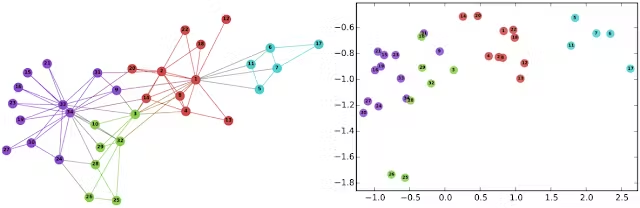
임베딩은 저차원 공간에서 데이터의 본질적인 특성을 표현함으로써, 복잡한 패턴이나 관계를 효율적으로 계산하고 발견하는 데 도움을 줍니다. 이런 장점이 바로 임베딩이 다양한 AI 활용 사례에서 적용되는 이유입니다.
벡터 데이터베이스(Vector Databases)
전통적인 관계형 데이터베이스(relational databases)는 문자열, 숫자, 그리고 다른 종류의 스칼라 데이터를 행과 열에 저장합니다. 그러나 벡터 데이터베이스는 벡터를 기반으로 작동하기 때문에, 그 최적화 방법과 쿼리 수행 방식은 전통적인 데이터베이스와 크게 다릅니다.
일반적인 데이터베이스에서는, 주로 쿼리와 정확히 일치하는 데이터베이스의 행을 찾는 반면, 벡터 데이터베이스에서는 유사성 메트릭을 적용하여 쿼리와 가장 유사한 벡터를 찾습니다.
벡터 데이터베이스는 ANN(Approximate Nearest Neighbor) 검색을 수행하기 위해 다양한 알고리즘 조합을 사용합니다. 이 알고리즘들은 해싱, 양자화 또는 그래프 기반 검색 등을 통해 검색을 최적화합니다.
벡터 데이터베이스에서는 정확도와 속도 사이의 균형을 유지하는 것이 굉장히 중요합니다. 결과의 정확도가 높아질수록 쿼리 처리 속도는 느려질 가능성이 있습니다. 실제 벡터는 2차원이 아닌 수백 개의 차원을 가질 수 있으며, 이러한 벡터를 수천 개와 거리 메트릭을 이용해 비교하는 것은 매우 시간이 많이 소요됩니다. 따라서 벡터 데이터베이스에서는 인덱싱, 쿼리, 후처리라는 세 가지 핵심 요소의 중요성이 강조됩니다.
- 인덱싱 : 벡터 데이터베이스는 PQ, LSH 또는 HNSW와 같은 알고리즘을 사용하여 벡터를 인덱싱합니다. 이 과정은 데이터 구조에 벡터를 매핑하여 더욱 빠른 검색을 가능하게 합니다.
- 쿼리 : 벡터 데이터베이스는 인덱스 쿼리 벡터와 데이터 세트의 인덱스 벡터를 비교하여 가장 가까운 이웃을 찾습니다. (이때 해당 인덱스에서 사용하는 유사성 메트릭이 적용)
- 후처리 : 필요에 따라 벡터 데이터베이스는 데이터 세트에서 최종적으로 가장 가까운 이웃을 검색하고 후처리하여 최종 결과를 반환합니다. 이 과정은 다른 유사성 척도를 사용하여 가장 가까운 이웃의 순위를 재정렬하는 작업을 포함할 수 있습니다.
벡터 데이터베이스 종류
Pinecone
Vector Database for Vector Search | Pinecone
Search through billions of items for similar matches to any object, in milliseconds. It’s the next generation of search, an API call away.
www.pinecone.io
Qdrant
Qdrant - Vector Database
Qdrant is an Open-Source Vector Database and Vector Search Engine written in Rust. It provides fast and scalable vector similarity search service with convenient API.
qdrant.tech
Weaviate
Welcome | Weaviate - vector database
Welcome to Weaviate
weaviate.io
Milvus
Vector database - Milvus
Milvus is the world's most advanced open-source vector database, built for developing and maintaining AI applications.
milvus.io
Chroma
the AI-native open-source embedding database
the AI-native open-source embedding database
www.trychroma.com
Vespa
Vespa - the big data serving engine
Building something real? You'll need to co-locate vectors, metadata and content on the same item on the same node, run inference there to achieve scalable performance, and seamlessly scale this across nodes to handle any amount of data and traffic. Vespa d
vespa.ai
Redis
Redis
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message broker
redis.io
벡터 데이터베이스는 대규모 데이터셋에 대한 유사성 검색과 그 외 복잡한 작업을 효과적으로 수행하는 강력한 도구로 자리매김하였습니다.
특히, 머신러닝과 AI의 등장에 따라, 벡터 데이터베이스는 추천 시스템, 이미지 검색, 의미론적 유사성 등 다양한 애플리케이션에서 그 중요성이 증가하고 있습니다. 곧 소개할 예정이지만 ChatGPT Plugin (Retrieval)의 기능에서도 벡터 데이터베이스는 매우 중요합니다. 사용자의 질문이나 요청에 가장 관련성이 높은 정보를 효과적으로 검색하고 가져오는 데 벡터 데이터베이스가 중요한 역할을 하기 때문입니다.
비정형 데이터의 증가와 더불어 머신 러닝 모델의 사용이 늘어나고 있습니다. 이처럼 복잡한 비정형 데이터를 이해하고 활용하기 위한 벡터 데이터베이스의 발전과 활용은 앞으로도 계속 이어질 것으로 보입니다.
'Tech & Development > AI' 카테고리의 다른 글
| text-generation-webui 설치 및 활용 가이드 (1) | 2023.08.10 |
|---|---|
| Meta AI 라마 2 (Llama 2): 사용 가이드 (0) | 2023.07.19 |
| PandasAI: 데이터 분석을 위한 대화형 AI 도구 (0) | 2023.05.25 |
| [ Pynecone ] ChatGPT App 만들기 (Python) (0) | 2023.03.28 |
| [ Pynecone ] DALL·E 모델로 이미지를 생성 App 만들기 (Python) (0) | 2023.03.28 |
댓글을 사용할 수 없습니다.