Labeling Tool (UTTU)
Machine Learning은 Data에 매우 의존적이며 부정확한 Labeling Data는 모델의 성능에 악영향을 줍니다. 그렇기때문에 정확한 Labeling 작업이 매우 중요한데 이 작업은 매우 힘들고 고되며 많은 비용과 시간이 소요됩니다. Machine Learning의 Data 중요성은 이전 글을 참고 하시기 바랍니다.
AI 프로젝트를 경험했다면 이 Data의 문제를 잘 알고 계실 겁니다. 저는 높은 품질의 데이터로 빠르고 효율적으로 작업을 완료할 수 있도록 Labeling Tool을 만들었으며 Tool의 이름은 UTTU입니다.
UTTU 기능
1. 작업 및 프로젝트 관리
프로젝트별 진행 사항을 관리 할 수 있도록 직관적이고 시각적인 대시보드를 제공하며 각 프로젝트의 작업유형, 진행량, 소요 시간을 확인 할 수 있습니다.

2. 기본 Labeling 도구
|
rectangle | Object Detection Model 학습을 위해 가장 흔하게 사용되는 Bounding Box 형태 |
|
polygon | Semantic Segmentation Model 학습을 위해 모든 픽셀의 구분 |
|
circle | 모양의 형태가 명확히 원인 경우 효과적으로 Labeling 위해 사용 (Ex. 빛 번짐, 오염의 모양이 원인 경우) |
|
line | 모양의 형태가 명확히 직선인 경우 효과적으로 Labeling 위해 사용 (Ex. 차선) |
|
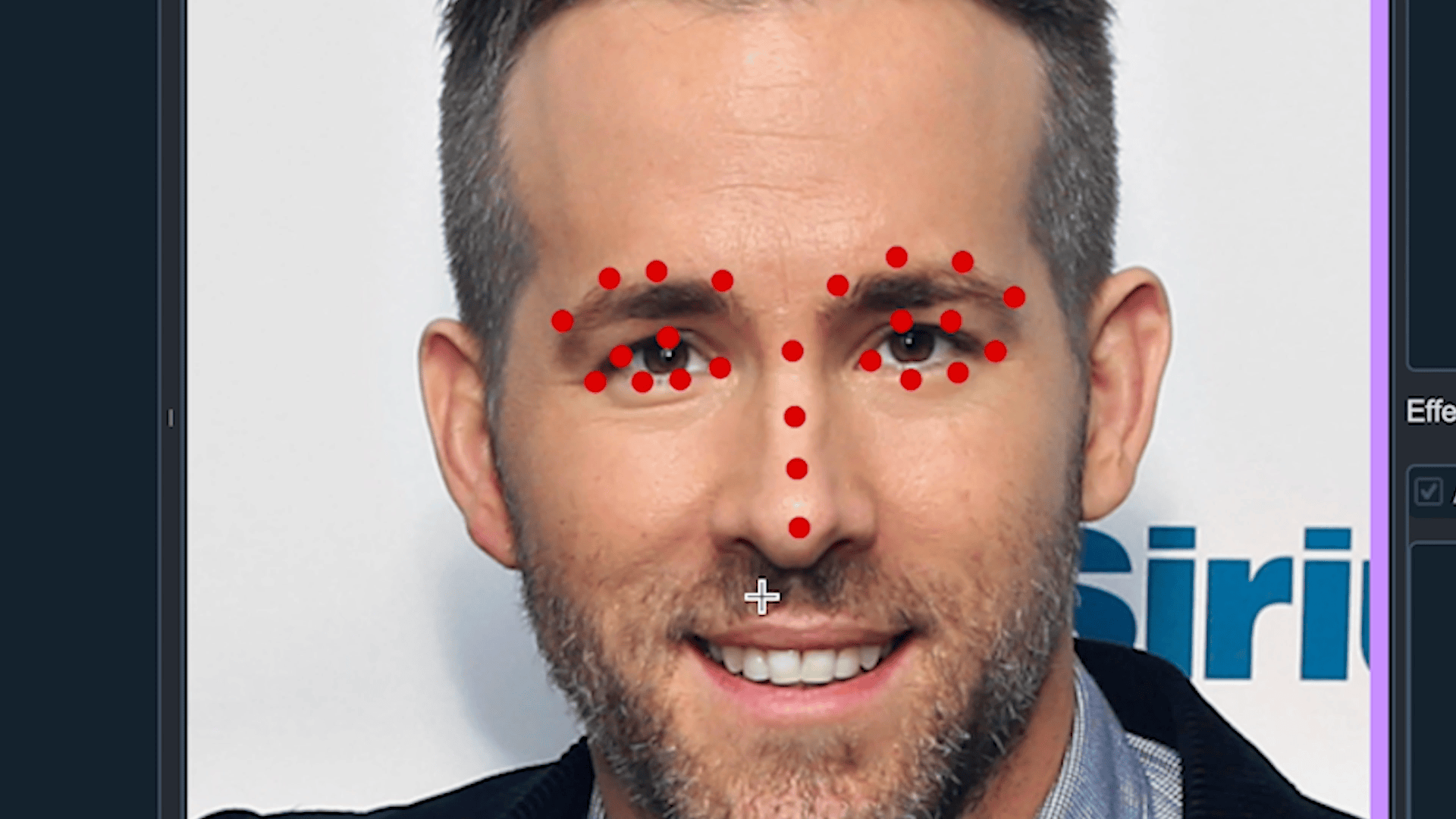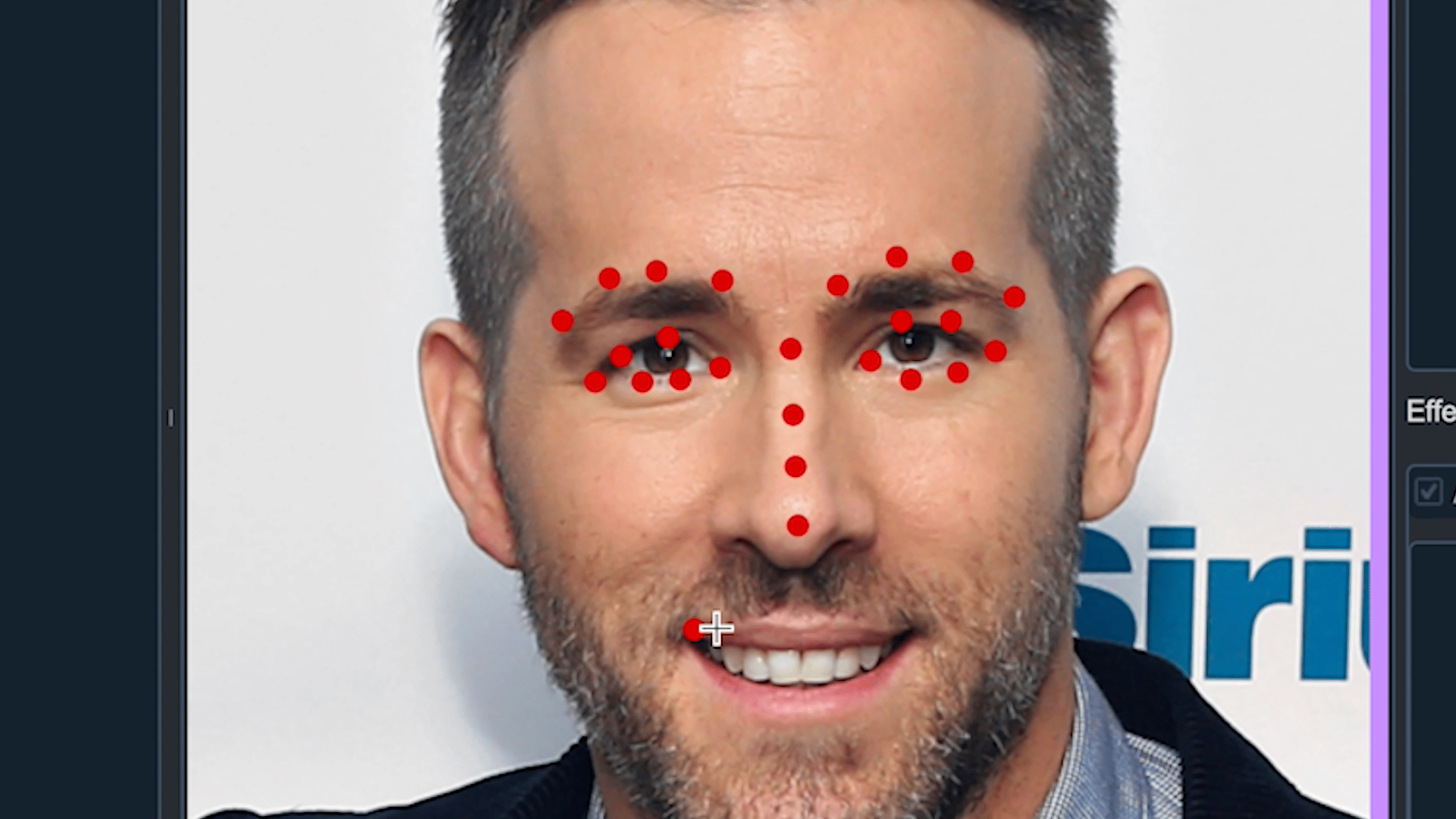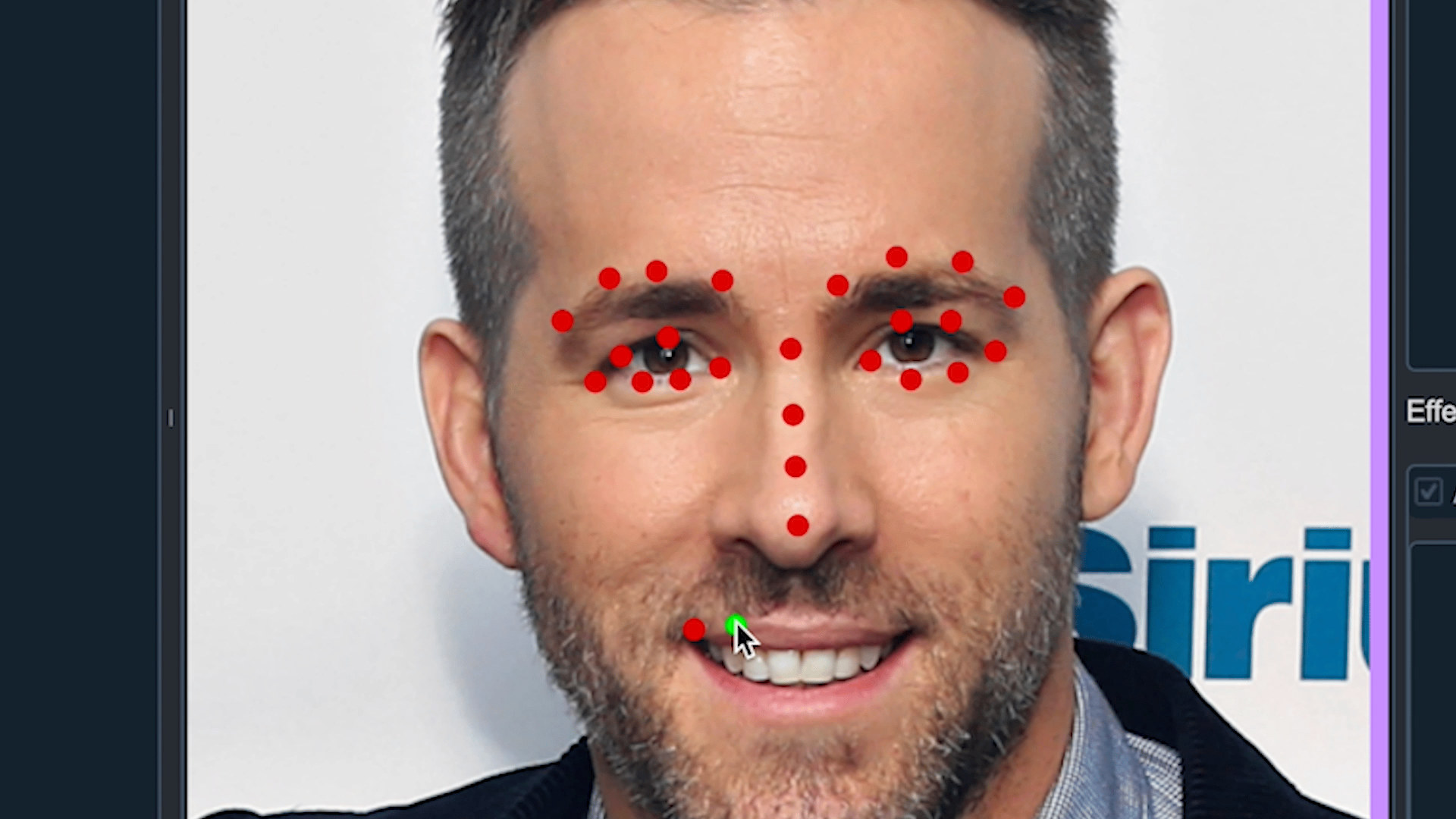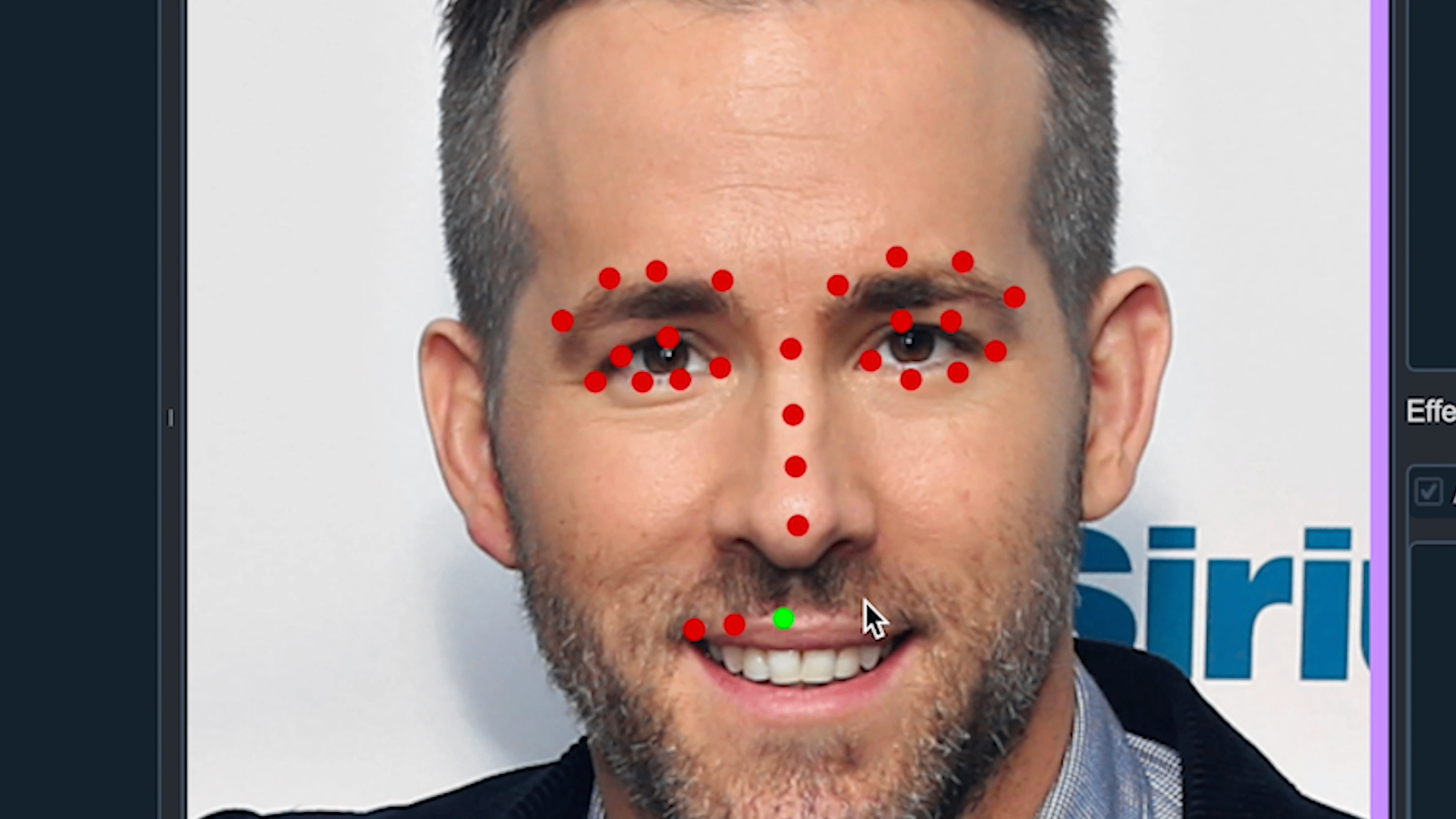
point | 이미지에서 특정 Point만 찾기 위한 Model 학습을 위해 사용 (Ex. Face Landmark) |
|
line strip | 특정 Point와 연결된 선을 찾기 위한 Model 학습을 위해 사용 (Ex. 신체 골격 & 자세 예측) |




3. Smart Labeling 도구
1) Smart object labeling
- Using Pre-trained Model : Public Dataset (80 class)로 학습된 모델을 이용하여 드래그한 영역에서 Object를 찾는 방식
- 작업유형 : Semantic Segmentation
- 사용된 모델
- Swin Transformer (Swin-L) Pre-Trained Model

- Using Edge detection Model : 곽선을 검출하고 Threshold 를 적용 후 윤곽선에 해당하는 영역을 찾는 방식
- 작업유형 : Bounding Box
- 사용된 모델
- RCF(Richer Convolutional Features for Edge Detection) Pre-Trained Model
- HED(Holistically-Nested Edge Detection) Custom Model - *BSDS500 Dataset을 이용하여 직접 학습시킨 모델

BSDS(The Berkeley Segmentation Dataset and Benchmark)500 Dataset을 이용하여 학습을 시켰습니다. BSDS Dataset의 경우 300개의 Train data와 200개의 Validation data로 이루어져 있는데 UTTU를 이용하여 데이타를 증가 시켜 학습을 하였습니다.

Canny와 같은 이미지 연산을 이용한 윤곽선 검출은 임계값의 설정에 따라 결과가 달라지며 복잡한 이미지나 음영, 조도, 명암등의 영향을 많이 받기때문에 현실 세계의 복잡한 이미지를 다루기에는 한계가 있습니다.
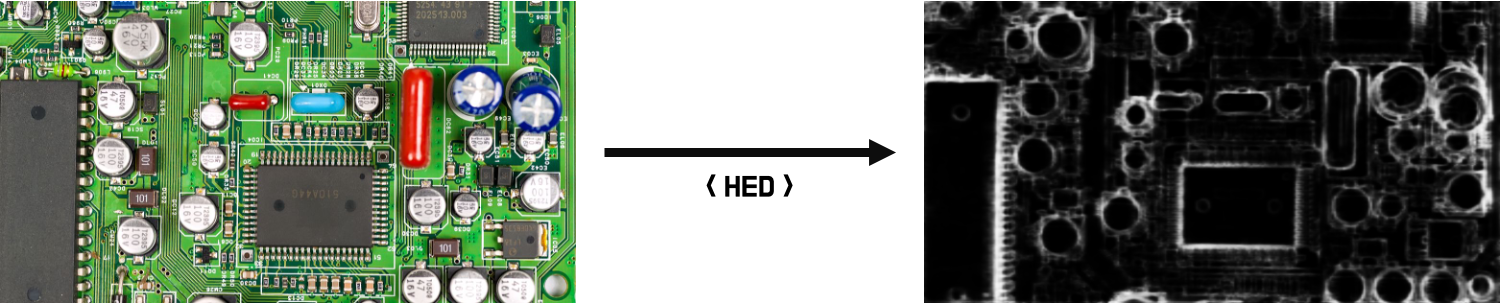
HED 모델을 이용하면 복잡한 이미지에서도 까다롭고 모호한 경계선을 매우 정확하게 찾을 수 있습니다.

HED 모델을 통해 얻은 이미지에서 contour를 경계선을 찾아 인접한 Box를 생성합니다.
2) Smart text labeling
Text와 관련된 Public Data의 Annotation은 대부분 단어 수준(Word-level)으로 labeling 되어 있습니다. 낱글자, 문자 수준(Character-level)으로 labeling을 해야 한다면 글자 하나씩 모두를 선택하기때문에 반복적이고 피로도가 매우 높은 작업입니다. Smart text labeling은 CRAFT와 YOLOv5 모델을 이용하여 자동으로 영역을 찾아 labeling을 도와줍니다.
- 선택된 영역에서 Text를 검출하고 검출된 글자를 낱글자 수준(Character-level)으로 labeling하는 기능
- 작업유형 : Bounding Box
- 사용된 모델
- CRAFT (Character-Region Awareness For Text detection) Pre-Trained Model
- YOLOv5 Custom Model 💡

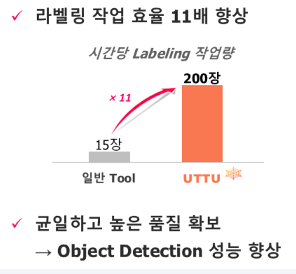
CRAFT 모델의 경우는 Pre-Trained 모델을 이용하였고 YOLOv5의 모델의 경우는 Custom Data를 이용하여 학습 시킨 모델을 이용하였습니다. CRAFT 알고리즘은 Naver Clova AI팀에서 개발한 Text를 추출하기 위한 Deep learning 모델입니다. CRAFT 이 자체로만도 성능이 매우 뛰어나지만 GPU가 없는 환경에서 CPU를 이용하여 연산한다면 1장당 처리 속도는 11 ~ 18초가 소요됩니다. 그래서 추가적으로 YOLOv5를 이용하여 Text Detection 모델을 만들었고 장당 처리 속도는 CPU환경에서도 1초 ~ 2초 정도 소요됩니다. 사용자는 자신의 환경에 따라 CRAFT, YOLOv5 모델을 선택하여 Smart text labeling을 사용 할 수 있습니다.
해당 기능은 프로젝트 당시 Labeling 작업에 사용하였고 1시간에 15장 처리했던 일을 1시간에 200장을 처리 할 수 있었고 작업 효율은 약 11배 이상 증가하였습니다. Labeling 품질 또한 일정하고 높은 품질로 가능했고 모델의 성능 역시 매우 뛰어난 결과를 얻을 수 있었습니다.
3) Smart face labeling
얼굴을 인식하는 기능은 이미 뛰어난 모델들이 많습니다. Pre-Trained 모델들을 활용하여 자동으로 labeling하는 기능을 만들었습니다. 처음에 이 기능을 만든 이유는 한 이미지에서 대량의 labeling이 필요한 경우 효과적인지 검증하고 직접 만든 모델이 아니여도 활용하여 적용이 가능한 지 기능적인 점검을 위해 만들었습니다. 결과는 매우 좋았습니다.
- dlib과 mediapipe를 이용하여 face를 검출하여 labeling 하는 기능
- 작업 유형 : Bounding Box, Semantic Segmentation
- 사용된 모델
- HOG(Histogram of Oriented Gradients) + Linear SVM
- MMOD(Max-Margin Object Detection) CNN

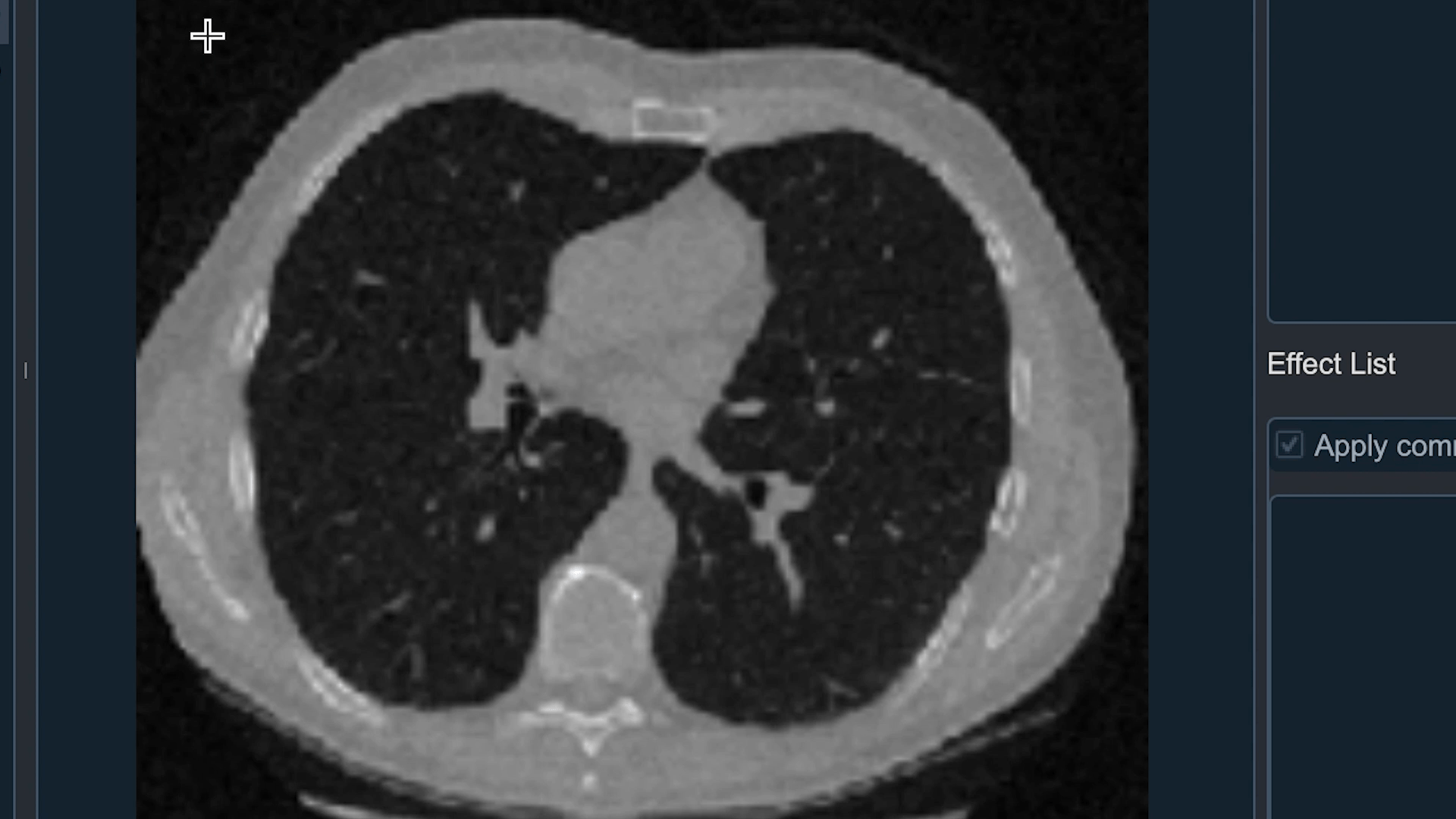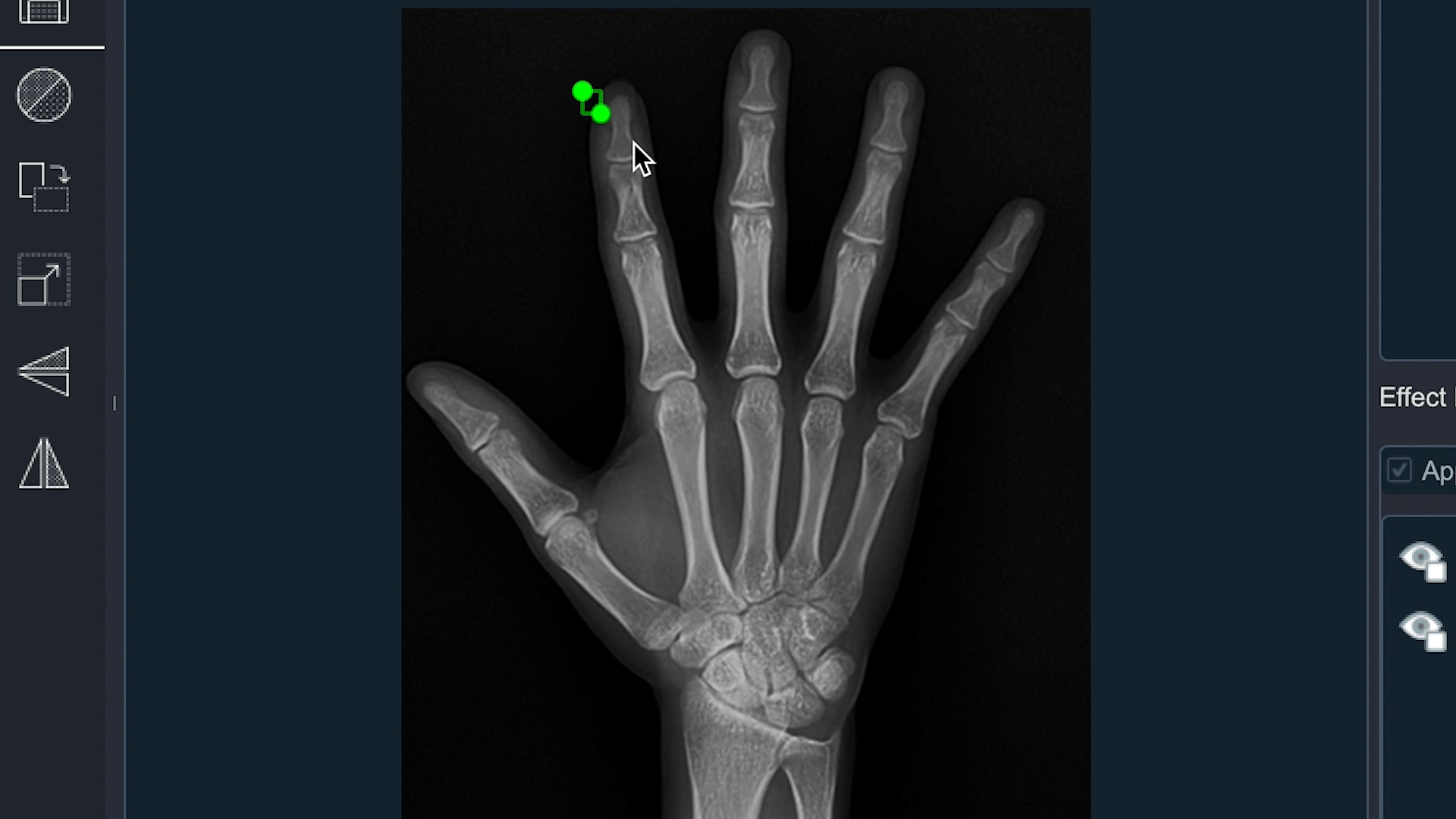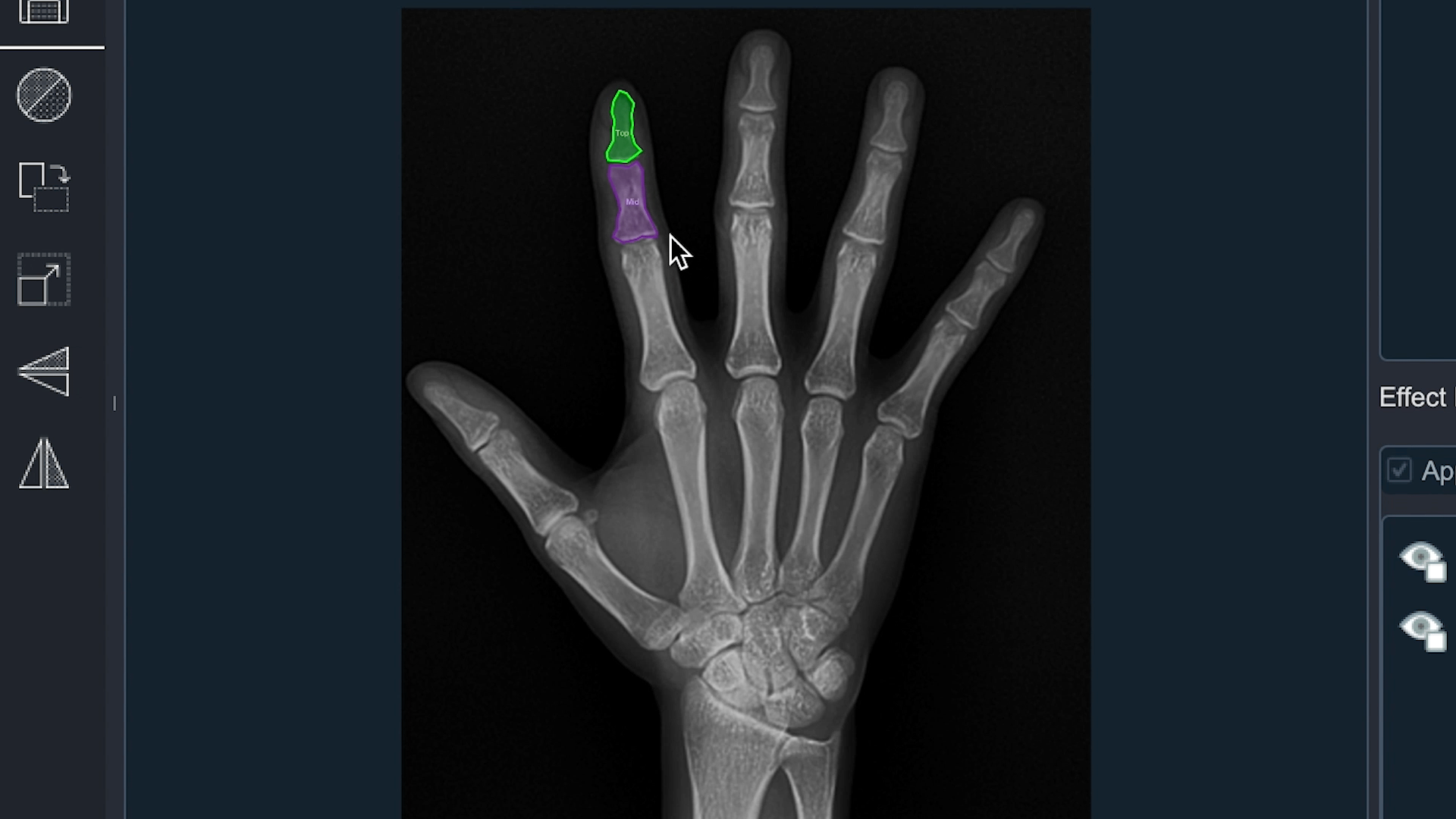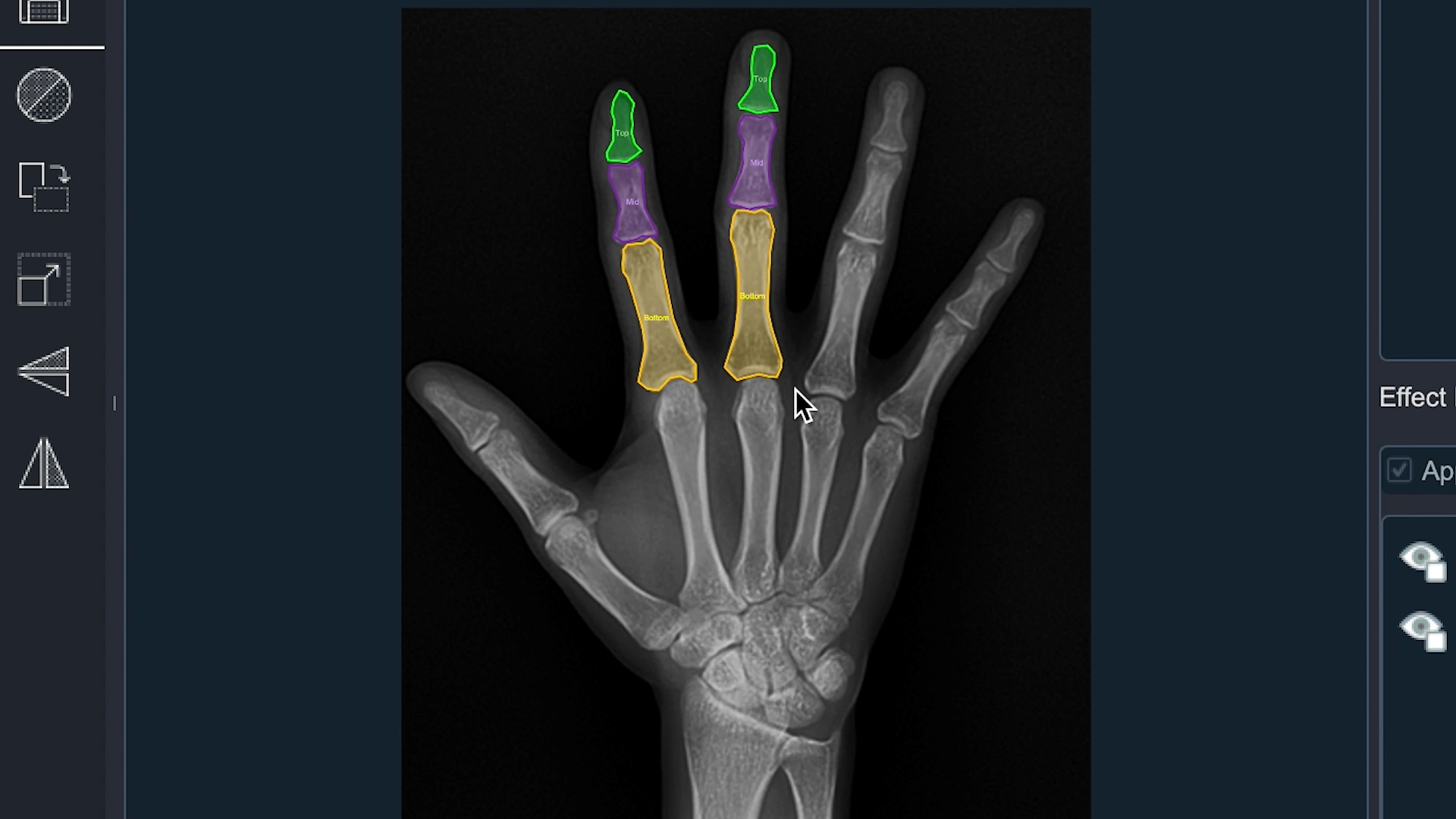
4) Smart medical labeling
영역 검출의 경우는 이미 의학적으로 많이 활용되고 있습니다. 폐, 적혈구, 손가락 뼈 영역을 검출하는 기능을 하나의 Smart Labeling 기능으로 구현한 이유는 쉽게 구할 수 있는 Public data 중 하나가 의료와 관련된 Data이고 효과를 쉽게 확인해 볼 수 있기때문입니다. 예를들면 폐 영역을 찾기위해 활용한 Dataset은 LUNA16 Grand Challenge에서 사용된 LIDC/IDRI 데이터 세트를 사용하며 이 데이터는 4명의 방사선 전문가가 작성한 주석을 포함하고 있고 공개적으로 사용 가능합니다. 이 데이터를 가공하여 CNN 기반의 Convolutional Encoder Decoder Model를 만들어 활용하였습니다.
- 학습된 모델을 이용하여 폐 영역, 적혈구, 손가락 뼈를 구분하여 labeling 하는 기능
- 작업 유형 : Bounding Box, Semantic Segmentation
- 사용된 모델
- Convolutional Encoder Decoder
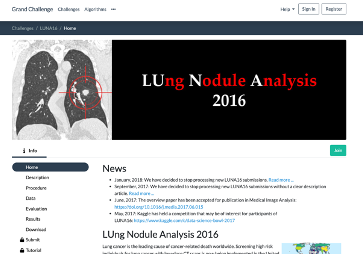
1) 목적 : 폐 결핵, 폐암, 폐렴 등을 인공지능으로 진단하기 위해 폐 영역을 구분하여 검출 할 필요가 있습니다. CT 혹은 MRI 사진에서 폐의 영역을 찾은 후 폐 영역 안에서 폐 결핵, 폐렴, 폐암의 가능성을 판단하기 때문에 우선적으로 폐의 영역 검출이 중요합니다.
2) Smart Labeling 기능으로 폐/적혈구 영역을 검출하도록 구현한 이유 : Data가 없는 우리 회사의 환경에서 가장 많은 공용 Data 중 하나가 의료와 관련된 Data이고 효과를 쉽게 확인해 볼 수 있기때문입니다. 활용한 Dataset은 폐의 영역을 찾기 위해서 LUNA16 Grand Challenge에서 사용된 LIDC/IDRI 데이터 세트를 사용하며 이 데이터는 4명의 방사선 전문가가 작성한 주석을 포함하고 있고 공개적으로 사용 가능합니다
3) 사용된 Model : Convolutional Encoder Decoder
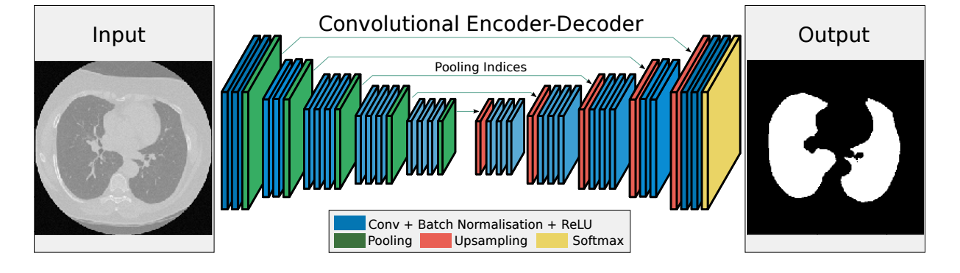
convolution neural network(CNN)으로 이루어진 Encoder와 Decoder로 구성되어 있습니다. Encoder는 차원을 축소하며 필요한 정보만을 추출하는 것이고 Decoder의 경우는 압축된 정보로부터 차원 확장을 통해 원하는 정보를 복원하는 것입니다. Input으로 CT 이미지로 넣고 Output으로 폐의 영역만을 mask 한 이미지를 나오도록 Model을 만들었습니다.
위의 이미지에서 왼쪽이 Encoder 이고 오른쪽이 Decoder입니다. Encoder는 Downsampling 중 MaxPooling2D을 사용했고 Upsampling으로 Upsampling2D를 사용했습니다. 마직막으로 Sigmoid Layer가 0과 1로 구분하여 Output을 만듭니다.
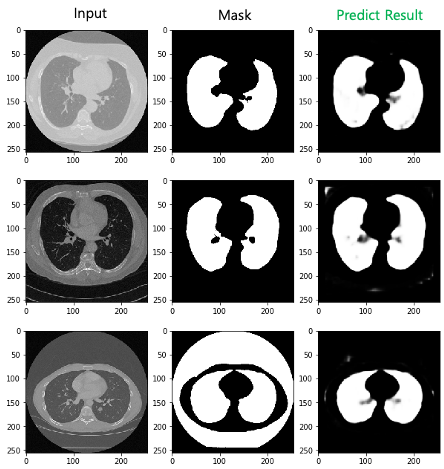
현직에서 일하고 있는 의학 박사들의 지식이 필요하겠지만 이 귀찮은 일들을 Smart Labeling을 통해서 선행으로 해보고 그 결과 값을 사람이 판단하고 미세 조정 후 결과를 만듭다면 높은 품질의 결과를 얻을 수 있을 것이라 생각합니다.
5) Smart color labeling
색상정보로 labeling하는 smart color labeling은 Deep learning 방법이 아닌 더 간단한 M/L 방법을 이용하여 labeling을 합니다. Deep learning을 이용하면 이전에 labeling 된 데이타가 있어야 히지만 없는 경우가 있습니다. 그런 경우 이미지의 다른 정보를 활용할 수 있는데 그 중 하나가 색상 정보입니다. 이미지를 이루고 있는 각 픽셀의 R, G, B 값을 이용하여 색상을 분류하고 동일한 색상인 경우 그 영역을 포함하여 labeling 합니다.
- RGB 정보를 이용하여 선택한 색상 조건에 맞는 영역을 labeling 하는 기능
- 작업 유형 : Bounding Box, Semantic Segmentation
- 사용된 모델
- XGBoost
- Random Forest

색상 정보는 Web color를 기반으로 작성하였고 테스트를 위해 총 7가지 색상으로 분류하여 label를 지정하였습니다.
| Color | label | R | G | B |
| Red | Red | 255 | 0 | 0 |
| DarkRed | Red | 139 | 0 | 0 |
| Firebrick | Red | 178 | 34 | 34 |
| … | … | … | … | … |
| Lime | Green | 0 | 255 | 0 |
| LimeGreen | Green | 50 | 205 | 50 |
| … | … | … | … | … |
픽셀 단위로 각 R, G, B 값을 추출하여 분류하며 분류 모델을 수행하며 동일한 label 단위로 그룹핑합니다. XGBoost가 아닌 Random Forest를 이용해도 꽤 좋은 수준의 결과가 나옵니다. 다만 이미지의 음영이나 명암으로 이로 인해 밝은 부분의 픽셀과 어두운 부분의 색상이 잘못 인식 될 수 있지만 이 방법은 이미지 내에서 추출하고자 하는 대상의 구조나 모양에 영향을 받지 않기 때문에 Deep learning의 방식 보다 더 나은 품질의 결과를 얻을 수 있습니다.

Random Forest실제로 XGBoost를 활용하여 부식된 영역을 찾을 수도 있다고 소개되는 AWS blog 글도 있습니다.
4. Augmentation
한정된 데이타셋을 Augmentation 기능을 이용하여 부족한 데이타 문제를 해결하거나 데이타 편중 문제를 해결할 수 있습니다.

5. Export
- YOLO v5, YOLO v7 PyTorch
- YOLO Darknet
- Pascal VOC
- COCO JSON
- Tensorflow Object Detection CSV
6. UTTU Model Library (Colab)
- Classification
- YOLOv5 Classification
- Vision Transformer
- Resnet-34
- EfficientNet
- MobileNetV2 Classification
- VGGNet
- Object Detection
- YOLOv5
- YOLOv7
- Scaled-YOLOv4
- EfficientDet
- Faster R-CNN
- MobiledNetv2-SSD
- Detectron2
- Swin Transformer
- Soft Teacher
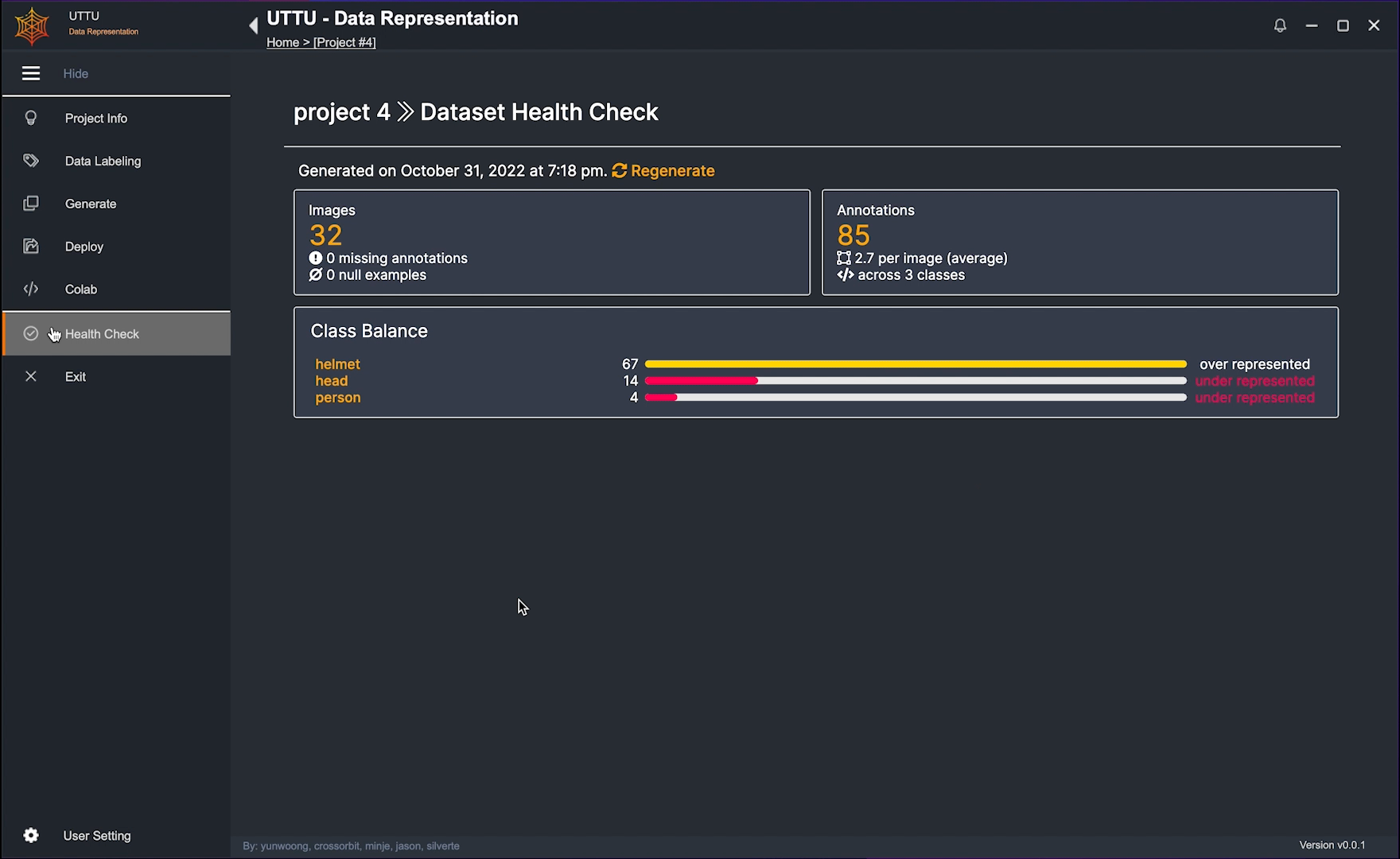
7. Health Check
- imbalanced data
DEMO 영상
개발은 python을 이용하여 개발하였고 윈도우 설치도 가능한 버전으로 만들었습니다. 하지만 아직 어떤식으로 배포를 할 지 고민중입니다.
'Project' 카테고리의 다른 글
| Orca: 다양한 언어와 문화의 채팅 💬 협업 플랫폼 봇 (0) | 2023.10.17 |
|---|---|
| 간편 심사 서비스 (0) | 2023.01.16 |
| 문서이해 Solution 개발 (VisionOCR) (0) | 2023.01.02 |
| Covid-19 사회적 거리두기 측정 (0) | 2022.02.24 |
| Paperless Hospital - 서류관리 Mobile App 개발 (Android & Python) (0) | 2022.02.18 |
댓글을 사용할 수 없습니다.