구글의 AI 혁신: Gemini 2.0부터 Veo2까지
구글이 최신 AI 모델인 Gemini 2.0 Flash을 공개했습니다. 이번에는 OpenAI의 12일 이벤트 중간에 발표를 진행했는데요, 작년과는 달리 이번에는 구글이 훨씬 더 준비된 모습을 보여줬습니다.

주요 특징과 발전된 기능들
- Flash의 성능 향상
- Gemini 1.5 Pro보다 2배 빠른 속도
- 더 낮은 지연시간으로 실시간 대화 가능
- 성능은 향상되었는데 속도는 더 빨라진 게 인상적
- 확장된 멀티모달 기능
- 텍스트, 이미지, 오디오 입출력 모두 지원
- 실시간 음성 변환과 다국어 지원
- 마치 실제 비서와 대화하는 것 같은 자연스러움
- 네이티브 도구 통합
- 구글 검색 직접 연동
- 코드 실행 기능 내장
- 서드파티 도구와도 연동 가능
혁신적인 연구 프로젝트들
1. 프로젝트 아스트라 (Astra)
OpenAI의 Advanced Voice Mode와 비슷한 기능입니다. 지난 5월 구글 I/O에서 처음 선보였는데, 하루 전 OpenAI가 라이브 행사에서 먼저 공개하면서 다소 아쉬움이 있었습니다. 이때 아스트라는 OpenAI 대비 지연 시간이나 성능면에서 부족해 보였는데, 이번 데모 영상을 보니 많이 발전한 모습이네요. 특히 구글의 강점인 검색, 렌즈, 지도까지 통합되어 있어 실용성도 한층 높아진 것 같습니다.
- 더 나은 대화 능력: 다국어, 혼합 언어 지원
- 새로운 도구 활용: 구글 검색, 렌즈, 지도 통합
- 10분 단위 대화 기억 기능
- 추후 스마트 글라스 연동 예정이라는 점이 흥미로움
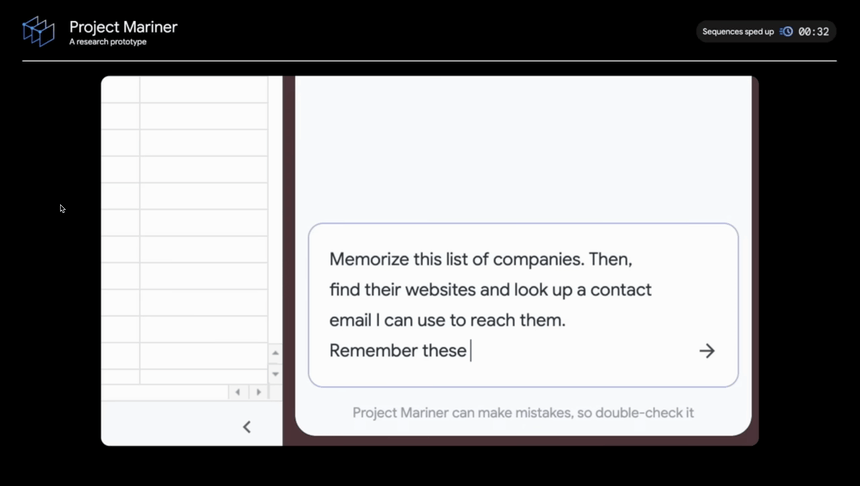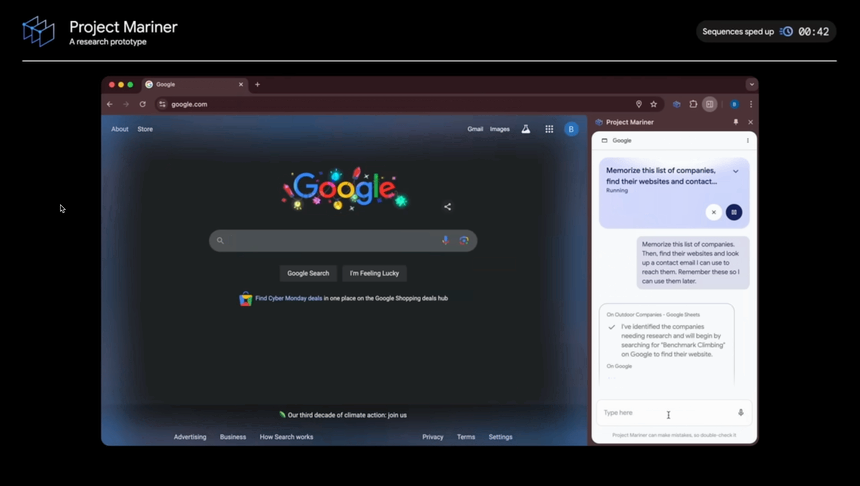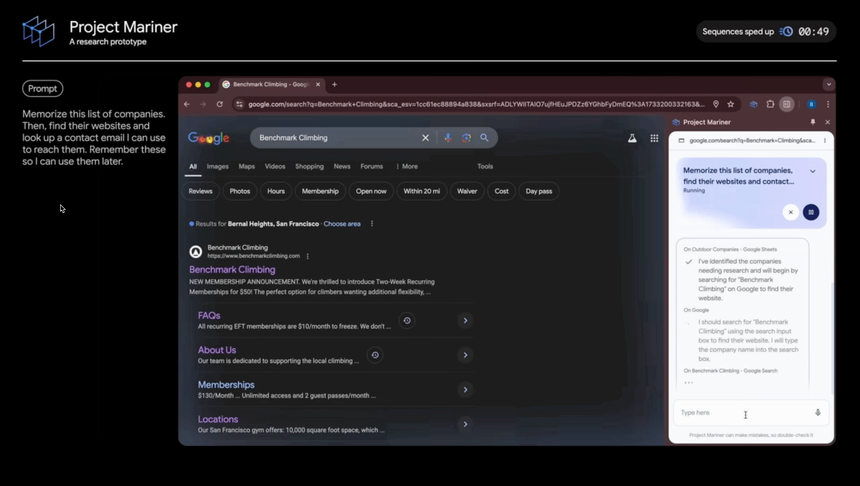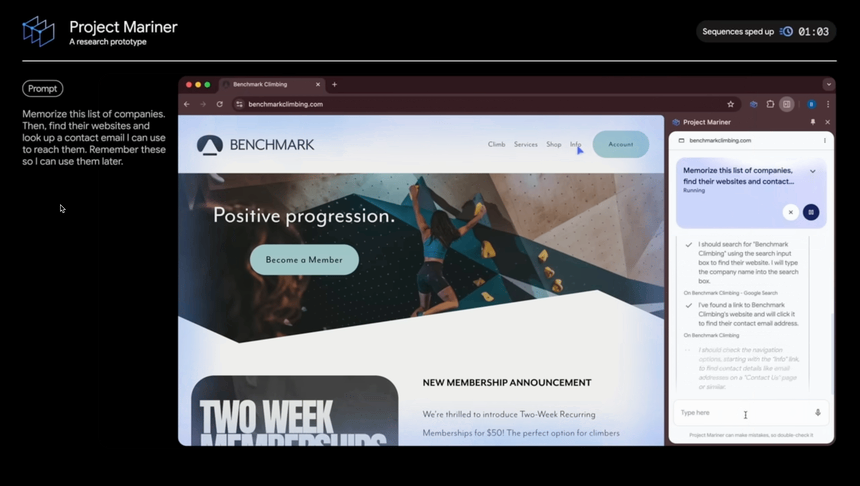
2. 프로젝트 마리너 (Mariner)
최근 Anthropic의 Computer Use와 유사한 기능입니다. Computer Use가 전반적인 컴퓨터 제어에 초점을 맞췄다면, 마리너는 웹 브라우저에 집중했네요. 브라우저 확장 프로그램 형태로 제공되어 설치와 사용이 쉽고, 보안을 위해 권한을 제한한 점도 실용적인 접근으로 보이네요. 특히 화면을 직접 이해하고 작업을 수행할 수 있다는 점에서 웹 브라우징의 새로운 가능성을 보여주고 있습니다.
브라우저 화면의 모든 요소(텍스트, 코드, 이미지, 폼 등)를 실시간으로 이해하고 처리할 수 있으며, 구매와 같은 민감한 작업에서는 반드시 사용자 확인을 받도록 설계된 점도 눈에 띕니다. 이런 안전성 중심의 설계는 실제 업무 환경에서 더욱 신뢰할 수 있는 도구가 될 것 같네요.

- 웹브라우저 화면 실시간 이해
- WebVoyager 벤치마크에서 83.5% 달성
- 안전을 위한 제한된 권한 설정이 인상적
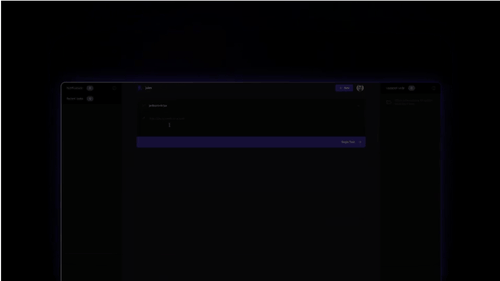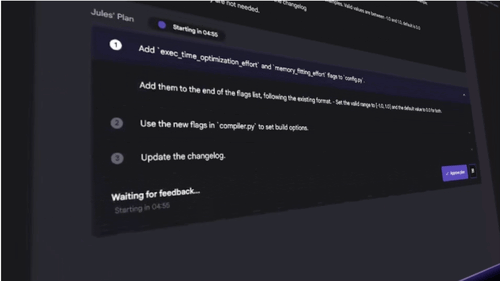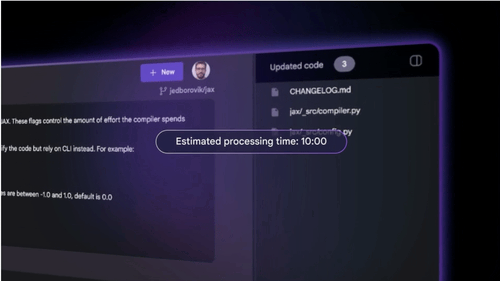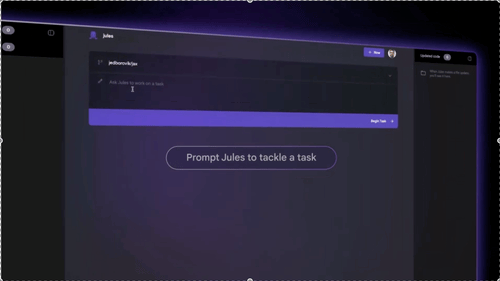
3. 프로젝트 줄스(Jules)
이 기능은 GitHub Copilot과 정면으로 경쟁할 것으로 보이는데, 특히 워크플로우 통합이라는 차별점이 있어 기대가 됩니다. 개발자들이 줄스를 통해 반복적인 작업에서 벗어나 더 창의적인 개발에 집중할 수 있게 될 것 같네요.
- 개발자들의 오랜 꿈이었던 AI 페어 프로그래머
- GitHub 통합으로 실제 개발 워크플로우에 자연스럽게 녹아듦
- 코드 리뷰, 버그 수정, 문서화 작업 지원
- 현재 엄선된 개발 그룹을 통해 테스트를 진행 중
- 2025년 초 공개 예정이며, https://labs.google.com/jules/home에서 대기 신청 가능
- 비동기 개발의 효율성을 위해 문제 분석과 코딩 작업을 Jules에 위임 가능
- Jules가 작성한 코드는 개발자가 쉽게 검토하고 프로젝트에 병합 가능
- 진행 상황을 실시간으로 추적하고 우선순위 조정도 가능
멀티미디어 생성 능력 강화
1. 베오2(Veo2)
- OpenAI의 Sora 출시에 맞춰 공개된 구글의 비디오 생성 AI
- 4K 해상도의 동영상 생성 가능
- 다양한 영화적 기법 지원
- 장르 및 렌즈 지정
- 로우 앵글 추적 샷
- 클로즈업 등 카메라 동작
- 배경 흐림 처리
- 특정 피사체 초점 처리
주목할만한 발전
- 실제 물리 법칙에 대한 이해도 향상
- 인간의 움직임과 표현의 자연스러움 개선
- 사실감과 디테일 크게 향상
- 육안으로 보이지 않는 'SynthID' 워터마크 포함
활용 계획
- 구글랩스의 'VideoFX'로 현재 이용 가능 (대기자 명단에 등록)
- 2024년 유튜브 쇼츠와 다른 제품으로 확장 예정
- 사용자 접근성 점진적 확대 중
특히 Sora가 공개되어 다소 실망스럽다는 평가를 받는 동안, Veo2는 더 정확하고 세밀한 영상을 만들어내며 사용자들의 극찬을 받고 있다는 점이 인상적입니다. 실제 영상을 보면 물리적 움직임이나 카메라 워크가 매우 자연스럽고, 특히 렌즈 효과나 초점 처리 같은 전문적인 영상 기법도 잘 구현해내고 있네요.

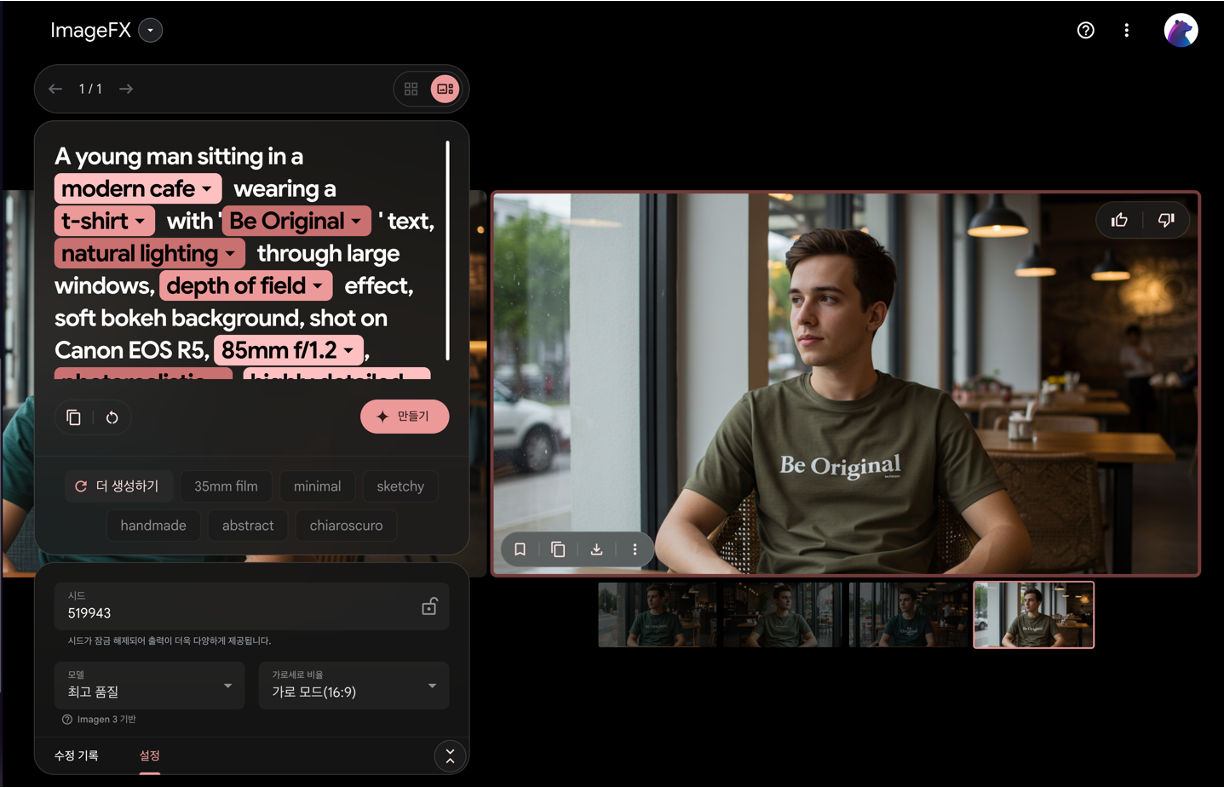
2. 이마젠3(Imagen 3)
주요 특징
- 더 밝고 잘 구성된 이미지 생성 능력
- 다양한 예술 스타일 정확한 구현:
- 인상주의
- 추상적 애니메이션
- 다양한 예술 장르 해석
- 각종 평가에서 경쟁 모델 대비 우수한 성능 기록
활용 방법
- 구글랩스의 'ImageFX'를 통해 즉시 사용 가능
- 위스크(Whisk)와 통합되어 더욱 강력한 기능 제공:
- 특정 주제, 장면, 스타일 기반 이미지 생성
- 다양한 디자인 변형 및 리믹스
- Gemini의 시각적 이해 능력과 결합
혁신적인 점
- Gemini가 이미지의 캡션을 작성하고, 이 설명을 이마젠3에 입력해 결과물 생성
- 더 자연스러운 구도와 조명 처리
- 텍스트 프롬프트에 대한 더 정확한 해석
베오2와 함께 구글의 생성형 AI 라인업을 강화하고 있는 이마젠3는 특히 예술적 표현력이 크게 향상된 것이 특징입니다. DALL-E 3나 Midjourney와 비교해도 손색없는 퀄리티를 보여주고 있죠.
Gemini 2.0 Flash Thinking: 구글의 추론 능력 강화 모델
구글이 Gemini 2.0 Flash의 새로운 버전인 'Flash Thinking'을 예고 없이 공개했습니다. OpenAI의 o3 발표에 맞춰 공개된 이 모델은 현재 Google AI Studio에서 무료로 사용해 볼 수 있는데요.
주요 특징
1. 강화된 추론 능력
- Chain of Thought(사고의 연쇄) 기능 지원
- 문제 해결 과정을 단계별로 보여줌
- o1처럼 내부적으로만 처리하는 것이 아닌, 전체 사고 과정 공개
- 자체 검증 및 수정 능력 보유
2. 성능과 접근성
- LMSYS Chatbot Arena 기준 o1과 동등한 성능 기록
- 무료로 즉시 사용 가능 (API 비용 없음)
- 32,000 토큰 컨텍스트 윈도우 지원
- 텍스트와 이미지 입력 처리 가능
특히 인상적인 점
- 문제를 해결하기 전에 질문을 정확히 이해하려 노력
- 오류를 발견하면 스스로 수정하는 능력
- 복잡한 추론이 필요한 문제도 단계별로 명확하게 해결
- 이미지 기반 추론 문제도 처리 가능
활용 예시
- 수학 문제 해결
- 각 단계별 사고 과정 표시
- 자체 검증 단계 포함
- 오류 발견 시 수정 과정 공개
- 이미지 기반 추론
- 이미지 속 정보 분석
- 시각적 퍼즐 해결
- 단계별 시각적 추론 과정 설명
이번 발표는 구글이 OpenAI의 o3에 대응하는 동시에, 추론 능력에서 한 단계 더 발전된 모습을 보여주었다는 점에서 의미가 있습니다. 특히 무료로 제공된다는 점이 큰 장점이 될 것 같네요.
향후 계획
구글은 2025년 초 더 큰 규모의 모델들과 함께 Gemini 2.0을 정식 출시할 예정이며, 검색 서비스에도 도입될 예정이라고 합니다. 특히 6세대 TPU 트릴리엄을 활용해 더욱 강력한 성능을 제공할 것으로 기대됩니다.
'Insights > IT Trends' 카테고리의 다른 글
| 효과적인 AI 에이전트 구축: Anthropic의 가이드 (0) | 2025.01.01 |
|---|---|
| OpenAI: 12일간의 업데이트 총정리 (1) | 2024.12.22 |
| OpenAI: 12일간의 특별 이벤트 마지막 날, o3와 o3-mini 공개 (1) | 2024.12.21 |
| OpenAI, Santa Mode와 영상 통화가 가능한 Advanced Voice 공개 (0) | 2024.12.14 |
| OpenAI: 강력한 추론 엔진 o1 출시 (0) | 2024.12.06 |
댓글을 사용할 수 없습니다.