간단한 RAG(Retrieval-Augmented Generation) 프로그램 만들기 (Python)
인공지능 기술의 발전으로 대규모 언어 모델(LLM) 이 놀라운 성능을 보여주고 있지만, 여전히 최신 정보 반영이나 특정 도메인 지식 활용에 한계가 있습니다. 이러한 문제를 해결하기 위해 등장한 기술이 바로 RAG(Retrieval-Augmented Generation)입니다. RAG는 '검색 증강 생성'이라고 번역할 수 있으며, LLM의 광범위한 일반 지식과 외부 데이터베이스의 특정 정보를 결합하여 더 정확하고 맥락에 맞는 응답을 생성하는 AI 기술입니다. 이 기술은 최신 정보 반영, 특정 도메인 지식 보강, 환각(Hallucination) 문제 감소 등의 장점을 제공합니다.
이 글에서는 RAG의 기본 원리를 이해하고 테스트해 볼 수 있는 간단한 RAG 프로그램을 만들어보겠습니다. 우리가 만들 프로그램은 다음과 같은 기능을 할 것입니다.
- 사용자가 간단한 문서를 업로드할 수 있습니다.
- 업로드된 문서를 기반으로 벡터 데이터베이스를 생성합니다.
- 사용자가 질문을 입력하면, 관련된 정보를 검색합니다.
- 검색된 정보를 바탕으로 LLM이 답변을 생성합니다.

이 간단한 프로그램을 통해 RAG의 기본 원리를 이해하고, 실제로 어떻게 작동하는지 직접 경험해 볼 수 있을 것입니다. Python을 사용하여 이 RAG 프로그램을 단계별로 만들어보겠습니다.
RAG 프로그램 개발
#1. RAG 시스템 개요
RAG 시스템은 다음과 같은 주요 구성 요소로 이루어집니다.
- 문서 처리기
- 벡터 데이터베이스
- LLM (Large Language Model)
- 사용자 인터페이스
#2. OpenAI API 키 설정
OpenAIEmbeddings 모델을 사용하기 위해서는 OpenAI의 API 키를 설정하는 것이 필수적입니다.
1) OpenAI API Key 발급
OpenAI API 수행을 위해서는 먼저 API Key 발급이 필요합니다. OpenAI 계정이 필요하며 계정이 없다면 계정 생성이 필요합니다. 간단히 Google이나 Microsoft 계정을 연동할 수 있습니다. 이미 계정이 있다면 로그인 후 진행하시면 됩니다.
로그인이 되었다면 우측 상단 Personal -> [ View API Keys ]를 클릭합니다.
[ + Create new secret key ]를 클릭하여 API Key를 생성합니다. API key generated 창이 활성화되면 Key를 반드시 복사하여 두시기 바랍니다. 창을 닫으면 다시 확인할 수 없습니다. (만약 복사하지 못했다면 다시 Create new secret key 버튼을 눌러 생성하면 되니 걱정하지 않으셔도 됩니다.)
2) 환경 변수 설정
API 키를 직접 코드에 포함시키는 것은 보안상 좋지 않습니다. 대신, 운영 체제의 환경 변수에 API 키를 저장하고, 이를 코드에서 불러오는 방식을 권장합니다. 이를 위해 운영 체제의 환경 설정에서 OPENAI_API_KEY라는 이름으로 API 키를 저장합니다. 권장사항일 뿐 필수는 아닙니다
#3. 필요한 라이브러리 설치
RAG 시스템 구현을 위해 다음 라이브러리들을 설치합니다.
pip install gradio langchain langchain-community langchain-core langchain-groq langchain-openai langchain-text-splitters langchain-unstructured openai chromadb pypdf python-magic unstructured pyyaml python-dotenv# 4. 프로젝트 구조 설정
프로젝트 구조는 다음과 같습니다.
simple_rag/ ├── src/ │ ├── document_processor/ │ │ └── document_processor.py │ ├── vector_db/ │ │ └── chroma_db.py │ ├── llm/ │ │ └── model.py │ ├── ui/ │ │ └── gradio_interface.py │ └── utils/ │ └── file_utils.py ├── config/ │ └── config.yaml ├── data/ │ └── (uploaded documents will be stored here) ├── main.py └── requirements.txt
#5. 설정 파일 생성
config/config.yaml 파일을 생성하고 다음과 같이 작성합니다.
# API Keys openai_api_key: "your-openai-api-key" groq_api_key: "your-groq-api-key" # Model Parameters model_name: "mixtral-8x7b-32768" temperature: 0.7 max_tokens: 1000 # File Paths data_dir: "data" vector_db_path: "vector_db" # Chunk Size for Text Splitting chunk_size: 1000 chunk_overlap: 200
#6. 문서 처리기 구현
src/document_processor/document_processor.py 파일을 생성하고 다음과 같이 작성합니다.
from langchain_community.document_loaders import ( PyPDFLoader, UnstructuredFileLoader, UnstructuredExcelLoader, UnstructuredMarkdownLoader, ) from langchain_text_splitters import RecursiveCharacterTextSplitter from config import CONFIG SUPPORTED_EXTENSIONS = ('.pdf', '.txt', '.xlsx', '.xls', '.md', '.markdown') text_splitter = RecursiveCharacterTextSplitter( chunk_size=CONFIG['chunk_size'], chunk_overlap=CONFIG['chunk_overlap'] ) def get_loader_for_file(file_path): if file_path.lower().endswith('.pdf'): return PyPDFLoader(file_path) elif file_path.lower().endswith('.txt'): return UnstructuredFileLoader(file_path) elif file_path.lower().endswith(('.xlsx', '.xls')): return UnstructuredExcelLoader(file_path) elif file_path.lower().endswith(('.md', '.markdown')): return UnstructuredMarkdownLoader(file_path) else: raise ValueError(f"Unsupported file type: {file_path}") def process_document(file_path): loader = get_loader_for_file(file_path) documents = loader.load() return text_splitter.split_documents(documents) def is_supported_file(file_path): return file_path.lower().endswith(SUPPORTED_EXTENSIONS)
#7. 벡터 데이터베이스 설정
src/vector_db/chroma_db.py 파일을 생성하고 다음과 같이 작성합니다.
from langchain_community.vectorstores import Chroma from langchain_openai import OpenAIEmbeddings from config import CONFIG embeddings = OpenAIEmbeddings(openai_api_key=CONFIG['openai_api_key']) def initialize_vector_db(): return Chroma(persist_directory=CONFIG['vector_db_path'], embedding_function=embeddings) vectorstore = initialize_vector_db() def add_documents(documents): vectorstore.add_documents(documents) def similarity_search(query): return vectorstore.similarity_search(query)
#8. LLM 모델 설정
src/llm/model.py 파일을 생성하고 다음과 같이 작성합니다.
from langchain_groq import ChatGroq from langchain_core.prompts import ChatPromptTemplate from langchain_core.output_parsers import StrOutputParser from langchain_core.runnables import RunnablePassthrough from config import CONFIG def initialize_llm(model_name=None): model_name = model_name or CONFIG['default_model'] return ChatGroq( groq_api_key=CONFIG['groq_api_key'], model_name=model_name, temperature=CONFIG['temperature'], max_tokens=CONFIG['max_tokens'] ) llm = initialize_llm() # RAG prompt rag_prompt = ChatPromptTemplate.from_template(""" 다음 컨텍스트를 바탕으로 질문에 답변하세요: {context} 질문: {question} 답변을 한국어로 제공해 주세요. """) # RAG chain def create_rag_chain(): global llm rag_chain = ( {"context": lambda x: x["context"], "question": lambda x: x["question"]} | rag_prompt | llm | StrOutputParser() ) return rag_chain rag_chain = create_rag_chain() def change_model(model_name): global llm, rag_chain llm = initialize_llm(model_name) rag_chain = create_rag_chain() return f"Model changed to {model_name}" def process_with_rag(question, context): return rag_chain.invoke({"question": question, "context": context})
#9. Gradio 인터페이스 구현
src/ui/gradio_interface.py 파일을 생성하고 다음과 같이 작성합니다.
import gradio as gr from config import CONFIG from src.llm.model import change_model, process_with_rag from src.vector_db.chroma_db import similarity_search from src.utils.file_utils import add_file, get_file_list, initialize_files from src.document_processor.document_processor import SUPPORTED_EXTENSIONS import asyncio async def process_message(message, history): context = similarity_search(message) response = process_with_rag(message, context) return response async def type_message(message, delay=0.0005): for i in range(len(message) + 1): yield message[:i] await asyncio.sleep(delay) def create_interface(): with gr.Blocks() as demo: gr.Markdown("# 🌀 Simple RAG") gr.Markdown("This program uses Retrieval-Augmented Generation to answer questions based on uploaded PDF " "documents. It combines information retrieval with language generation to provide accurate and " "context-aware responses.") with gr.Row(): with gr.Column(scale=3): chatbot = gr.Chatbot( [], elem_id="chatbot", avatar_images=("asset/images/user.png", "asset/images/chatbot.png"), bubble_full_width=False, height=400 ) msg = gr.Textbox(show_label=False, placeholder="Enter your message...") clear = gr.ClearButton([msg, chatbot]) with gr.Column(scale=1): model_dropdown = gr.Dropdown(choices=CONFIG['llm_models'], value=CONFIG['default_model'], label="Select LLM Model") model_status = gr.Markdown("Current Model: " + CONFIG['default_model']) with gr.Tabs(): with gr.TabItem("Current Files"): file_output = gr.Textbox(label="Current Files") with gr.TabItem("Upload Status"): upload_status = gr.Textbox(label="Upload Status") file_upload = gr.File(label=f"Drop files here (Supported: {', '.join(SUPPORTED_EXTENSIONS)})", file_types=list(SUPPORTED_EXTENSIONS)) async def respond(message, chat_history): bot_message = await process_message(message, chat_history) chat_history.append((message, "")) async for partial_message in type_message(bot_message): chat_history[-1] = (message, partial_message) yield "", chat_history, get_file_list() def handle_file_upload(file): status, _, file_list = add_file(file) return status, file_list, None # None을 반환하여 file_upload를 초기화 msg.submit(respond, [msg, chatbot], [msg, chatbot, file_output]) file_upload.upload(handle_file_upload, file_upload, [upload_status, file_output, file_upload]) model_dropdown.change(change_model, model_dropdown, model_status) demo.load(initialize_files, outputs=file_output) return demo def launch_interface(): demo = create_interface() demo.launch()

- Chat Interface: 사용자와 AI의 대화 내용이 표시됩니다.
- Message Input: 사용자가 질문을 입력할 수 있는 텍스트 상자입니다.
- Clear Button: 채팅 내역을 초기화할 수 있는 버튼입니다.
- Model Selection: 사용할 LLM 모델을 선택할 수 있는 드롭다운 메뉴입니다.
- Reference Documents: 현재 참조할 수 있는 문서 목록을 보여주는 텍스트 영역입니다.
- File Upload: 사용자가 문서를 드래그 앤 드롭하거나 선택하여 업로드할 수 있는 영역입니다.
#10. 메인 실행 파일 작성
프로젝트 루트에 main.py 파일을 생성하고 다음과 같이 작성합니다.
from src.ui.gradio_interface import launch_interface if __name__ == "__main__": launch_interface()
# 11. 실행
이제 모든 준비가 완료되었습니다. 다음 명령어로 RAG 시스템을 실행합니다.
python main.py브라우저에서 http://localhost:7860 으로 접속하면 Gradio 인터페이스가 표시됩니다. 이제 문서를 업로드하고 질문을 입력하여 RAG 시스템을 사용할 수 있습니다.
RAG 테스트 (차량 매뉴얼 질의응답)
차량 매뉴얼 PDF를 사용하여 RAG 시스템의 효과를 테스트해 보았습니다. 사용한 모델은 Groq에서 제공하는 Llama3-8b-8192입니다.
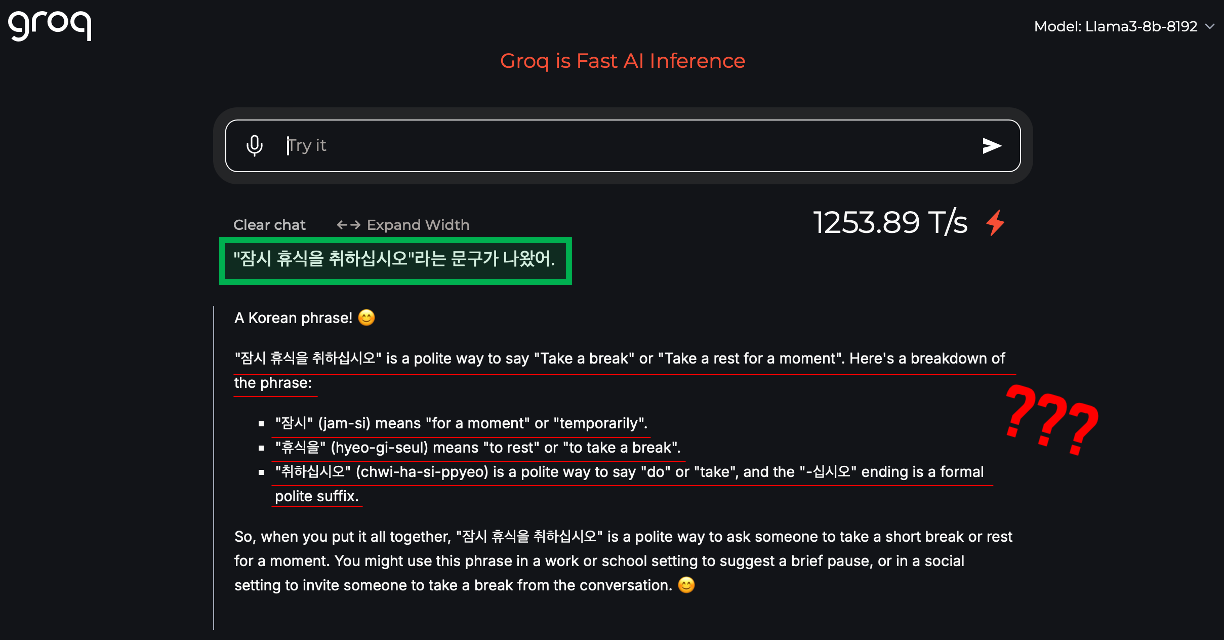
#1. RAG 없이 LLM만 사용한 경우
LLM은 다음과 같은 일반적인 응답을 제공했습니다. 응답을 살펴보면, 문구의 언어학적 설명에 그쳤으며, 차량 매뉴얼의 맥락을 전혀 반영하지 못했습니다.
#2. RAG를 사용한 경우
RAG 시스템은 다음과 같은 구체적이고 정확한 응답을 제공했습니다. 이 응답은 PDF의 다음 내용을 정확히 참조했습니다.
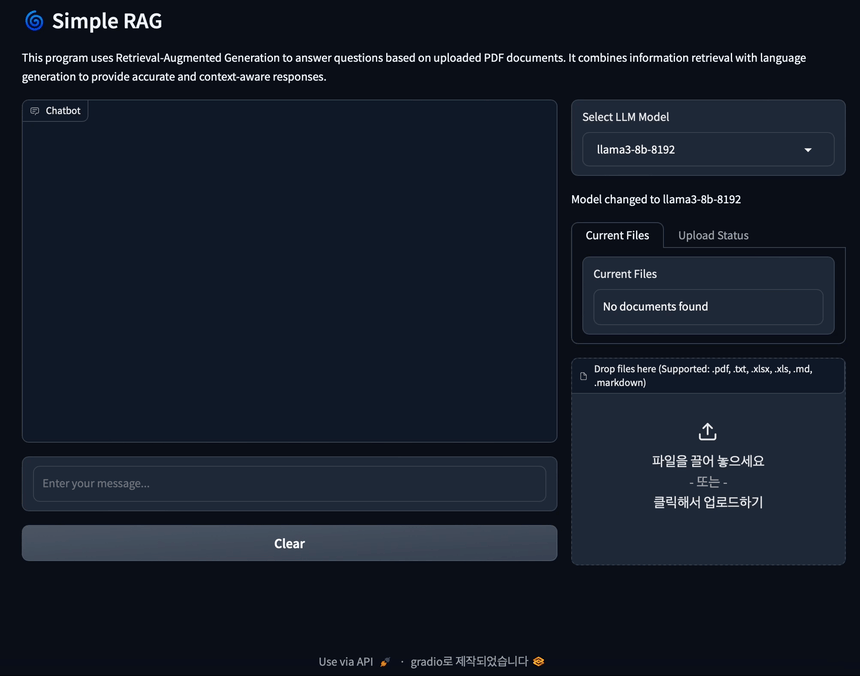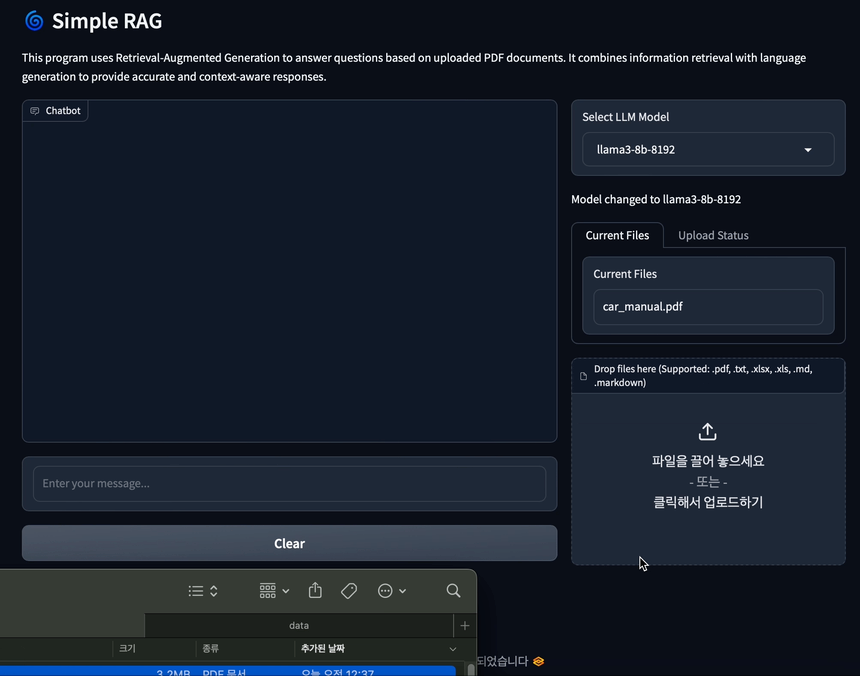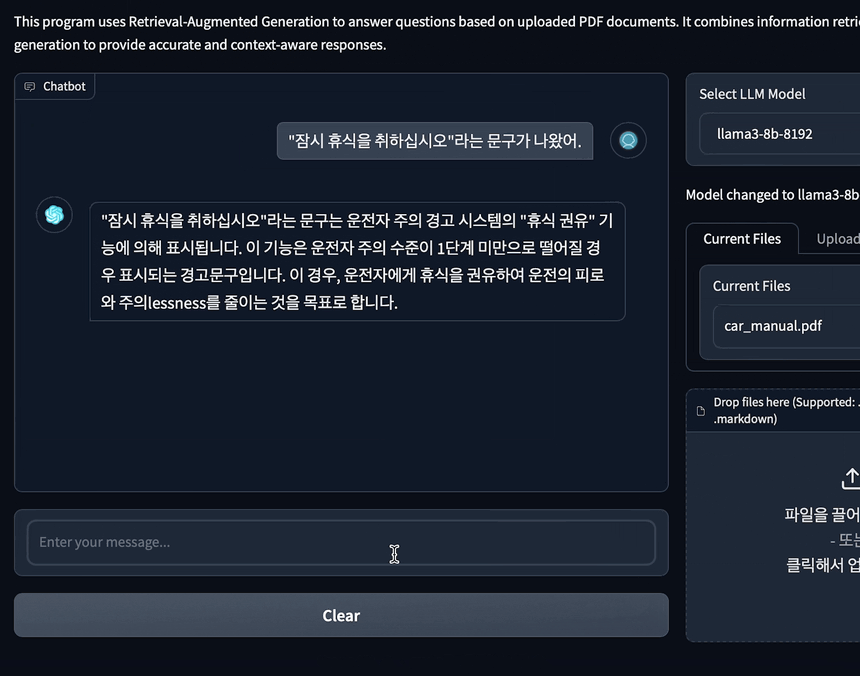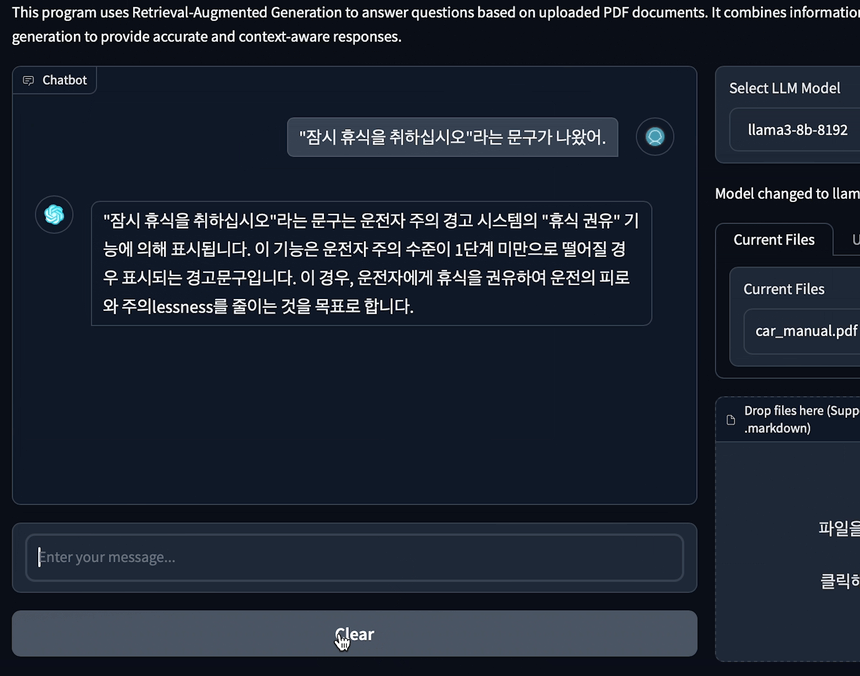
특히 흥미로운 점은 "잠시 휴식을 취하십시오"라는 문구가 실제로는 텍스트가 아니라 차량 디스플레이에 노출되는 이미지라는 것입니다.

RAG 시스템이 특정 도메인의 정보를 처리하는 데 있어 LLM의 성능을 크게 향상할 수 있음을 보여줍니다. 특히 기술 문서, 매뉴얼 등 특정 맥락이 중요한 정보를 다룰 때 RAG의 활용이 매우 효과적일 수 있습니다.
간단한 RAG 프로그램을 개발해 보았습니다. 이 프로그램은 사용자의 질문에 대해 관련 문서를 검색하고, 이를 바탕으로 LLM이 답변을 생성합니다. 실제 운영 환경에서는 보안, 확장성, 성능 최적화 등 추가적인 고려사항이 필요할 수 있습니다. RAG 기술은 AI 시스템의 정확성과 신뢰성을 크게 향상하는 혁신적인 접근 방식으로, 앞으로 더욱 발전할 것으로 기대됩니다.
'Tech & Development > AI' 카테고리의 다른 글
| Perplexity AI 사용 방법: AI 검색의 새로운 지평 (SKT 고객 1년 무료 Pro 혜택 포함) (2) | 2024.09.09 |
|---|---|
| Napkin.ai: 아이디어를 시각화하는 AI 노트 앱 (1) | 2024.09.08 |
| CodeGemma 활용 가이드: Gemma 기반의 코드 생성 모델 (4) | 2024.05.19 |
| 다양한 LLM을 이용한 웹 테스트 자동화 (LaVague) - Python (0) | 2024.03.23 |
| YOLOv9 Custom Data 학습 가이드 (24) | 2024.03.18 |
댓글을 사용할 수 없습니다.