나만의 ChatGPT Plugin 만들기: NAVER 검색엔진
ChatGPT의 Plugin은 사용자가 자신만의 맞춤형 기능을 개발할 수 있는 강력한 도구입니다. 이전 글에서는 간단하게 Local DB에 저장하는 TODO 리스트 Plugin을 만드는 방법을 소개했습니다.
나만의 ChatGPT Plugin 만들기: TODO List (No Auth)
OpenAI의 ChatGPT는 확장 가능한 구조를 가지고 있습니다. 특히 OpenAI는 Plugin이라는 기능을 제공하는데 이는 사용자가 매우 빠르고 간단하게 나만의 기능을 구축할 수 있게 해줍니다. OpenAI에서 소개
yunwoong.tistory.com
ChatGPT는 2021년 9월까지의 데이터로 생성된 모델로, 그 이후의 정보나 실시간 업데이트 되는 정보에는 제한이 있었습니다. 이러한 한계를 극복하기 위해, ChatGPT는 “Browse with Bing” Plugin을 통해 인터넷 검색 기능을 제공하고 이를 통해 사용자는 다양한 정보에 실시간으로 접근할 수 있게 하였습니다.

그러나, 한국 사용자 중 많은 이들이 NAVER 검색엔진에 익숙하고, 이를 통해 정보를 검색하는 경우가 빈번합니다. NAVER는 특정 지역적 정보나 한국어 특화 콘텐츠에서 더 정확하고 다양한 결과를 제공할 수 있는 장점을 가지고 있습니다. 이번에는 ChatGPT 내에서 직접 NAVER 검색 결과를 조회하고 제공할 수 있는 Plugin을 개발하는 방법을 소개하려 합니다.
#1. 사전준비
1) NAVER Client ID와 Secret ID 발급받기
NAVER 검색 API를 사용하기 위해서는 먼저 NAVER 개발자 센터에서 애플리케이션을 등록하여 Client ID와 Secret ID를 발급받아야 합니다. Client ID와 Secret ID는 NAVER의 검색 서비스에 접근하기 위해 필요한 중요한 키이므로, 안전하게 보관하고 관리하셔야 합니다.
NAVER Developers
네이버 오픈 API들을 활용해 개발자들이 다양한 애플리케이션을 개발할 수 있도록 API 가이드와 SDK를 제공합니다. 제공중인 오픈 API에는 네이버 로그인, 검색, 단축URL, 캡차를 비롯 기계번역, 음
developers.naver.com
NAVER 계정으로 로그인한 후, 'Application > 애플리케이션 등록'을 선택합니다.
애플리케이션 이름, 사용 API, Redirect URI 등 필요한 정보를 입력하고, '등록하기' 버튼을 클릭합니다.
애플리케이션 등록 후, 발급된 Client ID와 Secret ID를 확인할 수 있습니다. 이 정보를 복사하여 안전한 곳에 저장합니다.
이제 이 정보를 사용하여 NAVER 검색 API에 접근하고, 원하는 검색 결과를 ChatGPT Plugin을 통해 가져올 수 있습니다.
2) 비로그인방식 오픈 API
NAVER에서 제공하는 검색 API 요청 URL과 메서드, 응답 형식입니다. 이번 예시에서는 여러 검색 API 중 'news' (뉴스), 'blog' (블로그), 'kin' (지식인), 'local' (지역 검색), 'image' (이미지 검색), 'shop' (쇼핑 검색) 카테고리의 API를 활용해보고자 합니다.
네이버 오픈API 종류 - Open API 가이드
네이버 오픈API 종류 네이버 오픈API는 인증 여부에 따라 로그인 방식 오픈 API와 비로그인 방식 오픈 API로 구분됩니다. 로그인 방식 오픈 API 로그인 방식 오픈 API는 '네이버 로그인'의 인증을 받아
developers.naver.com
| 요청 URL | 메서드 | 응답 형식 | 설명 |
| https://openapi.naver.com/v1/search/news | GET | JSON, XML | 네이버 검색의 뉴스 검색 결과를 반환합니다. |
| https://openapi.naver.com/v1/search/encyc | GET | JSON, XML | 네이버 검색의 백과사전 검색 결과를 반환합니다. |
| https://openapi.naver.com/v1/search/blog | GET | JSON, XML | 네이버 검색의 블로그 검색 결과를 반환합니다. |
| https://openapi.naver.com/v1/search/shop | GET | JSON, XML | 네이버 검색의 쇼핑 검색 결과를 반환합니다. |
| https://openapi.naver.com/v1/search/movie | GET | JSON, XML | 네이버 검색의 영화 검색 결과를 반환합니다. |
| https://openapi.naver.com/v1/search/webkr | GET | JSON, XML | 네이버 검색의 웹 문서 검색 결과를 반환합니다. |
| https://openapi.naver.com/v1/search/image | GET | JSON, XML | 네이버 검색의 이미지 검색 결과를 반환합니다. |
| https://openapi.naver.com/v1/search/doc | GET | JSON, XML | 네이버 검색의 전문정보 검색 결과를 반환합니다. |
| https://openapi.naver.com/v1/search/kin | GET | JSON, XML | 네이버 검색의 지식iN 검색 결과를 반환합니다. |
| https://openapi.naver.com/v1/search/book | GET | JSON, XML | 네이버 검색의 책 검색 결과를 반환합니다. |
| https://openapi.naver.com/v1/search/cafearticle | GET | JSON, XML | 네이버 검색의 카페글 검색 결과를 반환합니다. |
| https://openapi.naver.com/v1/search/adult | GET | JSON, XML | 입력한 검색어가 성인 검색어인지 판별한 결과를 반환합니다. |
| https://openapi.naver.com/v1/search/errata | GET | JSON, XML | 입력한 검색어의 한영 오류를 변환한 결과를 반환합니다. |
| https://openapi.naver.com/v1/search/local | GET | JSON, XML | 네이버 지역 서비스에 등록된 지역별 업체 및 상호 검색 결과를 반환합니다. |
#2. 환경구성
1) python은 3.10 버전 설치 (가상환경)
conda create -n test_env python=3.102) 가상환경 활성화
conda activate test_env3) ChatGPT_Plugin_Naver_search Fork
GitHub에서 https://github.com/yunwoong7/ChatGPT_Plugin_Naver_search 주소로 이동합니다.
오른쪽 상단에 있는 'Fork' 버튼을 클릭하여 자신의 계정에 Fork를 생성합니다.
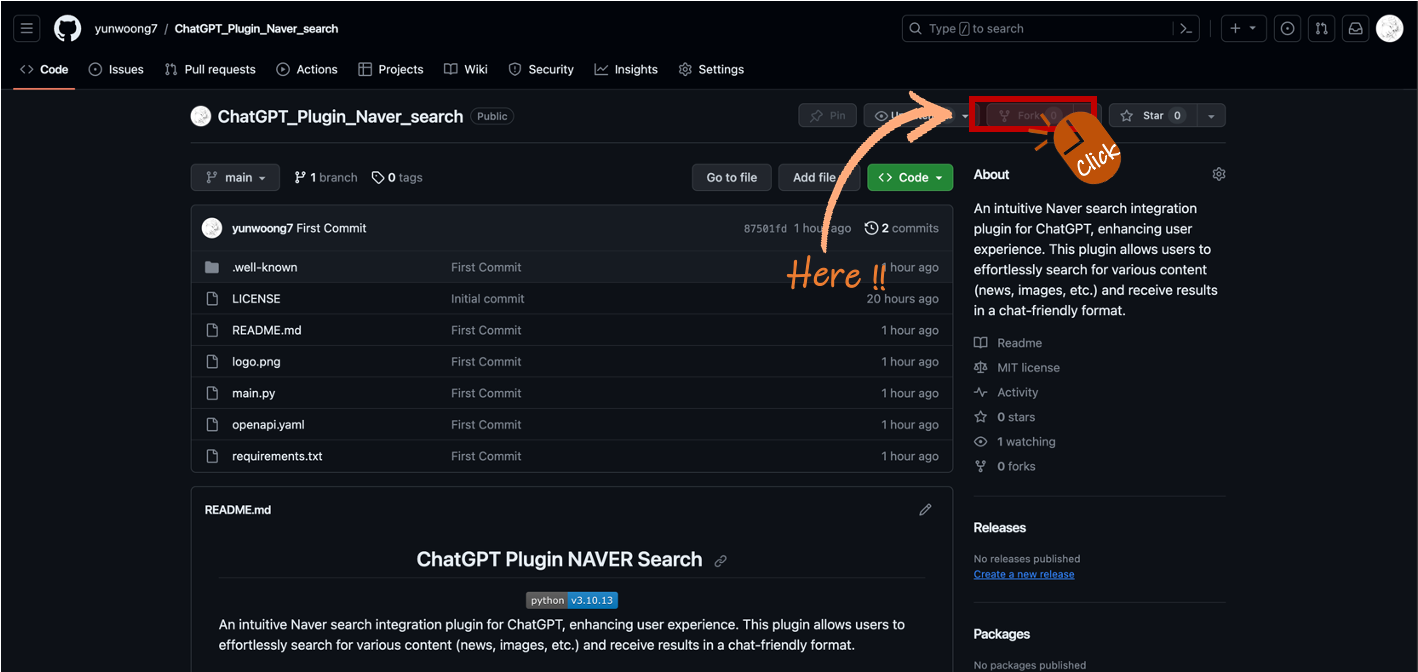
4) Fork 한 ChatGPT_Plugin_Naver_search Download
여기서 [YOUR_USERNAME]은 GitHub 사용자 이름으로 대체해 주세요.
git clone https://github.com/[YOUR_USERNAME]/ChatGPT_Plugin_Naver_search.git cd /ChatGPT_Plugin_Naver_search
5) install package
필요한 패키지를 설치합니다.
pip install quart pip install quart-cors
#3. Source code
1) ai-plugin.json
ai-plugin.json 파일입니다. 파일의 경로는 .well-known 폴더 하위에 있습니다.
{ "schema_version": "v1", "name_for_human": "Naver Search Integration", "name_for_model": "naver", "description_for_human": "Perform searches on Naver for various content types including news and blogs.", "description_for_model": "Plugin for searching content on Naver, including news articles and blog posts.", "auth": { "type": "none" }, "api": { "type": "openapi", "url": "http://localhost:5002/openapi.yaml" }, "logo_url": "http://localhost:5002/logo.png", "contact_email": "legal@example.com", "legal_info_url": "http://example.com/legal" }
2) openapi.yaml
Open API 문서입니다. 이 문서는 API의 엔드포인트, 요청 및 응답 형식, 사용 가능한 스키마 등에 대한 정보를 제공합니다. openapi.yaml 파일은 내용이 너무 일어서 여기 예시에는 news와 blog 검색만 작성했습니다. 더 자세한 내용은 여기를 참고하세요.
OpenAPI 문서에서 $ref를 사용하여 중복을 줄이고 구조를 더 효율적으로 만들 수 있습니다. $ref는 공통 구성 요소를 정의하고 이를 여러 경로에서 재사용할 수 있게 해주는 기능입니다. 이를 통해 문서의 가독성이 향상되고 유지 관리가 용이해집니다.
- components/schemas 아래에 공통 응답 객체를 정의합니다.
- 각 경로의 응답에서 이 공통 객체를 참조합니다.
예를 들어 "news" 검색 기능을 추가하려면 기존의 OpenAPI 스펙에 경로를 추가해야 합니다. 이 경로는 새로운 엔드포인트에 대한 정의를 포함하며, 요청에 필요한 파라미터, 응답 형식 및 오류 메시지 등의 정보를 담고 있습니다. parameters의 대한 정의는 NAVER API 가이드를 참고하여 만들었습니다.
openapi: 3.0.1 info: title: Naver Search ChatGPT Plugin description: A plugin that enhances ChatGPT with the capability to perform searches on Naver for various content types including news and blogs. version: v1 servers: - url: 'http://localhost:5002' paths: /news: get: summary: "Search for news articles based on the query." operationId: "searchNews" parameters: - name: "query" in: "query" description: "Search keywords." required: true schema: type: "string" - name: "display" in: "query" description: "Number of results to display." required: false schema: type: "integer" default: 10 maximum: 100 - name: "start" in: "query" description: "Index of the first result to return." required: false schema: type: "integer" default: 1 maximum: 1000 - name: "sort" in: "query" description: "Sort order of results." required: false schema: type: "string" enum: [ "sim", "date" ] default: "sim" responses: '200': description: Successful response with news articles. content: application/json: schema: $ref: '#/components/schemas/CommonResponse' '400': $ref: '#/components/responses/BadRequest' '500': $ref: '#/components/responses/InternalServerError' /blog: get: summary: "Search for blog posts based on the query." operationId: "searchBlog" parameters: - name: "query" in: "query" description: "Search keywords." required: true schema: type: "string" - name: "display" in: "query" description: "Number of results to display." required: false schema: type: "integer" default: 10 maximum: 100 - name: "start" in: "query" description: "Index of the first result to return." required: false schema: type: "integer" default: 1 maximum: 1000 - name: "sort" in: "query" description: "Sort order of results." required: false schema: type: "string" enum: [ "sim", "date" ] default: "sim" responses: '200': description: Successful response with blog posts. content: application/json: schema: $ref: '#/components/schemas/CommonResponse' '400': $ref: '#/components/responses/BadRequest' '500': $ref: '#/components/responses/InternalServerError' components: schemas: CommonResponse: type: object properties: lastBuildDate: type: string format: date-time description: The date and time when the response was last updated. total: type: integer description: The total number of search results. start: type: integer description: The starting index of the current page of results. display: type: integer description: The number of results displayed on the current page. items: type: array items: type: object additionalProperties: true # Since fields can vary, we accept additional properties. required: - lastBuildDate - total - start - display - items responses: BadRequest: description: Bad request. The request parameters are incorrect. content: application/json: schema: type: object properties: error: type: string description: Error message describing what went wrong. required: - error InternalServerError: description: Internal server error. content: application/json: schema: type: object properties: error: type: string description: Error message describing what went wrong. required: - error
3) main.py
사전단계에서 준비한 NAVER의 Client ID와 Secret ID를 입력합니다. /news, /blog, /image, /shop, /kin, /local 경로를 처리하는 별도의 엔드포인트를 설정합니다. 각 함수는 적절한 쿼리 파라미터를 수집하고, 이를 사용하여 외부 API에 요청을 보낸 다음, 결과를 JSON 형식으로 반환합니다. requests.get 호출에 params 인자를 사용하면, 요청할 때 쿼리 문자열 파라미터를 자동으로 URL 인코딩하고 구성할 수 있습니다.
import os import json import requests import quart import quart_cors from quart import request, Response app = quart_cors.cors(quart.Quart(__name__), allow_origin="https://chat.openai.com") # 네이버 API에 요청을 보내기 위한 기본 URL 및 헤더 정보 HOST_URL = "https://openapi.naver.com/v1/search" client_id = "YOUR_NAVER_CLIENT_ID" client_secret = "YOUR_NAVER_CLIENT_SECRET" headers = { "X-Naver-Client-Id": client_id, "X-Naver-Client-Secret": client_secret, } @app.route("/news") async def get_news(): query = request.args.get("query") display = request.args.get("display") start = request.args.get("start") sort = request.args.get("sort") params = {"query": query, "display": display, "start": start, "sort": sort} res = requests.get(f"{HOST_URL}/news", headers=headers, params=params) body = res.json() return Response(response=json.dumps(body), status=res.status_code, mimetype="application/json") @app.route("/blog") async def get_blog_posts(): query = request.args.get("query") display = request.args.get("display") start = request.args.get("start") sort = request.args.get("sort") params = {"query": query, "display": display, "start": start, "sort": sort} res = requests.get(f"{HOST_URL}/blog", headers=headers, params=params) body = res.json() return Response(response=json.dumps(body), status=res.status_code, mimetype="application/json") @app.route("/image") async def get_images(): query = request.args.get("query") display = request.args.get("display") start = request.args.get("start") sort = request.args.get("sort") filter = request.args.get("filter") params = {"query": query, "display": display, "start": start, "sort": sort, "filter": filter} res = requests.get(f"{HOST_URL}/image", headers=headers, params=params) body = res.json() return Response(response=json.dumps(body), status=res.status_code, mimetype="application/json") @app.route("/shop") async def search_shop(): query = request.args.get('query') display = request.args.get('display') start = request.args.get('start') sort = request.args.get('sort') filter = request.args.get('filter') exclude = request.args.get('exclude') params = { 'query': query, 'display': display, 'start': start, 'sort': sort, 'filter': filter, 'exclude': exclude } res = requests.get(f"{HOST_URL}/shop", headers=headers, params=params) # 비동기가 아닌 동기 호출을 사용합니다. body = res.json() return Response(response=json.dumps(body), status=res.status_code, mimetype="application/json") @app.route("/kin") async def search_kin(): query = request.args.get('query') display = request.args.get('display') start = request.args.get('start') sort = request.args.get('sort') params = { 'query': query, 'display': display, 'start': start, 'sort': sort } res = requests.get(f"{HOST_URL}/kin", headers=headers, params=params) body = res.json() return Response(response=json.dumps(body), status=res.status_code, mimetype="application/json") @app.route("/local") async def get_local(): query = request.args.get('query') display = request.args.get('display') start = request.args.get('start') sort = request.args.get('sort') params = { 'query': query, 'display': display, 'start': start, 'sort': sort } res = requests.get(f"{HOST_URL}/local", headers=headers, params=params) body = res.json() return Response(response=json.dumps(body), status=res.status_code, mimetype="application/json") @app.get("/logo.png") async def plugin_logo(): filename = 'logo.png' return await quart.send_file(filename, mimetype='image/png') @app.get("/.well-known/ai-plugin.json") async def plugin_manifest(): host = request.headers['Host'] with open("./.well-known/ai-plugin.json") as f: text = f.read() return quart.Response(text, mimetype="text/json") @app.get("/openapi.yaml") async def openapi_spec(): host = request.headers['Host'] with open("openapi.yaml") as f: text = f.read() return quart.Response(text, mimetype="text/yaml") def main(): app.run(debug=True, host="localhost", port=5002) if __name__ == "__main__": main()
#3. 수행
python main.py아래는 Quart 애플리케이션을 실행했을 때의 예시 출력입니다.

#4. Plugins 활성화
Plugins이 비활성 상태라면 활성화가 필요합니다. Plugins를 활성화하는 방법은 간단합니다. Settings 메뉴에서 Beta features 섹션을 선택하고, Plugins를 클릭하면 됩니다. 활성화하고 나면, GPT-4 하위 항목에서 'Plugins'를 선택할 수 있게 됩니다.
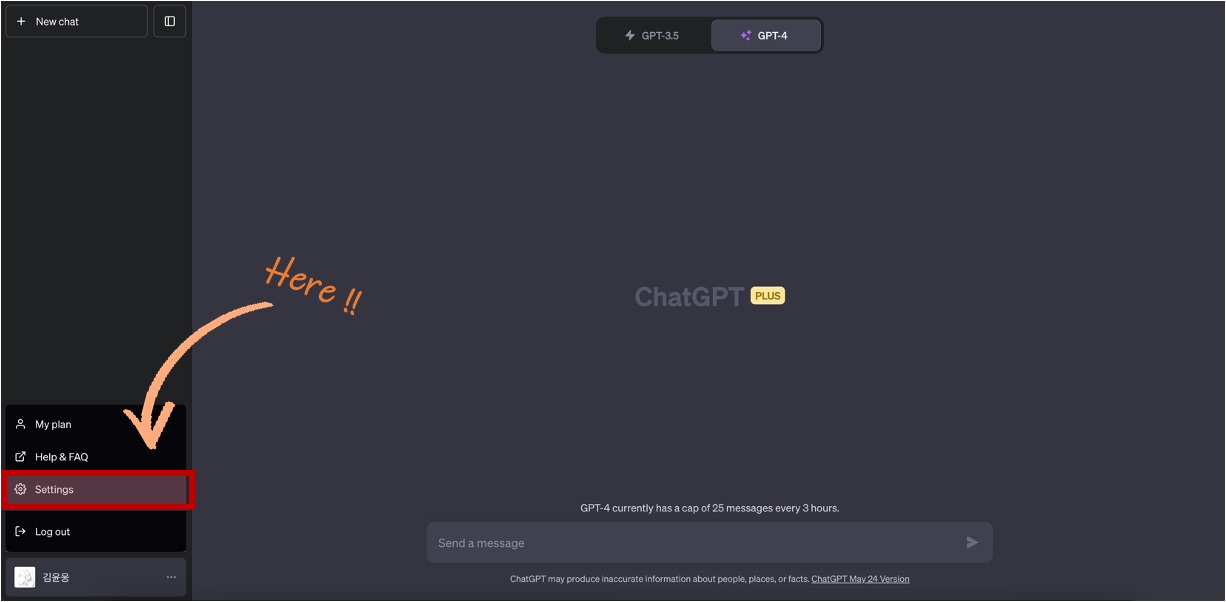
[ Settings ]를 클릭하면 Settings 화면이 열립니다.
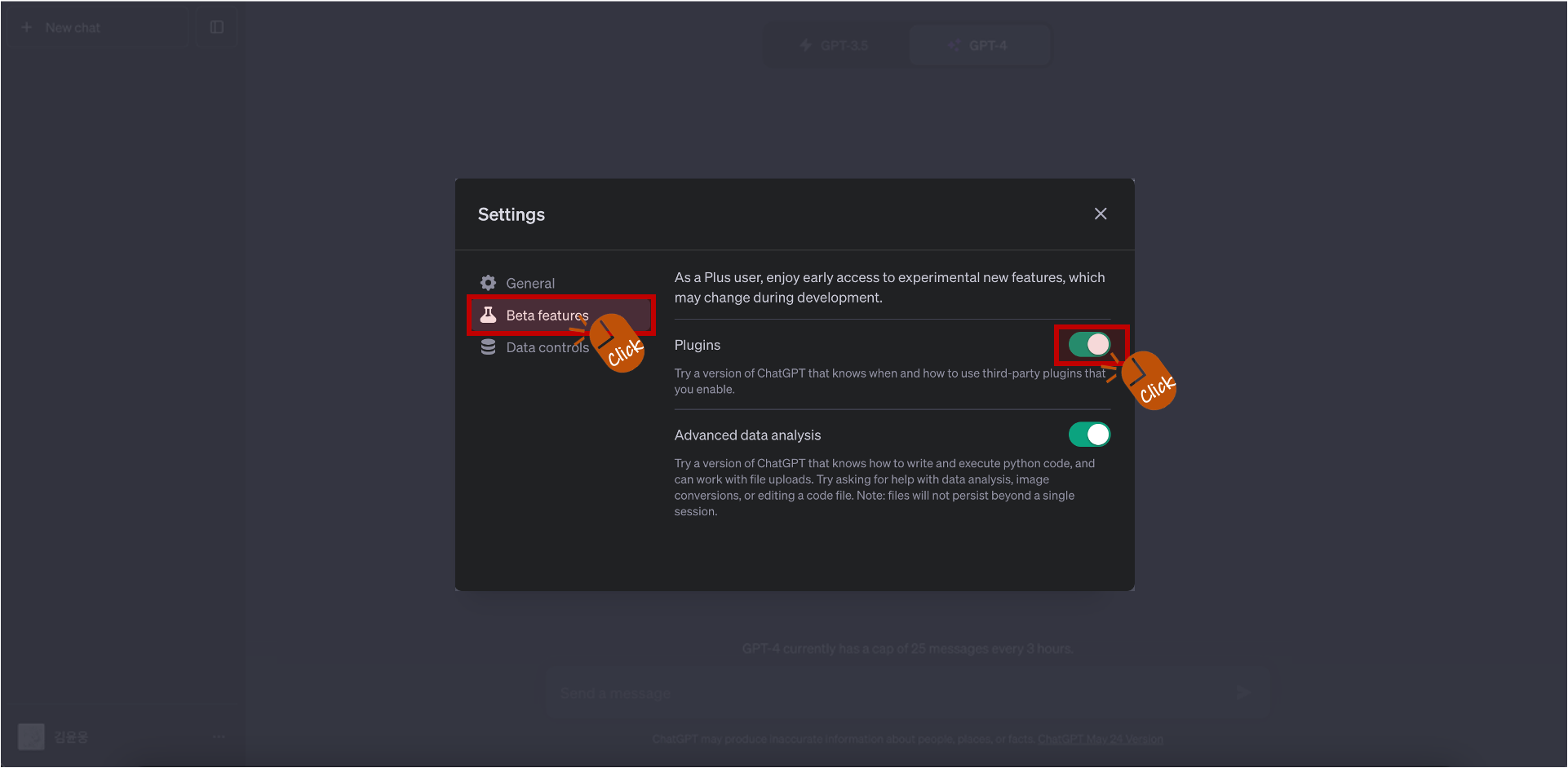
[ Beta features ]를 클릭하고 Plugins을 클릭하여 활성화합니다.
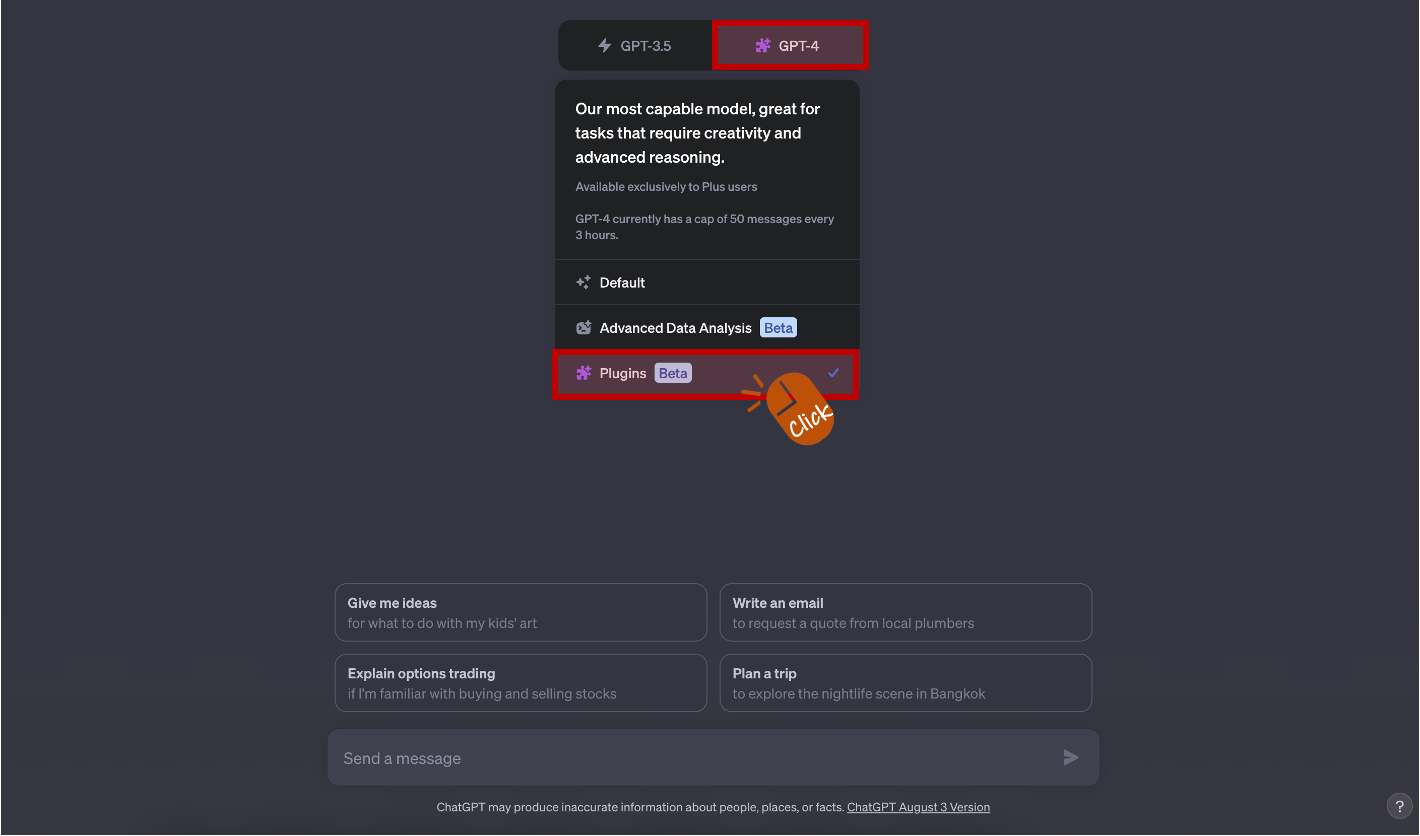
Plugins을 사용할 수 있는 경우 GPT-4 하위 항목에서 'Plugins (Beta)'를 선택할 수 있습니다.
#5. ChatGPT Plugin NAVER search 설치하기 (Localhost)
설치 전 python main.py를 실행하여 수행 중이어야 합니다. 이제 Local NAVER search Plugin을 설치하도록 하겠습니다.
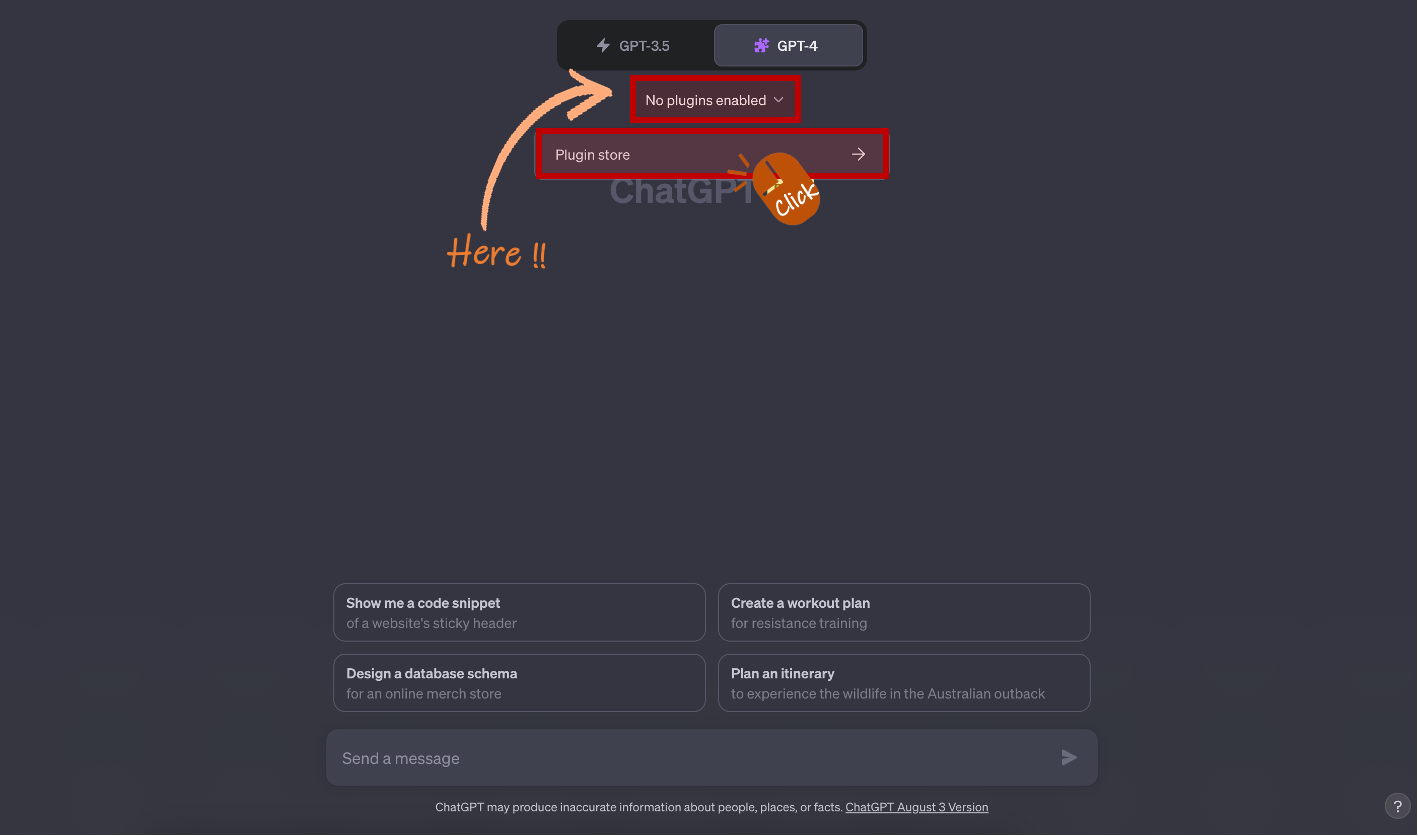
Plugins (Beta)를 클릭하면 "No plugins enabled" 메시지가 표시됩니다. 만약 이전에 설치한 Plugin이 있다면 해당 Plugin 목록이 보일 것입니다. 저는 모든 Plugin을 삭제한 상태이므로 해당 메시지만 보입니다. Plugin을 추가하기 위해서 "Plugin store" 버튼을 클릭합니다.
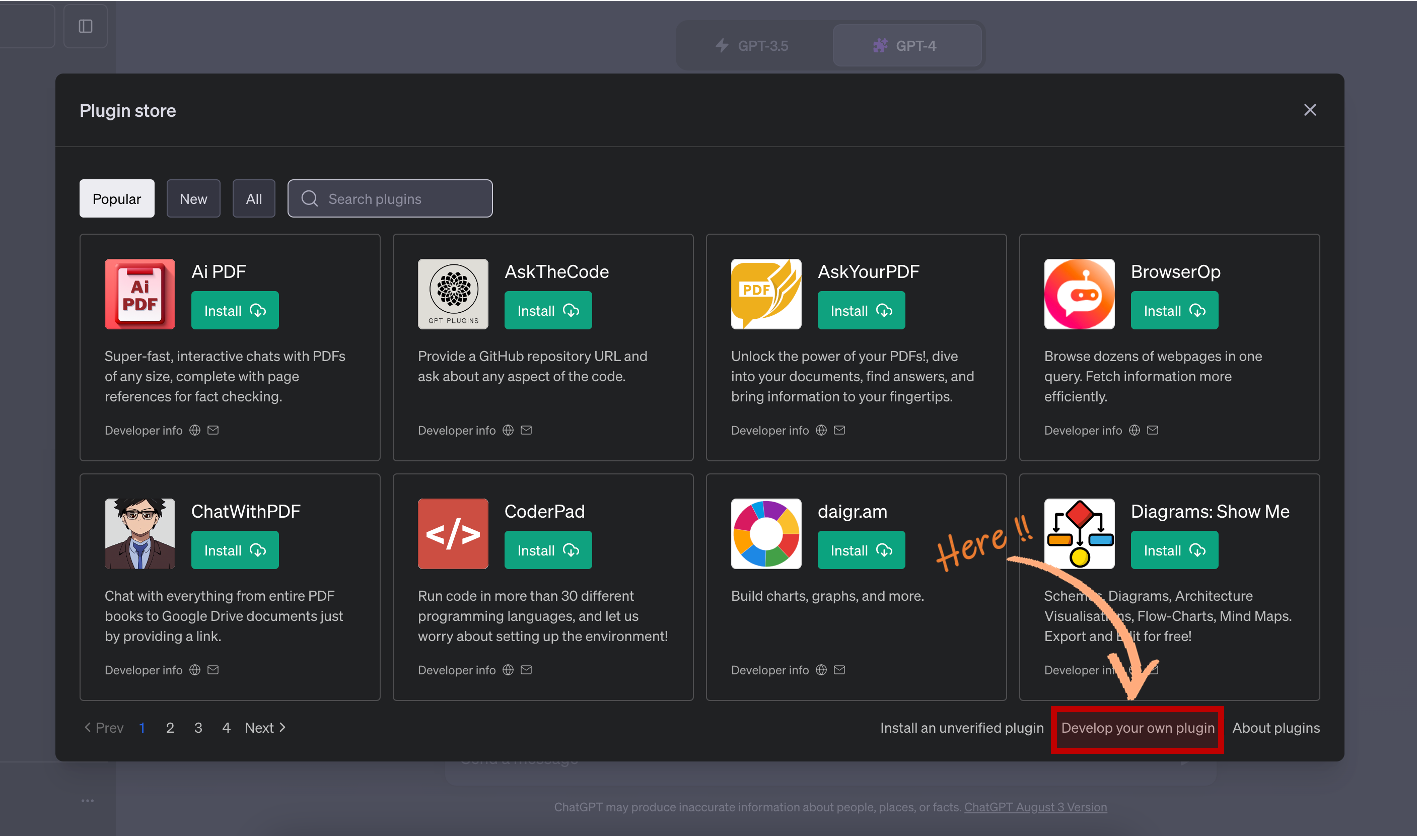
Plugin store에서 우측 하단에 "Develop you own plugin" 버튼을 클릭합니다.
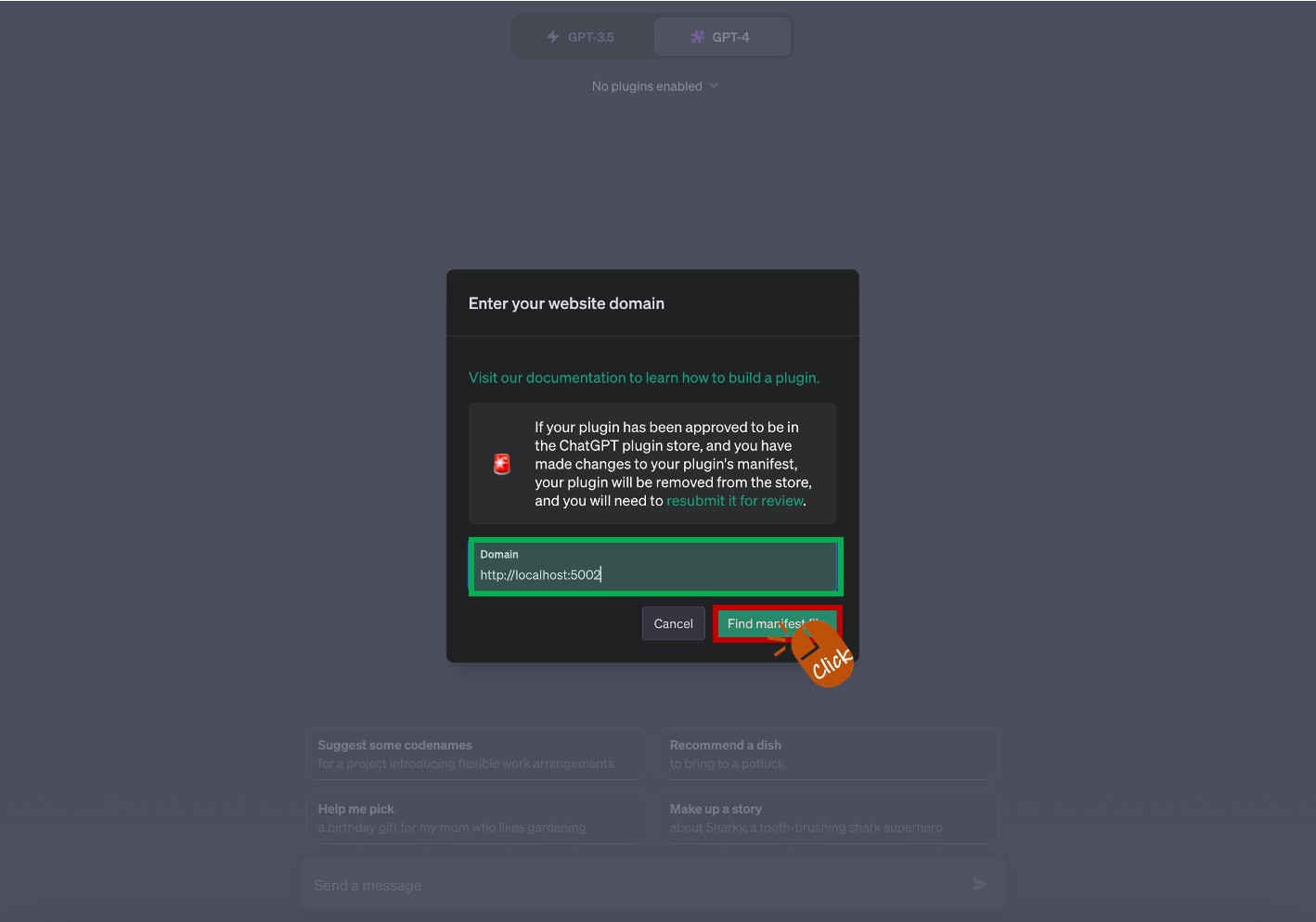
Domain 입력란에 http://localhost:5002 를 입력합니다.
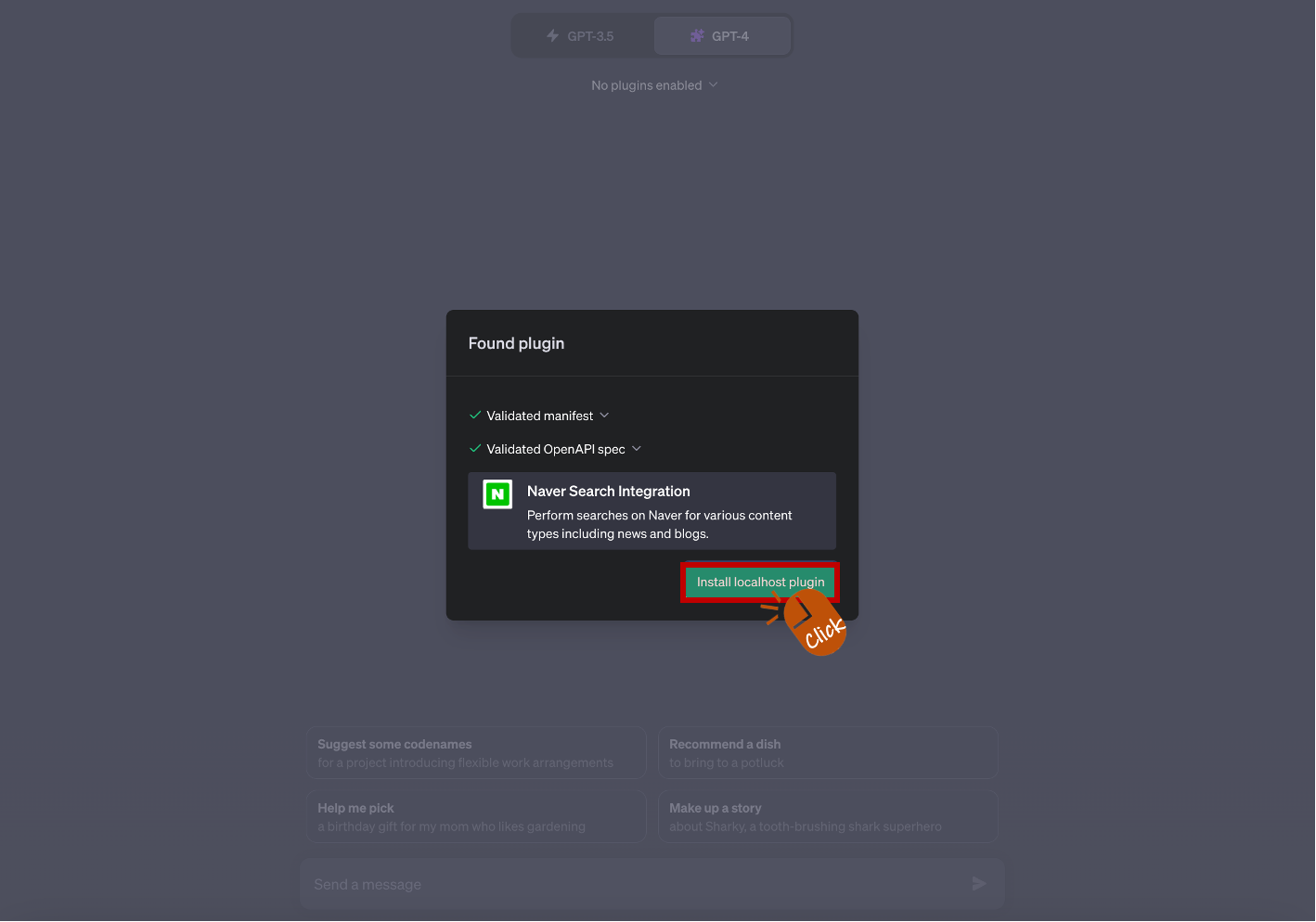
manifest와 OpenAPI Spec을 체크합니다. manifest는 Plugin이나 애플리케이션에 대한 메타데이터를 제공하는 파일입니다. OpenAPI Spec은 RESTful API를 설명하기 위한 표준화된 스펙입니다. 만약 ✅ 정상 체크가 되지 않았다면 ai-plugin.json, openapi.yaml 파일을 살펴봐야 합니다.
[ Install localhost plugin ] 버튼을 클릭합니다. logo.png를 수정했다면 변경된 아이콘이 표시될 것입니다.
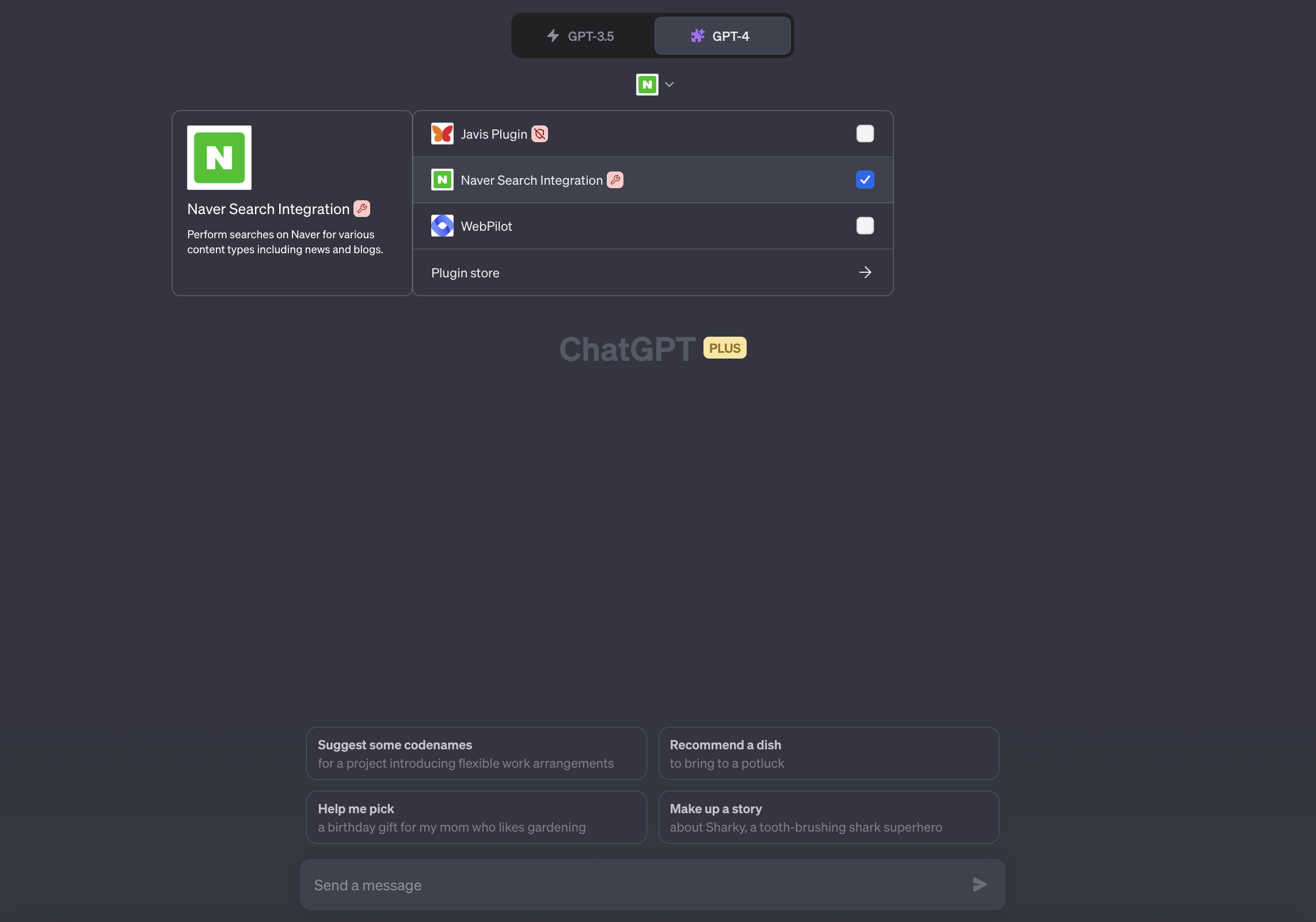
설치가 되었다면 설치한 plugin 목록에서 확인하실 수 있습니다.
#6. 나만의 Plugin (NAVER Search) 사용하기
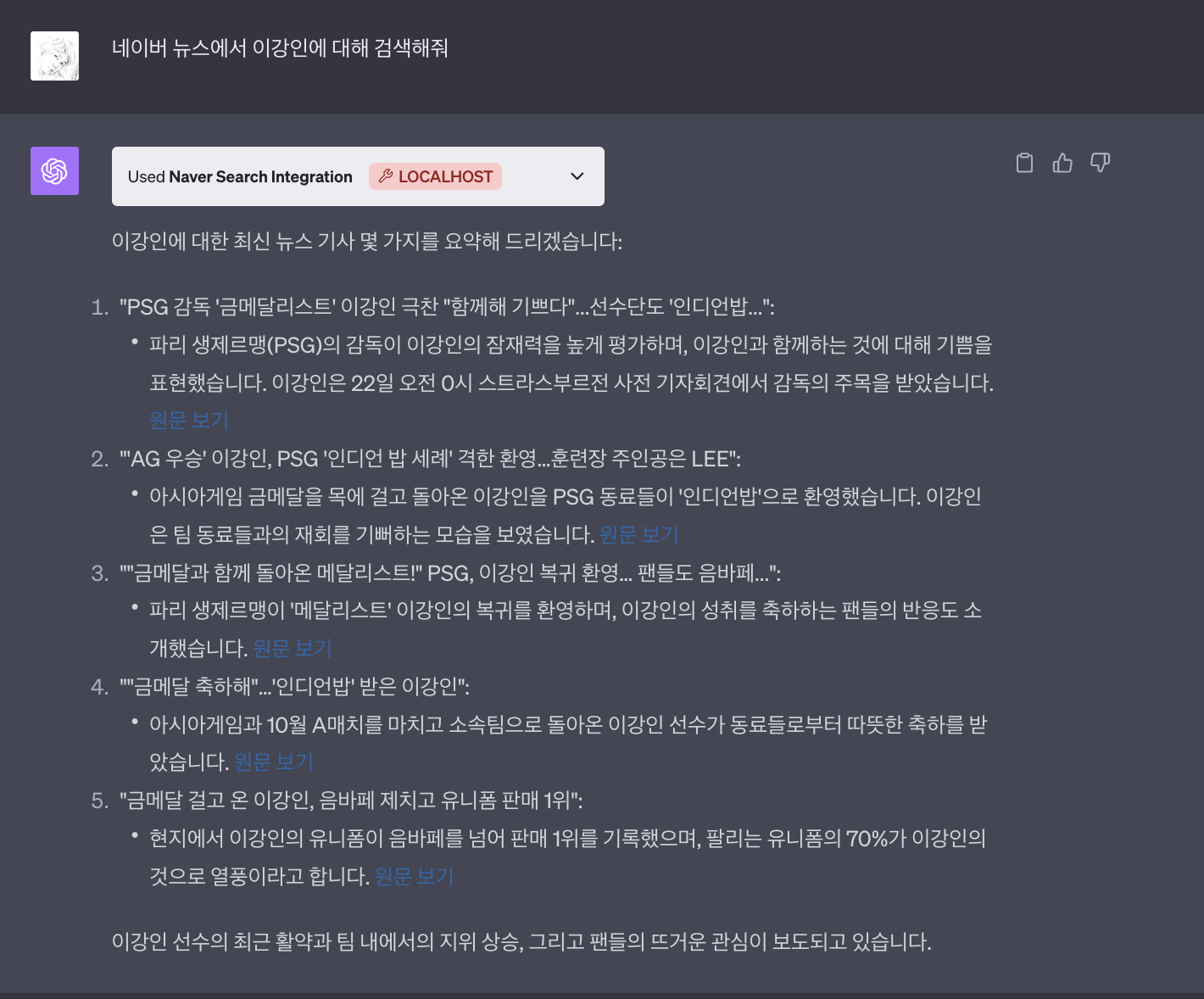
1) 뉴스 검색
개발한 NAVER Search 플러그인을 통해 뉴스 컨텐츠 검색 기능을 손쉽게 사용할 수 있습니다. 이 기능은 최신 뉴스 기사를 검색하여 다양한 언론사의 보도 내용을 한눈에 파악할 수 있게 해 줍니다.
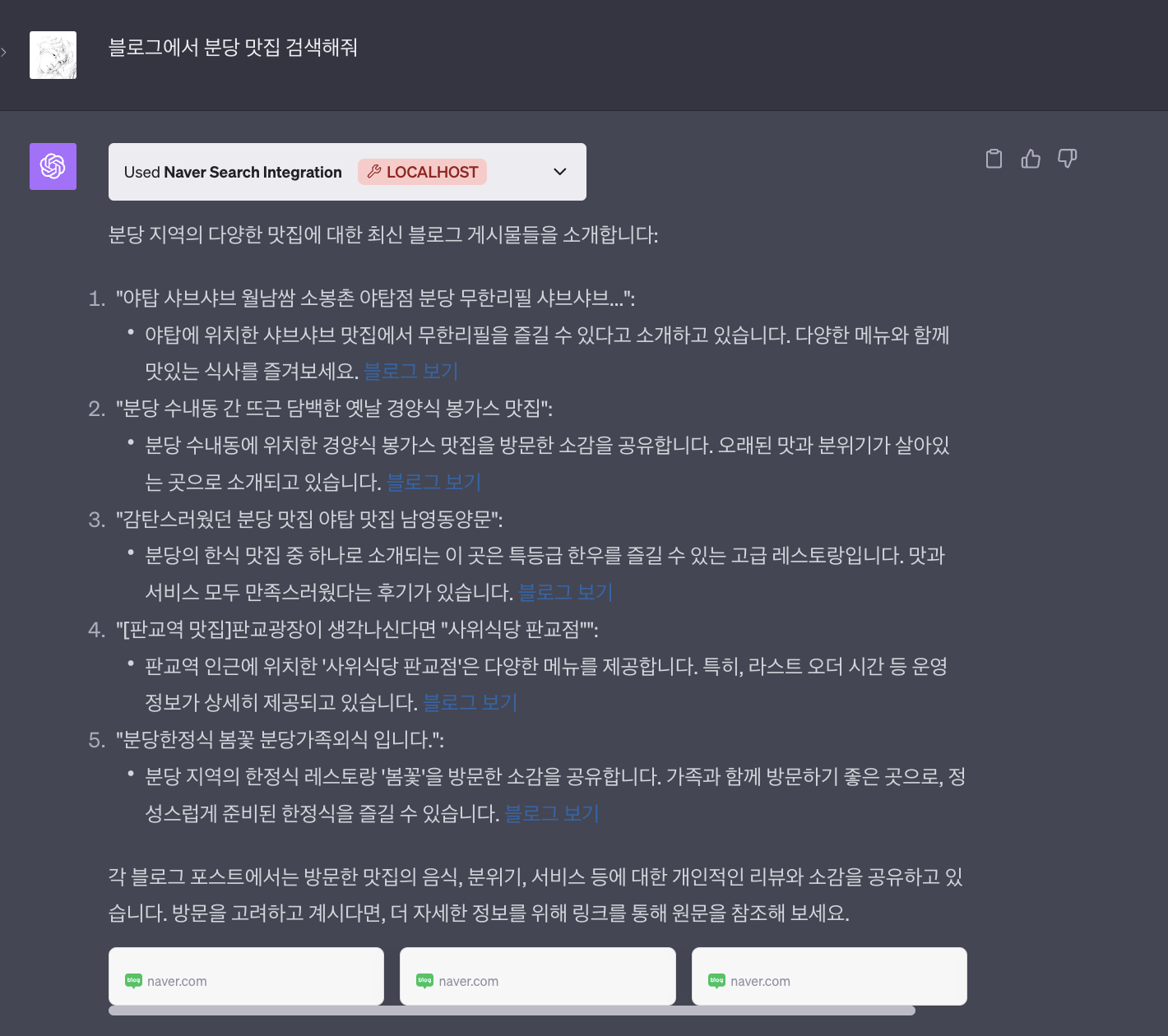
2) 블로그 검색
NAVER Search 플러그인의 "블로그 검색" 기능은 NAVER 블로그 사용자들이 작성한 다양한 포스트를 검색할 수 있는 서비스입니다. 사용자들은 특정 주제나 키워드에 대한 실제 사용자들의 의견, 리뷰, 경험 등을 직접 확인할 수 있습니다.
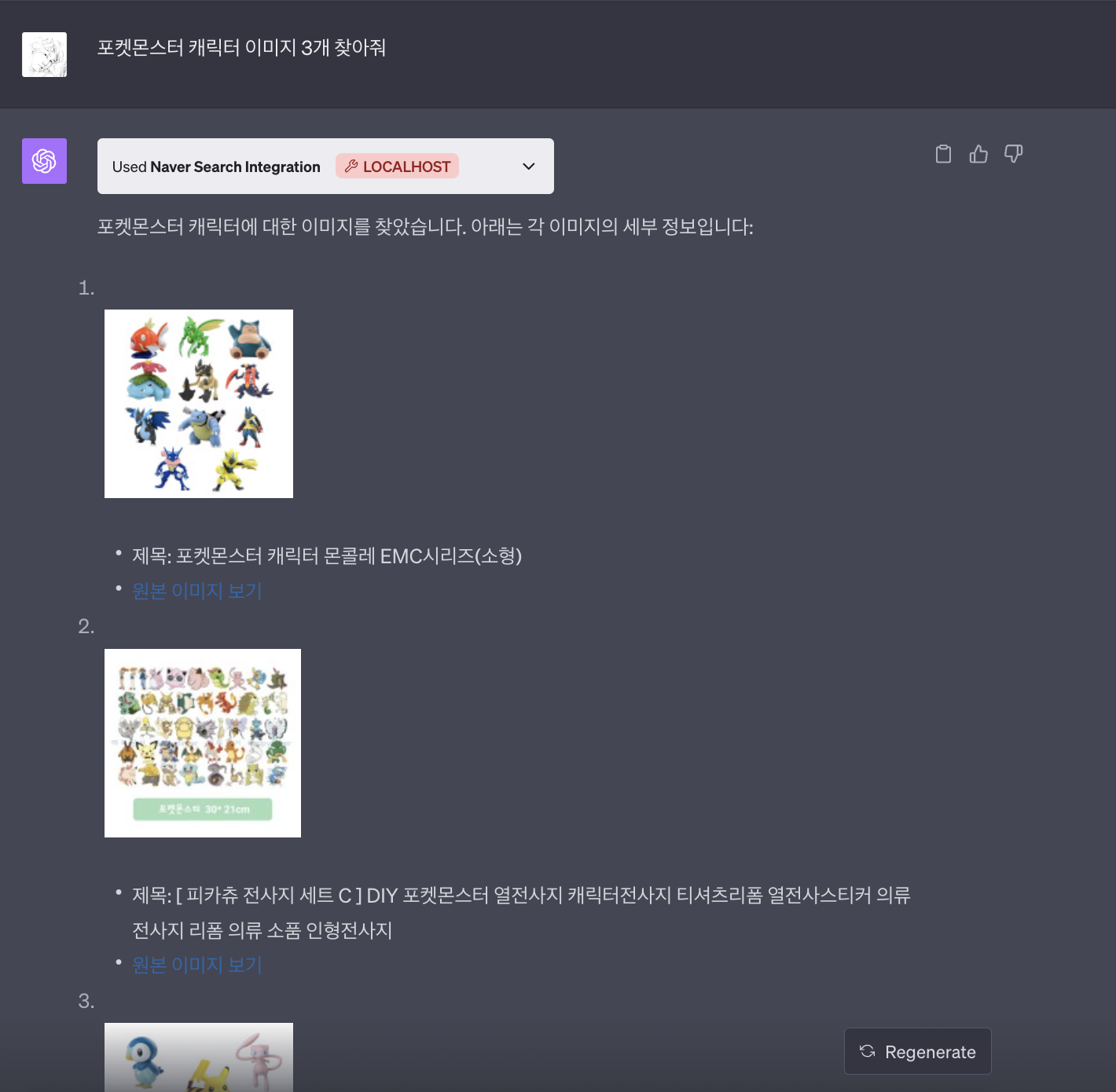
3) 이미지
NAVER Search 플러그인의 "이미지 검색" 기능을 통해 사용자는 다양한 이미지 컨텐츠에 쉽게 접근할 수 있습니다. 특정 키워드를 기반으로 한 이미지 검색을 통해, 관련된 다양한 이미지 결과를 실시간으로 확인할 수 있습니다.
4) 쇼핑
"쇼핑 검색" 기능을 통해, 사용자는 NAVER 쇼핑 플랫폼에 등록된 다양한 상품 정보를 실시간으로 검색할 수 있습니다. 이를 통해 원하는 상품의 가격, 사양, 사용자 리뷰 등 상세 정보를 한눈에 비교하고 할 수 있습니다. 상세 정보 보기를 눌러 쇼핑 페이지로 바로 연결이 가능합니다.
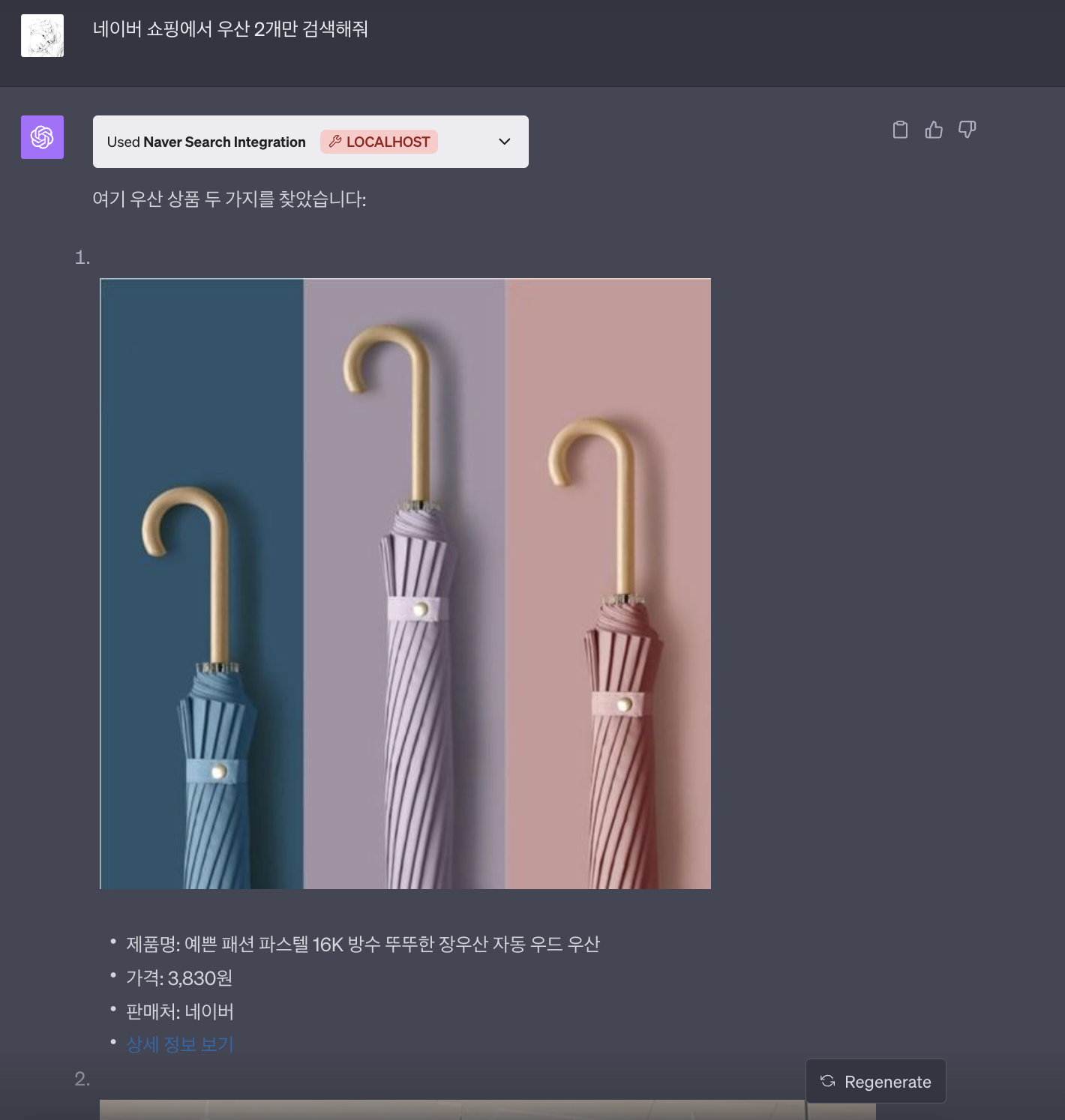
5) 지식인
"지식인 검색" 기능은 NAVER 지식인에서 제공하는 수많은 질의응답 데이터에 접근할 수 있게 해 줍니다. 사용자는 특정 주제나 질문에 대한 다양한 사람들의 의견과 답변을 실시간으로 검색하고 확인할 수 있습니다.
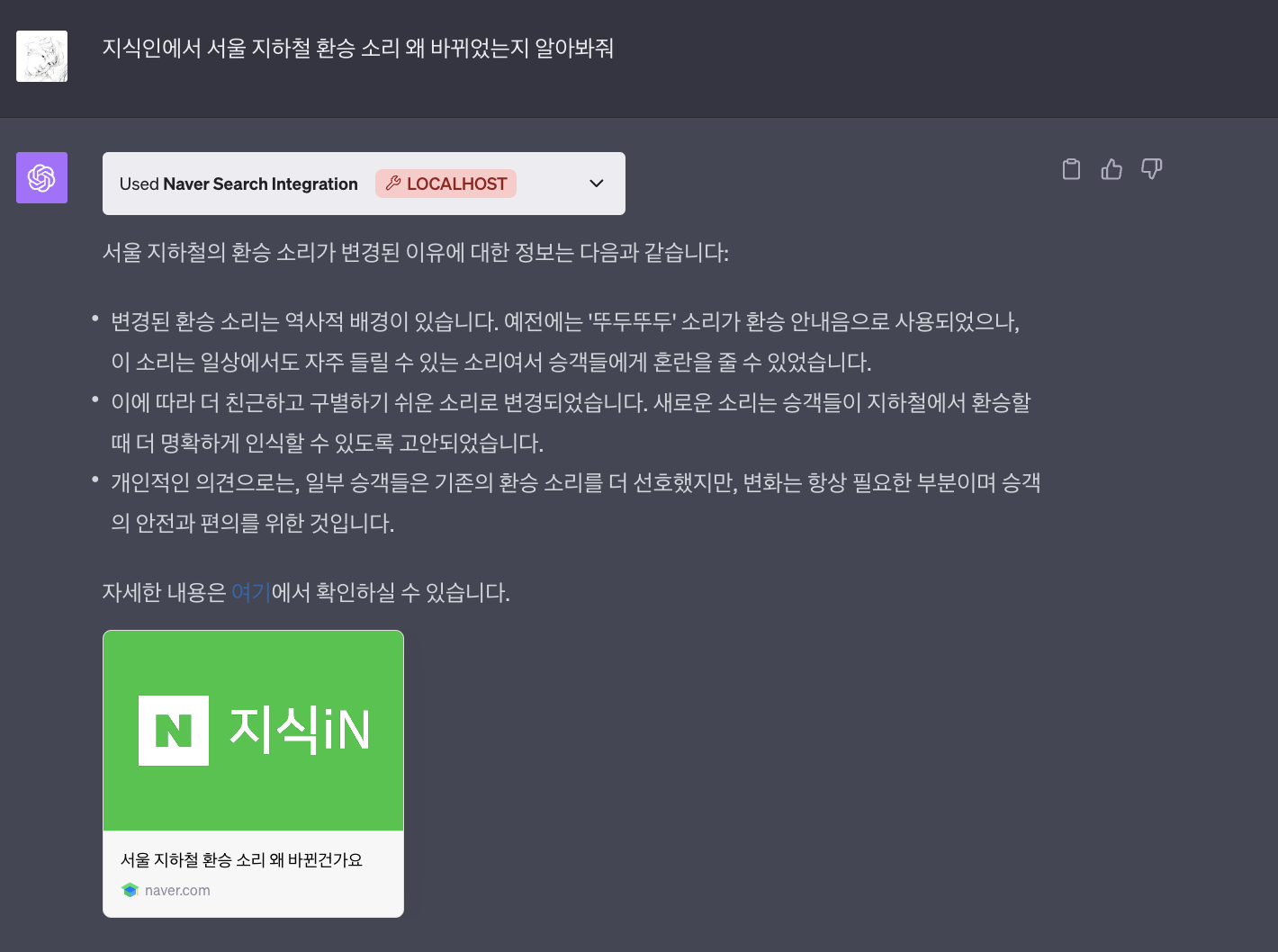
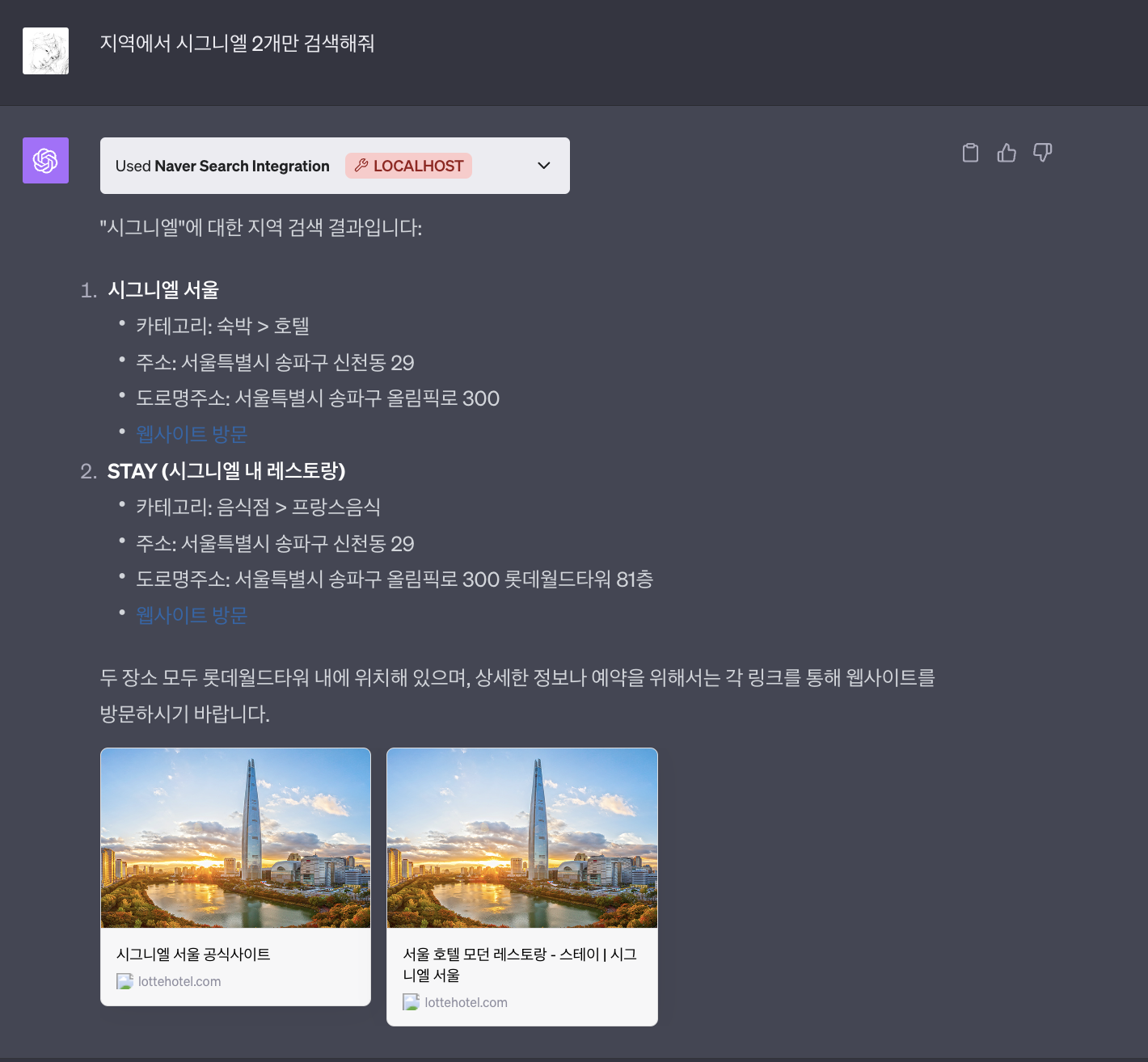
6) 지역
"지역 검색" 기능을 통해 사용자는 특정 지역에 위치한 업체나 장소에 대한 정보를 실시간으로 검색할 수 있습니다. 음식점, 카페, 병원, 호텔 등 다양한 카테고리의 장소 정보, 그리고 사용자 리뷰, 평점, 위치, 영업시간 등의 상세 정보를 제공합니다.
ChatGPT의 Plugin을 활용하여 NAVER 검색 기능을 통합하는 방법을 살펴보았습니다. ChatGPT Plugin 개발의 가장 큰 장점 중 하나는 사용자의 특정 요구사항이나 원하는 기능을 반영할 수 있도록 설계되어 맞춤형 솔루션을 만들 수 있다는 것입니다. 또한, Plugin을 개발하는 과정 자체가 생각보다 간단하기 때문에 기본적인 프로그래밍 지식과 문서를 읽는 능력만 있으면 누구나 자신만의 Plugin을 만들 수 있습니다.
이 글에서는 NAVER 검색에 초점을 맞췄지만, 다른 외부 서비스나 API와의 통합에도 적용할 수 있습니다. 새로운 기능의 추가하거나 기존 서비스의 개선, 또는 완전히 새로운 서비스를 생성하는 등 다양한 가능성이 열려 있습니다.
이제 곧 이러한 잠재력을 깨닫고, 더 많은 개인이나 기업이 이 영역에 참여하기 시작할 것입니다. 이 과정에서 새로운 아이디어가 현실이 되고, 이 플랫폼은 무한한 가능성을 제공하게 될 것입니다.
'Tech & Development > AI' 카테고리의 다른 글
| GPT-4V(ision)를 이용한 이미지 분류(Classification) - (Python) (1) | 2023.11.24 |
|---|---|
| GPT-4 with Vision API를 사용하여 이미지 인식 (Python) (3) | 2023.11.11 |
| 나만의 ChatGPT Plugin 만들기: TODO List (No Auth) (0) | 2023.09.24 |
| ChatGPT Retrieval Plugin 개발 (4) : ChatGPT에 개발한 Plugin 추가하기 (0) | 2023.09.23 |
| ChatGPT Retrieval Plugin 개발 (3) : 클라우드 배포 (0) | 2023.09.17 |
댓글을 사용할 수 없습니다.