더 똑똑해진 GPT-4 발표! 무엇이 달라졌을까?
독일 마이크로소프트 CTO 안드레아스 브라운은 2023년 3월 9일 독일에서 개최한 이벤트(AI in Focus-Digital Kickoff)에서 "다음 주 GPT-4가 공개될 예정이다"라고 깜짝 발표를 했습니다. 텍스트뿐만 아니라 음성, 이미지, 영상까지 처리하는 멀티모달 시스템(Multimodal system)이라고 설명하며 기대를 갖게 했습니다.
그런데 2023년 3월 14일 GPT-4가 진짜 출시를 했습니다.
GPT-4
We’ve created GPT-4, the latest milestone in OpenAI’s effort in scaling up deep learning. GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that, while less capable than humans in many real-world scenarios, exhi
openai.com
저와 같이 유료 구독 서비스인 ChatGPT Plus를 이용하고 계신 분께서는 현재 즉시 이용이 가능하고 그렇지 않으신 분은 Waitlist에 추가하실 수 있습니다. (2023년 3월 15일 기준)

GPT-4는 GPT-3.5에 비해 Speed는 떨어졌지만 Reasoning과 Conciseness가 많이 올라간 것으로 보입니다. 사실 최근 빅테크 기업들이 파라미터(매개변수) 증가, 거대화 전쟁이 시작되면서 GPT-4의 파라미터 개수에 대해서도 관심이 많을 텐데요. GPT-4의 파라미터(매개변수) 수는 GPT-3.5의 파라미터(1750억 개) 보다 증가되었지만 정확히 어느 정도인지는 공개하지 않았습니다. 일부에서 GTP-4는 100조 개의 파라미터 모델이 될 것이라는 예상 했었는데 OpenAI CEO 샘 알트만은 터무니없는 이야기라고 일축하기도 했습니다. 100조 개의 파라미터를 가진 모델을 학습시키려면 엄청난 컴퓨팅 리소스가 필요하고 데이터세트 역시 그에 상응하는 양이 필요하기 때문이죠.
자 그럼 GPT-4가 GPT-3.5에 비해 얼마나 좋아졌을지 구체적으로 살펴보겠습니다.
OpenAI에서는 GPT-4가 미국의 모의 변호사 시험에서 백분위 90%, 대학입시시험 SAT에서는 89%를 기록하며 인간 수준의 성능을 발휘했다고 설명하고 있습니다. 이전 모델인 GPT-3.5는 모의 변호사 시험에서 백분위 10% 성적을 기록한 바 있습니다. 위에서 보이는 그래프는 다양한 시험에 대한 성적 그래프인데 파란색 그래프가 GPT-3.5의 성적이고 초록색 그래프가 GPT-4의 성적입니다. 확실히 GPT-3.5보다 높은 성적을 보여주고 있습니다. 조금 더 진한 초록색은 GPT-4의 vision이 포함된 버전인데 no vision보다 높은 성적을 보였다고 합니다. 단순히 텍스트만 보고 시험을 치렀을 때보다 이미지가 포함되면 이미지 해석 후 시험을 치렀을 때 더 성적이 높았다는 겁입니다. 멀티모달의 장점을 소개하기 위한 것 같습니다.
GPT-3.5와 또 다른 차이점은 영어 외 다른 언어에 대한 지원이 강화되었다는 점입니다. OpenAI가 Microsoft Azure 번역을 활용하여 벤치마크(MMLU) 테스트 결과, GPT-4는 전 세계 26개 언어 중 한국어를 포함한 24개 언어에서 높은 성능을 보였습니다. 파란색 그래프가 GPT-3.5인데 GPT-3.5뿐만 아니라 경쟁사의 구글 팜(PaLM), 딥마인드 친칠라(Chinchilla) 등의 모델과 비교하더라도 GPT-4는 전체적으로 우위를 보입니다. GPT-3.5 English가 70.1% 인데 GPT-4의 Korean이 77%의 성적이니 매우 기대가 됩니다.
위 예제는 문자를 반복하지 말고 A~Z로 시작하는 단어를 순서대로 나열하면서 신데렐라의 줄거리를 설명하라는 명령입니다. "A beautiful Cinderella.." 이 예제를 통해 GPT-4의 창의성을 강조합니다.

GPT-4의 가장 큰 변화는 GPT-3.5와 달리 여러 데이터 형태를 인식하는 멀티모달 모델이라는 것입니다. 프롬프트에 텍스트뿐 아니라 이미지를 입력하면 해석하여 원하는 답변 준다는 것입니다. 위 예제를 보면 사진을 주고 이 사진에 나온 재료로 무엇을 만들 수 있는지 질문을 하니 다양한 요리를 답해줍니다. (하지만 아직 리서치 프리뷰 단계라 이미지를 입력하는 기능은 사용이 제한되어 있으며 비디오 지원은 포함되지 않았습니다.)

GPT-3.5의 경우에는 텍스트 3,000 단어까지 처리가 가능했습니다. GPT-4는 8배 증가한 25,000 단어까지 처리가 가능합니다. 정말 긴 내용의 글도 입력이 가능해졌습니다.

그리고 GPT-3.5보다 미묘한 지시사항을 잘 처리한다고 설명하고 있는데요. 위 예제는 여러 사람의 일정을 넣고 공통적으로 어느 시간에 회의가 가능할 것인지에 대해 질문을 한 것입니다. 살펴보면 확실히 GPT-3.5보다 더 고급 추론이 가능해진 것 같습니다.

추가적으로 OpenAI Blog 게시물을 보면 "일상 대화에서 GPT-3.5와 GPT-4의 차이가 미묘할 수 있습니다. 그러나 작업의 복잡성이 충분한 임계값에 도달했을 때 차이가 나타납니다. GPT-4는 GPT-3.5보다 훨씬 안정적이고 창의성이 뛰어나며, 미묘한 지시사항을 더 잘 처리할 수 있습니다."라고 설명하고 있습니다.
조금더 나아가서 그 미묘한 차이를 알아보도록 하겠습니다.
#1 질문 : 강 건너기 문제 (늑대, 양, 풀)
정해진 용량의 운송수단으로 주어진 물체, 사람 등을 옮기는 유형의 문제입니다. 예전에 예능 프로그램인 무한도전에 나왔던 문제입니다.
"늑대, 양, 풀이 있는데 한 번에 하나씩 밖에 옮길 수 없고, 사람이 없으면 늑대는 양을, 양은 풀을 먹어버린다. 모두 무사히 건너기 위해서는 어떻게 해야할까?"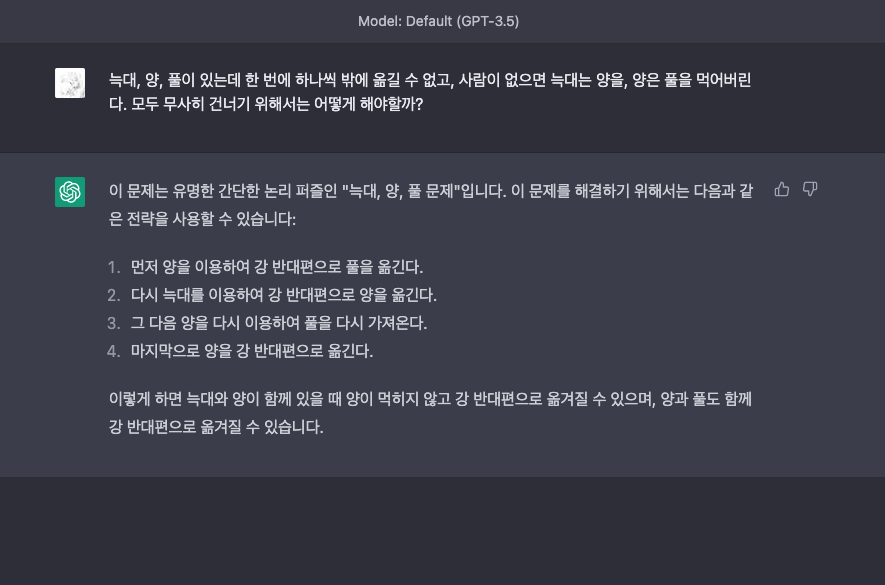

이 문제에 대한 답을 보면 GPT-3.5도 설득력 있게 설명하고 있지만 자세히 들여다보면 왜곡된 설명이고 잘못된 답입니다. 그런데 GPT-4는 늑대, 양, 풀 문제를 정확하게 풀었습니다. 단계 역시 올바른 순서로 명확하게 명시하고 있습니다.
#2 질문 : 외판원 문제 (Traveling Salesman Problem, TSP)
여행 판매원 문제는 인기 있는 수학 문제로, n개의 도시들 사이의 거리가 주어지고 모든 도시를 정확히 한 번씩 돌아 제자리로 돌아와야 하는데 지점과 거리를 고려하여 가장 효율적인 궤도를 구하는 문제입니다.

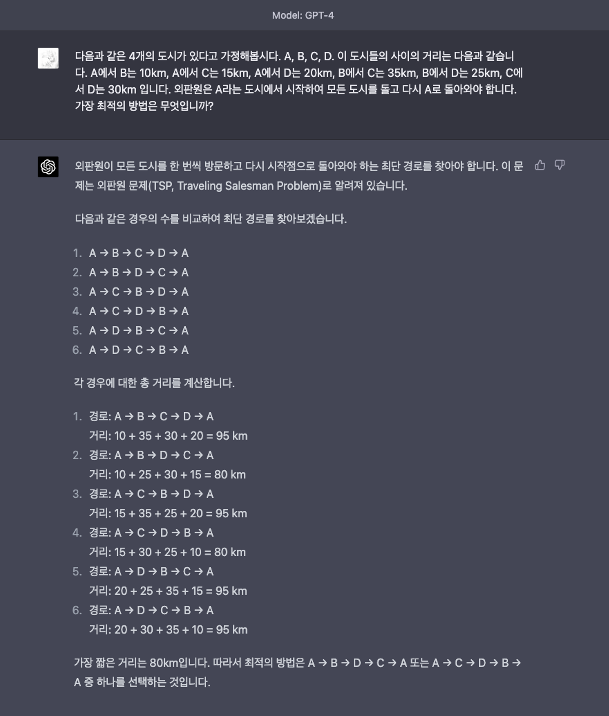
외판원 문제에서 GPT-3.5는 틀린 답을 내놓았지만 GPT-4는 성공적으로 해결했습니다.
여전히 GPT-4도 오류가 발생하지만 GPT-3.5보다 확실히 개선이 되었습니다. OpenAI는 GPT-4가 많은 실세계 시나리오에선 아직 인간보다 능력이 떨어지지만 딥러닝을 확장하기 위한 노력의 최신 이정표라고 설명하고 있습니다. 매우 놀라운 것은 ChatGPT가 서비스된 지 몇 개월도 되지 않아 충분히 놀란만 한 성능을 보이는 GPT-4를 발표했다는 것입니다. 당초 2023년 말이나 되어야 나올 것이라는 예상과는 다르게 말이죠.
위에 여러 예시만 보더라도 생성형 AI의 무궁무진한 활용 가능성을 충분히 보여주고 있는 것 같습니다.
'Insights > IT Trends' 카테고리의 다른 글
| 새로운 생태계 등장 : ChatGPT Plugins (정리) (0) | 2023.04.10 |
|---|---|
| Adobe 이미지 생성 AI 'Firefly' 발표 (사용방법) (0) | 2023.04.07 |
| ChatGPT 원리는 무엇이고, 어떻게 학습되었을까? (0) | 2023.02.14 |
| "AI 그리고 초거대 AI" 쉽게 알아보기 (0) | 2023.01.19 |
| 드림 스튜디오(Dream Studio - Stable Diffusion) 사용기 (사용법) (0) | 2023.01.09 |
댓글을 사용할 수 없습니다.