[ OCR ] Naver CLOVA OCR API 를 이용한 OCR 개발 - Python
현재 한국에서 가장 많은 사람들이 사용하는 인터넷 포털 서비스 회사인 네이버에서 개발한 인공지능 플랫폼인 Naver CLOVA에서 제공하는 OCR API를 활용하여 이미지에서 텍스트 영역을 감지하고 문자 인식(OCR)을 하는 방법에 대해 설명드리도록 하겠습니다. Naver Cloud Plaform는 OCR 이외에도 AI 관련 인프라부터 음성 인식, 얼굴 인식 등 다양한 서비스를 쉽고 편리하게 구축할 수 있도록 제공하고 있습니다.
1. 도메인 생성
Naver CLOVA OCR API를 사용하기 위해서는 Naver Cloud Platform 계정이 필요하며 계정이 없다면 계정 생성이 필요합니다. Naver Cloud Platform 페이지로 이동하여 회원 가입 및 로그인을 진행합니다.

Naver CLOVA OCR을 사용하기 위해서는 결제수단 등록이 필요합니다. 나중에는 바뀔 수도 있지만 현재 기준 (22.05.06)으로 결재 정보 등록 시 무료 크레딧 100,000원을 지급힙니다.
결제수단 등록을 완료하였다면 서비스에서 CLOVA OCR 을 검색 후 클릭하여 이용 신청을 합니다.
Naver Cloud Platform 콘솔 왼쪽에 CLOVA OCR 이 보인다면 정상적으로 이용 신청이 된 것입니다.
추가로 Invoke URL 생성을 위해 API Gateway 이용 신청을 합니다.
이제 도메인을 추가하도록 하겠습니다. 도메인은 CLOVA OCR 서비스의 플랜(요금), 통계, 관리의 기준이 되는 단위입니다. CLOVA OCR은 General, Template, Document 이렇게 3가지로 구분하여 서비스를 제공하는데 지금은 단순히 General로 도메인을 생성하여 진행하도록 하겠습니다.
생성 된 도메인 우측 동작 메뉴에서 [Text OCR] 버튼을 클릭하여 Custom API Gateway 설정을 합니다. [생성] 버튼을 클릭하여 Secret Key를 발급합니다. OCR Invoke URL은 외부 연동 Endpoint에 입력할 OCR API 주소를 의미합니다. 위에서 언급했듯이 API Gateway 이용 신청이 되어 있는 경우, 자동 연동 (Interlock) 버튼을 클릭해 손쉽게 자동 연동할 수 있습니다.
이제 간단히 테스트를 진행해 보도록 하겠습니다. 우측 동작 메뉴에서 [Demo] 버튼을 클릭합니다.
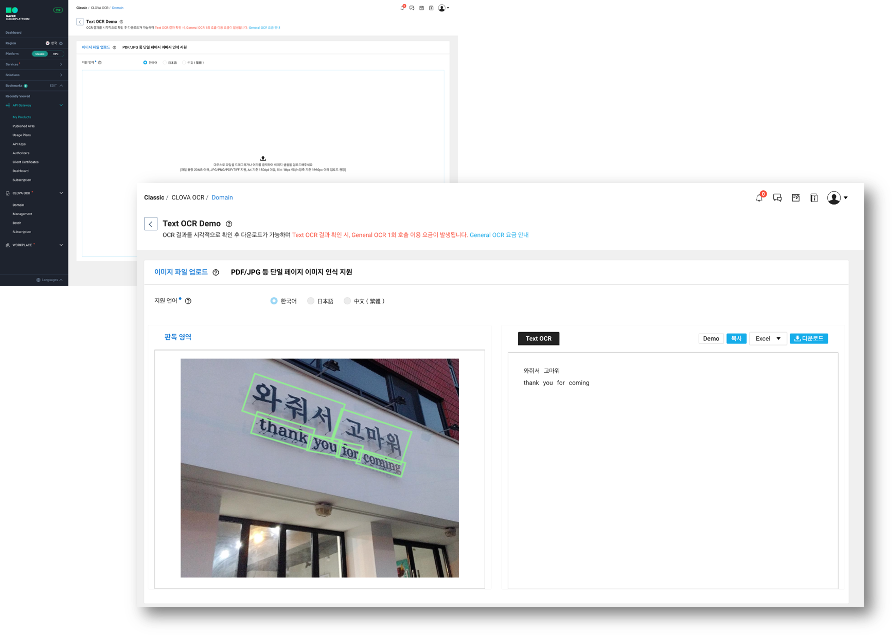
테스트 할 이미지를 드래그하여 업로드하면 OCR 수행 결과를 확인 할 수 있습니다.
2. Naver CLOVA OCR API 개발 환경 구성
CLOVA OCR은 REST API를 이용합니다.
pip install opencv-contrib-python pip install requests
3. Naver CLOVA OCR API Script 구현
Import Packages
import numpy as np import platform from PIL import ImageFont, ImageDraw, Image from matplotlib import pyplot as plt import uuid import json import time import cv2 import requests
Jupyter Notebook 또는 Colab에서 이미지를 확인하기위한 Function
def plt_imshow(title='image', img=None, figsize=(8 ,5)): plt.figure(figsize=figsize) if type(img) == list: if type(title) == list: titles = title else: titles = [] for i in range(len(img)): titles.append(title) for i in range(len(img)): if len(img[i].shape) <= 2: rgbImg = cv2.cvtColor(img[i], cv2.COLOR_GRAY2RGB) else: rgbImg = cv2.cvtColor(img[i], cv2.COLOR_BGR2RGB) plt.subplot(1, len(img), i + 1), plt.imshow(rgbImg) plt.title(titles[i]) plt.xticks([]), plt.yticks([]) plt.show() else: if len(img.shape) < 3: rgbImg = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB) else: rgbImg = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) plt.imshow(rgbImg) plt.title(title) plt.xticks([]), plt.yticks([]) plt.show()
OpenCV의 putText 를 이용하여 한글을 출력하는 경우 한글이 깨지는 문제를 해결하기 위한 Funtion
def put_text(image, text, x, y, color=(0, 255, 0), font_size=22): if type(image) == np.ndarray: color_coverted = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) image = Image.fromarray(color_coverted) if platform.system() == 'Darwin': font = 'AppleGothic.ttf' elif platform.system() == 'Windows': font = 'malgun.ttf' image_font = ImageFont.truetype(font, font_size) font = ImageFont.load_default() draw = ImageDraw.Draw(image) draw.text((x, y), text, font=image_font, fill=color) numpy_image = np.array(image) opencv_image = cv2.cvtColor(numpy_image, cv2.COLOR_RGB2BGR) return opencv_image
도메인 생성 시 확인했던 APIGW Invoke URL는 api_url 에 입력하고, Secret Key는 secret_key 값에 입력합니다.
api_url = '<YOUR_API_URL>' secret_key = '<YOUR_SECRET_KEY>'
Load Image
이미지는 바이너리로 변환하여 load 합니다.
path = 'asset/images/test_image9.jpg' files = [('file', open(path,'rb'))]
Request to CLOVA OCR API
REST API 호출 후 응답을 기다립니다.
request_json = {'images': [{'format': 'jpg', 'name': 'demo' }], 'requestId': str(uuid.uuid4()), 'version': 'V2', 'timestamp': int(round(time.time() * 1000)) } payload = {'message': json.dumps(request_json).encode('UTF-8')} headers = { 'X-OCR-SECRET': secret_key, } response = requests.request("POST", api_url, headers=headers, data=payload, files=files) result = response.json()
Check Result
img = cv2.imread(path) roi_img = img.copy() for field in result['images'][0]['fields']: text = field['inferText'] vertices_list = field['boundingPoly']['vertices'] pts = [tuple(vertice.values()) for vertice in vertices_list] topLeft = [int(_) for _ in pts[0]] topRight = [int(_) for _ in pts[1]] bottomRight = [int(_) for _ in pts[2]] bottomLeft = [int(_) for _ in pts[3]] cv2.line(roi_img, topLeft, topRight, (0,255,0), 2) cv2.line(roi_img, topRight, bottomRight, (0,255,0), 2) cv2.line(roi_img, bottomRight, bottomLeft, (0,255,0), 2) cv2.line(roi_img, bottomLeft, topLeft, (0,255,0), 2) roi_img = put_text(roi_img, text, topLeft[0], topLeft[1] - 10, font_size=30) print(text) plt_imshow(["Original", "ROI"], [img, roi_img], figsize=(16, 10))

고마워
thank
you
for
coming
테스트 이미지는 올바른 OCR 결과가 나왔습니다. 대략 장당 처리 속도는 2초 정도 소요되는 것 같습니다. 좀 더 도전적인 이미지에서는 다양한 언어가 포함되어 있는데 영어와 한글 인식율에 비해 다른 언어는 인식율이 좋지 못한 것 같습니다. 아마도 도메인 생성 시 지원 언어를 한국어, 일본어, 중국어 중 선택하도록 되어 있었는데 이에 따른 결과인 것 같습니다. 한국어에 더 집중한 것인지 모르겠지만 자동 언어 식별 성능은 부족한 것 같습니다. 그래도 한국어 인식율은 Good 이네요.

·m
Bus
2017年11月11日
버스타
TAXI
:
Taxi
선)
15
택시타
좀 더 나아가서 CLOVA OCR은 Template, Document 을 이용하면 이미지에서 원하는 메타 데이타만 얻을 수도 있고 특화 모델(신분증, 영수증, 신용카드 등) 이 적용된 OCR 수행도 가능합니다. API 호출 결과로 후속 프로세스를 고민한다면 사용자 입장에서는 이런 기능은 충분히 매력적인 것 같습니다.
'Tech & Development > OCR' 카테고리의 다른 글
| [ OCR ] 한글 인식에 탁월한 성능, 적은 용량의 PaddleOCR 사용하기 - Python (3) | 2023.07.05 |
|---|---|
| [ OCR ] kakaobrain pororo OCR 사용하기 - Python (7) | 2023.02.06 |
| [ OCR ] Amazon Rekognition API 를 이용한 OCR 개발 - Python (0) | 2022.05.06 |
| [ OCR ] Microsoft Cognitive Services 를 이용한 OCR 개발 - Python (2) | 2022.05.06 |
| [ OCR ] Google Cloud Vision API 를 이용한 OCR 개발 - Python (3) | 2022.05.04 |
댓글을 사용할 수 없습니다.