[ OCR ] Google Cloud Vision API 를 이용한 OCR 개발 - Python
Google 에서는 매우 정확하게 이미지의 정보를 추출할 수 있는 API 제공합니다. Google Cloud Vision API는 많은 기능이 존재하지만 이 글에서는 이미지에서 텍스트의 영역을 감지하고 문자 인식(OCR)을 수행하는 API에 대해 설명드리도록 하겠습니다.
1. Google Cloud Vision API 키 발급
먼저 Google Cloud Vision API를 엑세스 하기 위해 서비스 계정을 생성하고 비공개 키 파일(.JSON)을 다운로드 해야합니다. Google Cloud Vision API 페이지로 이동하여 [Vision AI 무료로 사용해보기] 또는 우측에 [무료로 시작하기] 버튼을 클릭합니다.

약관 동의 후 계속 진행합니다.
API 사용을 위해서는 서비스 생성 및 결제 계정 정보 설정이 완료되어야 사용이 가능합니다. 옆에 설명에도 나오지만 결제 정보를 요구하는 이유는 상용기술이기 때문에, 구글 계정 증식을 통한 무제한 가입을 막고자 함이며, 동의 없이 과금이 발생하지 않는다고 합니다. 추가로 결제 설정에 대한 상세한 내용은 Google Cloud 가이드를 참고하시면 됩니다.
* 만약 이미 Google Cloud Platform계정이 있다면 Google Cloud Platform Console로 이동하셔도 됩니다.
Cloud Console에서 서비스 계정 만들기 페이지로 이동합니다. [프로젝트 만들기]를 클릭합니다. 기존 프로젝트를 사용한다면 만들기는 생략하고 사용 할 프로젝트를 선택하시면 됩니다.
프로젝트 이름을 입력하고 [만들기]를 클릭합니다.
프로젝트를 선택합니다.
서비스 계정 이름 필드에 이름을 입력합니다. Cloud Console은 이 이름을 기반으로 서비스 계정 ID 필드를 채웁니다. 서비스 계정 설명 필드에 설명을 입력하고 [만들고 계속하기]를 클릭합니다. 프로젝트에 대한 액세스 권한을 제공하려면 서비스 계정에 프로젝트 > 소유자 역할을 부여합니다. 이후 [계속]을 클릭하고 이어서 [완료]를 클릭하여 서비스 계정을 생성합니다.
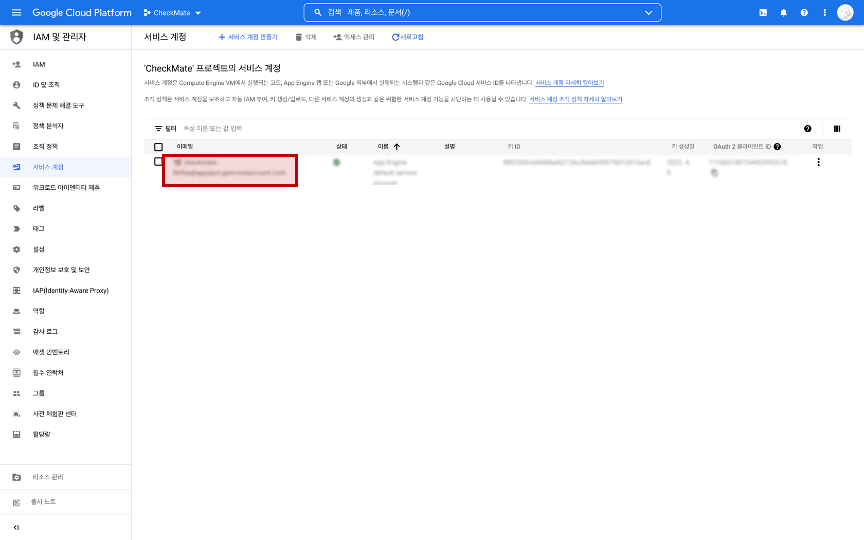
Cloud Console에서 만든 서비스 계정의 이메일 주소를 클릭합니다.
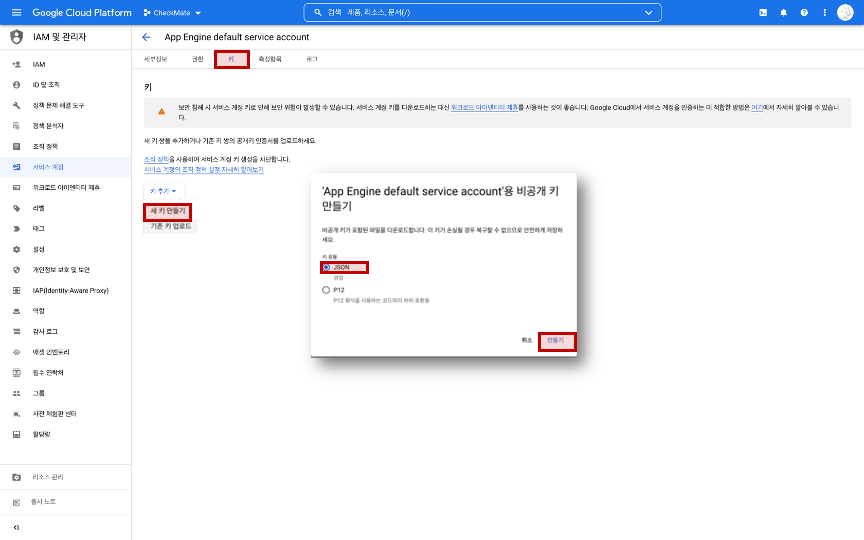
[키] 를 클릭하고 [키 추가]에서 [새 키 만들기]를 클릭합니다. JSON 선택 후 [만들기]를 클릭하면 JSON 키 파일이 다운로드 됩니다.
2. Google Cloud Vision API용 개발 환경 구성
테스트를 위해서 OpenCV와 Google Cloud Vision 라이브러리가 필요합니다. 라이브러리는 pip 를 이용하여 간단히 설치가 가능합니다.
pip install opencv-contrib-python pip install --upgrade google-cloud-vision
3. Google Cloud Vision API Script 구현
먼저, Python Script 작성을 하기 전에 다운로드 받은 API 키 JSON 파일을 작성하는 Python 파일과 동일한 디렉토리로 옮기는 것을 권장드립니다.
Import Packages
import os import io import numpy as np import platform from PIL import ImageFont, ImageDraw, Image from utils import plt_imshow import cv2 from google.cloud import vision
Jupyter Notebook 또는 Colab에서 이미지를 확인하기위한 Function
def plt_imshow(title='image', img=None, figsize=(8 ,5)): plt.figure(figsize=figsize) if type(img) == list: if type(title) == list: titles = title else: titles = [] for i in range(len(img)): titles.append(title) for i in range(len(img)): if len(img[i].shape) <= 2: rgbImg = cv2.cvtColor(img[i], cv2.COLOR_GRAY2RGB) else: rgbImg = cv2.cvtColor(img[i], cv2.COLOR_BGR2RGB) plt.subplot(1, len(img), i + 1), plt.imshow(rgbImg) plt.title(titles[i]) plt.xticks([]), plt.yticks([]) plt.show() else: if len(img.shape) < 3: rgbImg = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB) else: rgbImg = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) plt.imshow(rgbImg) plt.title(title) plt.xticks([]), plt.yticks([]) plt.show()
OpenCV의 putText 를 이용하여 한글을 출력하는 경우 한글이 깨지는 문제를 해결하기 위한 Funtion
def putText(image, text, x, y, color=(0, 255, 0), font_size=22): if type(image) == np.ndarray: color_coverted = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) image = Image.fromarray(color_coverted) if platform.system() == 'Darwin': font = 'AppleGothic.ttf' elif platform.system() == 'Windows': font = 'malgun.ttf' else: font = 'NanumGothic.ttf' image_font = ImageFont.truetype(font, font_size) font = ImageFont.load_default() draw = ImageDraw.Draw(image) draw.text((x, y), text, font=image_font, fill=color) numpy_image = np.array(image) opencv_image = cv2.cvtColor(numpy_image, cv2.COLOR_RGB2BGR) return opencv_image
Google Cloud Vision API에 액세스하기 위한 클라이언트 인터페이스를 생성합니다. service-account-file.json 파일은 다운로드 받은 API JSON 파일입니다. GOOGLE_APPLICATION_CREDENTIALS 환경 변수를 서비스 계정 키가 포함된 JSON 파일의 경로로 설정합니다. 이 변수는 현재 셸 세션에만 적용되므로, 새 세션을 열 경우, 변수를 다시 설정하게 됩니다.
export GOOGLE_APPLICATION_CREDENTIALS="KEY_PATH"PowerShell
$env:GOOGLE_APPLICATION_CREDENTIALS="KEY_PATH"명령 프롬프트
set GOOGLE_APPLICATION_CREDENTIALS=KEY_PATHos.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'service-account-file.json' client_options = {'api_endpoint': 'eu-vision.googleapis.com'} client = vision.ImageAnnotatorClient(client_options=client_options)
Load Image
이미지는 byte array로 변환하여 load 합니다.
path = 'asset/images/test_image8.jpg' with io.open(path, 'rb') as image_file: content = image_file.read()
Request to Google Cloud Vision API
API 호출 방식은 매우 간단합니다. 만약 PermissionDenied: 403 This API method requires billing to be enabled. 오류가 발생하였다면 결제 계정 설정이 안된 경우 입니다. Google Cloud Platform Console로 이동하여 결제 정보 설정을 하시면 됩니다.
image = vision.Image(content=content) response = client.text_detection(image=image) texts = response.text_annotations
Check Result
img = cv2.imread(path) roi_img = img.copy() for text in texts: print('\n"{}"'.format(text.description)) vertices = (['({},{})'.format(vertex.x, vertex.y) for vertex in text.bounding_poly.vertices]) ocr_text = text.description x1 = text.bounding_poly.vertices[0].x y1 = text.bounding_poly.vertices[0].y x2 = text.bounding_poly.vertices[1].x y2 = text.bounding_poly.vertices[2].y cv2.rectangle(roi_img, (int(x1), int(y1)), (int(x2), int(y2)), (0,255,0), 2) roi_img = putText(roi_img, ocr_text, x1, y1 - 30, font_size=30) if response.error.message: raise Exception( '{}\nFor more info on error messages, check: ' 'https://cloud.google.com/apis/design/errors'.format( response.error.message)) plt_imshow(["Original", "ROI"], [img, roi_img], figsize=(16, 10))

thank you for coming
"
"와줘서"
"고마워"
"thank"
"you"
"for"
"coming"
임의의 이미지에서 텍스트 위치를 감지하여 문자인식(OCR)을 수행한 결과입니다. 글자의 각도가 그리 좋지 않았지만 한글과 영어가 잘 구별되었고 문자인식 역시 높은 수준의 인식율을 보여줍니다.
하지만 까다로운 저품질의 도전적인 이미지를 시도해 보았을 때는 한글 인식율은 저조 한 것으로 보여집니다.

"ール
バス
Bus
公共汽车 叫会
タクシー
TAXI
선)
Taxi
出租汽车叫AE}
"
"ー"
"ル"
"バス"
"Bus"
"公共汽车"
"叫"
"会"
"タクシー"
"TAXI"
"선"
")"
"Taxi"
"出租汽车"
"叫"
"AE"
"}"
Google Cloud Vision API는 하나 이상의 언어를 지정 (languageHints) 하여 수행 할 수 있습니다. 하지만 API 가이드에 보면 빈 값으로 두면 자동 언어 감지가 사용되어 최상의 결과를 얻을 수 있다고 소개되어 있네요. 지원되는 언어는 가이드 페이지에서 확인이 가능합니다.
'Tech & Development > OCR' 카테고리의 다른 글
| [ OCR ] Amazon Rekognition API 를 이용한 OCR 개발 - Python (0) | 2022.05.06 |
|---|---|
| [ OCR ] Microsoft Cognitive Services 를 이용한 OCR 개발 - Python (2) | 2022.05.06 |
| [ OCR ] EasyOCR 사용하기 - Python (2) | 2022.01.13 |
| [ OCR ] 문자 추출 및 인식 (EAST text Detector Model) - Python (5) | 2022.01.13 |
| [ OCR ] 파이썬 Tesseract OCR 활용 (심화2) - Python (7) | 2022.01.11 |
댓글을 사용할 수 없습니다.