Groq 플랫폼 사용 가이드: AI 모델 처리 속도 혁신
AI와 머신러닝의 세계는 매일 혁신으로 넘쳐나지만, 때때로 기존의 패러다임을 근본적으로 전환시키는 혁신이 등장합니다. Groq의 최근 발표는 바로 그러한 혁신적 순간 중 하나입니다.
Groq는 Meta AI의 Llama-2 70B 모델을 이용해 사용자당 초당 300 토큰을 처리하는 놀라운 성과를 달성했습니다. 이는 단순한 기록 경신을 넘어서, AI 분야에서 속도와 효율성의 새로운 장을 열었습니다. Groq는 2016년 Jonathan Ross에 의해 설립되었으며, Ross는 구글에서 Tensor Processing Unit (TPU) 프로젝트에 참여하며 AI 처리를 위한 전용 하드웨어의 중요성을 깊이 인식하게 되었습니다. TPU의 개발은 딥러닝 알고리즘을 더욱 빠르고 효율적으로 실행할 수 있게 하며, Ross가 나중에 Groq를 설립하고 LPU를 개발하게 되는 결정적인 동기가 되었습니다.

Groq 설립 이후, Ross는 Large Language Models (LLM)을 실행하기 위해 특별히 설계된 Language Processing Unit (LPU) 개발에 착수했습니다. LPU는 기존의 처리 방식에 비해 현저히 빠른 속도와 뛰어난 효율성을 제공합니다.
Groq VS GPT-4: 속도 차이
GPT-4는 자체적으로 이미 인상적인 성능을 제공하는 모델로, 초당 약 30 토큰을 처리할 수 있는 것으로 알려져 있습니다. 그러나 Meta AI의 Llama-2 70B 모델을 Groq의 Language Processing Unit (LPU)에서 수행하면 사용자당 초당 최대 300 토큰을 처리할 수 있으며, 이는 기존 클라우드 기반 모델 대비 최소 3배에서 최대 18배 이상 빠른 성능입니다.
특히 주목할 점은 Time to First Token (TTFT) 즉, 첫 번째 토큰이 생성되기까지의 시간이 0.22초에 불과하다는 것입니다. 이는 자동차의 제로백과 비슷한 개념입니다. 첫 토큰 생성 후에는 초당 300개의 토큰을 지속적으로 출력할 수 있으니, 이를 통해 얼마나 빠르게 대량의 정보를 처리할 수 있는지 알 수 있습니다.
속도가 중요한 이유
디지털 시대에서 속도는 품질과 동의어입니다. 비디오 스트리밍, 웹페이지 로딩 또는 AI와의 상호 작용이든, 사용자들은 즉각적인 반응에 익숙해져 있습니다. 몇 초의 지연조차도 상호 작용의 흐름을 방해하고 사용자 경험을 저하시킬 수 있습니다. Groq의 속도 도약은 AI 기반 서비스에 대한 이러한 격차를 메울 수 있습니다. 실시간 AI 대화, 대기 시간 없는 복잡한 데이터 처리, 즉각적인 피드백 루프의 꿈이 현실이 될 수 있습니다.
Groq 사용하기
Groq 플랫폼을 이용하면 Meta AI의 Llama-2 70B 모델과 Mixtral-8X7b 모델을 사용할 수 있습니다. GPT-4와 비교했을 때 답변 수준은 다소 낮을 수 있지만, 처리 속도의 빠르기를 직접 경험하실 수 있습니다. 이하에서는 Groq 플랫폼의 사용 방법을 간략하게 안내합니다.
1. Groq 플랫폼 접속하기
Groq 플랫폼을 사용하기 위해선 먼저 Groq의 공식 웹사이트에 접속하여 계정을 생성해야 합니다. 계정이 이미 있다면, 로그인하여 시작하세요.
GroqChat
groq.com
2. 모델 선택
현재 (3월 3일 기준) Groq 플랫폼에서는 Llama-2 70B 모델과 Mixtral-8X7b 모델을 선택하여 사용할 수 있습니다. 향후 모델 옵션은 지속적으로 확장될 예정으로 보입니다. 저는 Mixtral-8X7b 모델을 선택하겠습니다.
3. Promprt 입력 및 결과 확인
저는 'Which programming language do you recommend?'이라는 질문을 시도해 보았습니다. 아래 영상에서 확인할 수 있듯, 답변이 나오기까지 1초도 걸리지 않았습니다. (속도 조정은 전혀 없었습니다.) 결과는 우측에서 확인할 수 있듯, 초당 532.41 토큰으로 표시됩니다.

Groq TSP 아키텍처
Groq은 자체적으로 칩을 설계하고 제작함으로써, 작업 처리 시간이 항상 예측 가능하도록 하드웨어를 개발했습니다. LPU는 응답 시간이 항상 일관되도록 보장합니다. 전통적인 GPU는 SIMD(Single Instruction, Multiple Data) 모델을 사용하여 여러 작업을 처리하나, 작업량에 따라 처리 속도가 달라질 수 있습니다. 이는 처리 시간에 변동이 생기고, 대기 시간이 발생할 수 있음을 의미합니다. 반면, LPU는 응답 시간이 항상 일관되도록 보장합니다. Groq의 칩은 언제나 동일한 시간에 정확히 실행되도록 설계되어, 계획적인 수행이 가능하고 오버헤드를 줄일 수 있습니다. Groq가 개발한 이 방식은 Tensor Streaming Processor (TSP) 아키텍처라고 합니다.

Groq TSP 아키텍처는 기존 아키텍처에 비해 낮은 복잡성을 가진 것이 특징입니다. 이는 다음과 같은 이유 때문입니다.
- Groq TSP 아키텍처는 전용 계산 엔진을 사용하여 텐서 연산을 수행합니다. 이는 일반 목적의 CPU나 GPU에서 사용되는 복잡한 제어 회로를 필요로 하지 않습니다.
- Groq TSP 아키텍처는 단일 유형의 연산 엔진만 사용합니다. 이는 다양한 유형의 연산 엔진을 사용하는 기존 아키텍처에 비해 하드웨어 설계를 단순화합니다.
- Groq TSP 아키텍처는 캐시를 사용하지 않습니다. 이는 캐시 관련 복잡성을 제거합니다.

기존의 GPU는 다양한 작업을 동시에 처리할 수 있지만, 처리해야 할 작업의 양에 따라 속도가 변동될 수 있습니다. 이로 인해 처리 시간이 일정하지 않고, 결과적으로 대기 시간이 발생할 수 있습니다.
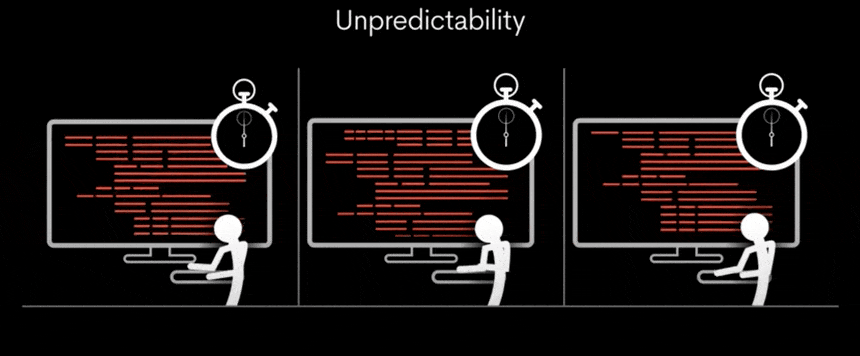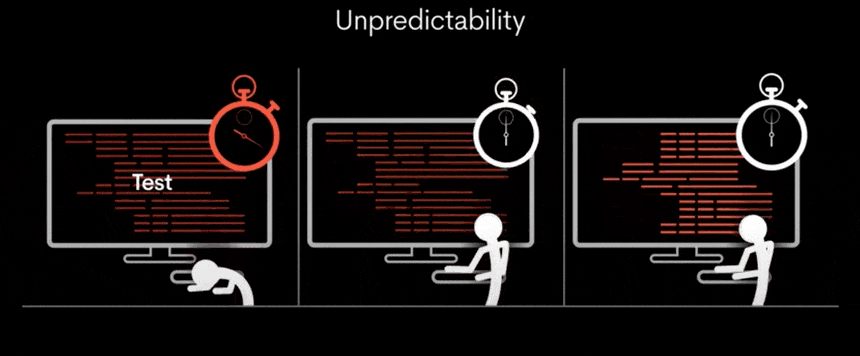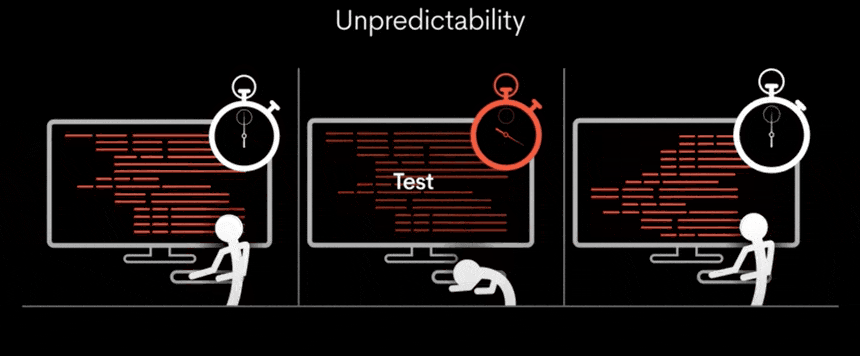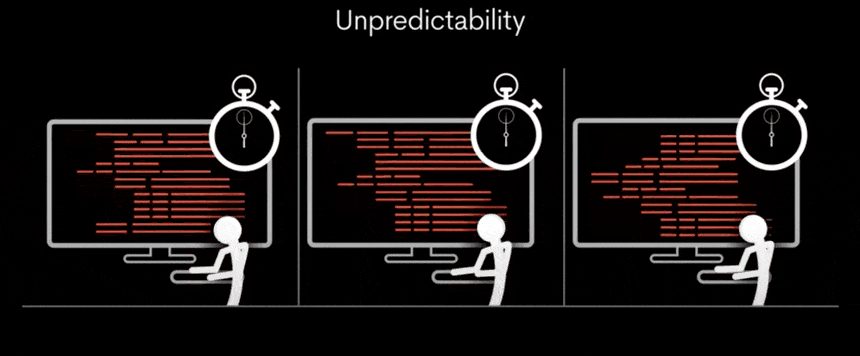
그러나 TSP(Tensor Streaming Processor) 아키텍처는 모든 작업을 동일한 시간 내에 정확하게 실행함으로써, 일관되고 신속한 처리 속도를 가능하게 합니다.

Groq의 기술은 AI 응용 프로그램의 반응 시간을 개선하고, 사용자 경험을 향상시키며, 더 넓은 범위의 복잡한 문제를 신속하게 해결할 수 있는 길을 제시합니다. 이러한 진보는 AI 기술의 미래를 향한 중요한 발걸음으로, 더욱 발전된 AI 솔루션과 혁신적인 애플리케이션의 개발을 기대하게 합니다.
'Insights > IT Trends' 카테고리의 다른 글
| DigitalOcean App 배포: 간단 가이드 (계정 생성 포함) (17) | 2024.03.13 |
|---|---|
| Claude 3 사용 가이드: 뛰어난 성능과 속도 (1) | 2024.03.08 |
| OpenAI Sora: 혁신적인 Text-to-Video (3) | 2024.02.16 |
| 구글의 Lumiere: AI 비디오 생성의 새로운 지평 (26) | 2024.01.31 |
| OpenAI: 새로운 임베딩 모델 및 API 업데이트 (1) | 2024.01.30 |
댓글을 사용할 수 없습니다.