
ChatGPT 원리는 무엇이고, 어떻게 학습되었을까?
최근 ChatGPT에 대한 관심이 엄청나게 커지고 있습니다. 지난 연말에 공개된 ChatGPT의 사용자는 전 세계 1억 명을 넘어섰고 수많은 사람들이 저마다의 방식으로 시험을 하고 있습니다. 어느 날부터 뉴스에서 한 번씩 소개가 되더니 이제는 IT 뉴스를 도배하고 있죠. 그리고 매일 새롭게 "ChatGPT가 이런 일을 해냈다."라는 식의 글들이 올라오는데, 과연 어떤 원리로 작동하고 어떻게 학습이 되었는지 알아보도록 하겠습니다.
# Chat + GPT = ChatGPT

먼저 간단히 ChatGPT에 대해 알아보겠습니다. GPT (Generative Pre-trained TGransformer)는 AGI (Artificial General Interlligence) 즉 법용 인공지능을 목표로 만들어진 AI 모델입니다. GPT를 구성하는 3개의 단어를 보면 GPT가 무엇인지 조금 더 쉽게 알 수 있는데요.
- Generative (생성 모델)
- Pre-Trained (사전 훈련)
- Transformer (Transformer AI 모델)
이 GPT 모델을 기반으로 만든 대화형 버전이 ChatGPT입니다.
# AI 트렌드는 거대화
2017년 Google에서 Transformer가 발표된 이후, OpenAI는 GPT 시리즈인 GPT-1(2018), GPT-2(2019), GPT-3(2020)을 차례로 발표했습니다. 현재의 GPT가 널리 알려진 계기는 GPT-3을 발표한 이후부터입니다. GPT-2의 구조에서 큰 변화는 없었고 파라미터의 개수가 약 100배 이상 증가한 1750억 개와 확장된 데이터셋으로 학습되었습니다. 사실 이 과정에서 OpenAI는 모델의 파라미터와 성능 간의 관계를 확인했고 모델 파라미터 크기가 클수록 정확도가 향상된다라는 것을 증명하였습니다. 그 후로 많은 빅테크 기업들이 AI 거대화와 생성형 인공지능 기술 경쟁에 뛰어들기 시작합니다.
현재는 Open AI에 투자를 했던 Microsoft가 선두 주자로 나서고 있지만 Google이 빠르게 견제에 나섰고 나라별, 언어별로 다양한 사업자가 등장하면서 경쟁이 본격화되고 있습니다. 그리고 많은 기업들이 ChatGPT를 자신의 비즈니스 활용 가능성을 모색하는 것이 큰 유행처럼 번지고 있습니다.
분명 ChatGPT는 기업이 고객과 상호 작용하는 방식을 혁신할 수 있는 강력한 AI 기술이지만 활용을 모색하기 전에 ChatGPT가 어떻게 학습되었는지 이해할 필요가 있습니다.
# ChatGPT는 언어 모델 (Language Model)
ChatGPT를 초거대 AI라고 소개하는 사람도 있지만, 정확히 말하면 LLM (a Large Language Model) 거대 언어 모델입니다. ChatGPT 이전에도 다양한 언어 모델이 있었지만 자연어 처리는 고차원의 추론을 필요로 하기 때문에 한계가 있다고 여겨져 왔습니다. 하지만 2020년 GPT-3 발표를 시작으로 빠르게 발전해 왔으며 현재는 이미 상상을 뛰어넘을 정도의 성능을 보여주고 있습니다. 먼저 언어 모델이 무엇인지 간단히 알아보도록 하겠습니다.
언어 모델은 주어진 이전 단어들을 바탕으로 다음에 나올 단어나 문장을 예측하는 모델입니다. 간단히 위의 예제에서 빈칸을 "나는 학교에 갑니다."로 예측하는 것이죠. 예제만 본다면 단순해 보일 수 있지만 주어지는 단어나 문맥을 이해하여 비어 있는 영역을 채우는 것은 쉬운 일은 아닙니다. 그렇기 때문에 과거의 언어 모델은 부자연스럽거나 기계적인 느낌이 있었습니다. 하지만 ChatGPT는 파라미터의 증가와 방대한 양의 데이터를 이용하여 학습시키면서 단순히 답변을 예상하여 답을 내놓는 수준을 넘어 지식을 다루는 영역에서는 꽤 훌륭한 성능을 보여주고 있습니다. (물론 고차원적인 추론이나 창의적인 내용을 생성하기는 힘들지만 이미 존재했던 내용을 조합하여 문장을 만들어내기 때문에 답을 찾아 주는 것처럼 느껴지기도 하고 조합된 문장이 새로 창조된 것처럼 느껴지기도 합니다.) 사실 사람의 학습 방식 역시 그림, 음악 등을 제외하면 대부분 글을 통해 배우기 때문에 텍스트로 학습된 ChatGPT 역시 활용이 가능한 범위가 넓습니다.
# 재료(데이터)는 사람이 만든 것이다
데이터는 ChatGPT가 기존 언어 모델 대비 뛰어난 성능을 보이며 도약하게 한 주요 요소입니다. 여기서 말하는 데이터는 맥락이 없이 존재하는 데이터가 아니라 ChatGPT가 이해하는 방식과 수준으로 가공된 데이터를 의미합니다. 아래는 ChatGPT의 데이터세트 양식인데 인터넷에 존재하는 수많은 말뭉치를 의미 있는 데이터로 생성하는 일은 매우 고되고 힘들었을 것으로 예상이 됩니다.
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
...또한 데이터를 수집하는 과정에서 데이터를 선별하는 작업 역시 모두 사람이 진행합니다. 폭력, 증오 표현, 성차별, 인종차별 등의 표현이 담긴 유해한 데이터를 필터링하는 작업이 필요했고 이를 위해 OpenAI는 케냐의 아웃소싱 회사인 Sama와 함께 일을 했습니다.
Sama는 케냐, 우간다, 인도 등의 직원으로 이루어져 있는 회사인데 숙련도에 따라 시간당 1.32 ~ 2달러를 지불했고 저임금에 매우 열악한 처우로 노동 착취를 했다는 기사까지 실립니다. 그리고 매일 몇 시간씩 앉아서 유해 콘텐츠를 보고 증오 표현, 성폭력, 수간, 폭력에 대해 분석해야 했던 직원에게는 그 작업이 트라우마였습니다. 이로 인해 Sama는 2022년 2월 OpenAI와 체결한 3건의 계약을 모두 취소했습니다. GPT-4를 출시예정인 OpenAI는 현재 데이터 아웃소싱하는 방법에 대해 고심을 하고 있습니다.
Exclusive: The $2 Per Hour Workers Who Made ChatGPT Safer
A TIME investigation reveals the difficult conditions faced by the workers who made ChatGPT possible
time.com
이렇게 학습을 위한 거대한 언어 데이터베이스가 생성되었습니다. GPT-3에 사용된 데이터세트는 Comman Crawl, WebText2, Books1, Books2, Wikipedia 등이며 데이터세트의 총 용량은 735GB 입니다.
# 다시 사람이 한땀 한땀 가르쳤다
ChatGPT 이전에도 대규모 언어 모델을 이용한 챗봇이나 AI는 많았습니다. 기본적으로 인터넷의 방대한 텍스트 데이터를 활용해 가르치면 사람을 흉내 낸 문장을 만드는 일은 어렵지 않게 가능했습니다. 하지만 답변이 사람의 기대에 미치지 못하거나 원하는 의도를 파악하지 못하는 경우가 많았죠. 일반적으로 언어 모델이 학습시키는 방법대로 다음에 나올 단어와 문장을 생성하는 것을 반복하면 점차 자연스럽고 유창한 문장을 생성하지만 엉뚱한 단어로 생성하거나 질문자의 의도와는 전혀 다른 답을 내놓기도 하기 때문입니다. ChatGPT는 이를 해결하기 위해 사람이 직접 개입하여 문제를 해결하는 방법을 시도합니다. 사실 OpenAI는 AI 학습에서 사람의 개입 필요성과 관련하여 여러 차례 논문을 발표했었습니다.
ChatGPT에는 RLHF(Reinforcement Learning from Human Feedback)이라는 강화학습 방법을 사용하여 훈련을 시켰는데 말 그대로 사람의 피드백을 이용해 강화 학습을 시켰다는 뜻입니다. 살펴보면 크게 3단계로 이루어져 있습니다.
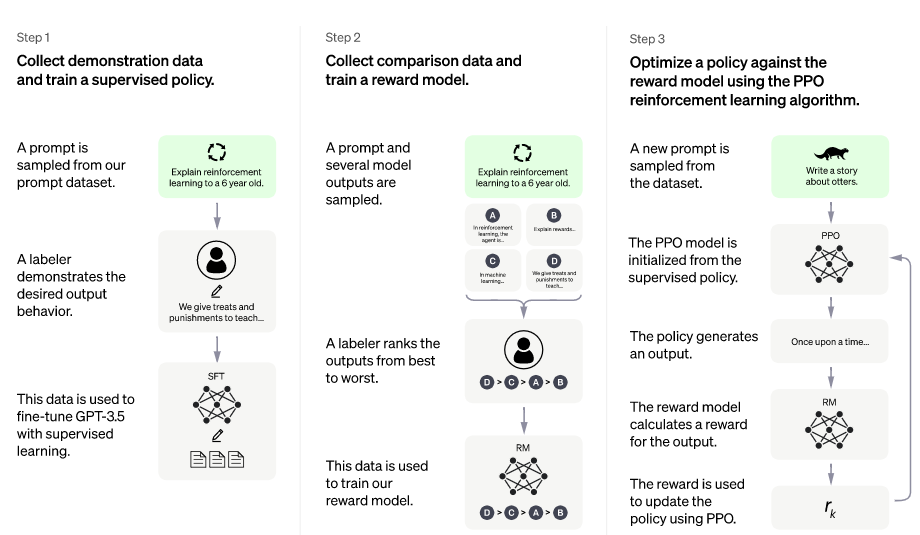
Step 1. Pretraining Language Model
Step 1을 살펴보면 OpenAI는 인터넷에서 떠도는 데이터 전체를 신뢰하지 않았습니다. 그렇기 때문에 신뢰할 수 있는 질문과 답안만을 가지고 지도 학습(Supervised find-tuning)을 시켰습니다. 데이터 양이 제한되어 있기 때문에 질문자의 의도와 다르게 답변을 내놓는 모델이었고 여기까지는 일반적인 언어 모델과 동일합니다.
Step 2. Reward Model training
Step 1의 언어 모델에 질문을 하고 여러 답변을 받습니다. 그렇게 생성된 여러 답변 중 질문자의 의도와 부합하는지 평가해 순위를 매깁니다. 이를 별도로 데이터베이스화하고 이 데이터를 이용해 학습을 반복하면서 답변 우선순위를 예측하도록 합니다.
Step 3. Fine-tuning with RL
Step 3는 PPO(Proximal Policy Optimization) 알고리즘을 사용하여 언어 모델의 파라미터 일부 또는 전체를 fine-tuning 하는 방법을 사용합니다. 학습에 사용한 데이터가 아닌 새로운 질문으로 생성된 답변을 보고 문제점을 미세하게 조정하는 단계입니다. 선별된 데이터세트로 진행한 Step1 ~ Step2 과정의 결과가 갖고 있는 한계를 극복하고 정확도를 높이기 위함입니다. (예를 들어 3개의 도박 기계가 있을 때 가장 수익을 많이 낼 수 있는 기계를 알 수 없으니 번갈아가며 동전을 넣다가 효과가 가장 좋아 보이는 기계에 점점 더 많은 돈을 넣는 방식의 추론입니다. 언어 모델의 경우에는 질문에 정확하게 답변할 가능성과 실제 정확하게 답변한 사례를 분석하는 데 사용합니다.)
# 성능평가 역시 사람
ChatGPT의 최종 성능평가 역시 사람이 했습니다. 첫째는 질문의 의도를 적절히 파악하여 답변을 내놓았는지 "유용성"을 평가합니다. 둘째는 데이터를 조합해 거짓 답변을 내놓았는지 "진실성"을 평가합니다. 마지막으로 폭력, 성차별, 인종차별 같은 편향된 답변은 없는지 "무해성"을 평가합니다.
ChatGPT가 현존하는 AI 서비스 중 가장 강력한 성능을 가진 것은 부인할 수 없습니다. 하지만 테스트 데이터를 선별하고 생성하는 것도 사람, 답변의 우선순위를 정하는 것도 사람, 교육과 평가를 하는 것도 사람입니다. 데이터 선별, 학습, 성능평가에 사람이 적극적으로 개입하다 보니 ChatGPT에는 사람의 편향성이 존재하고 결과에 대한 신뢰와 책임 문제, 윤리 문제가 여전히 남아 있습니다.
연일 신기록을 쓰고 있는 ChatGPT이지만 OpenAI CEO 샘 알트만은 "ChatGPT는 매우 제한적이며 지금 당장 중요한 일을 의존하는 것은 실수"라고 이야기했습니다. 또 직원들이 ChatGPT의 성공을 자랑하지 못하도록 막고 있다고도 전해집니다. 현재 커지는 인기만큼 ChatGPT의 오류와 부작용에 대한 지적과 우려도 커지고 있기 때문입니다.
2023년 2월 6일에는 Google CEO 순다 피차이는 공식 블로그를 통해 AI 챗봇 바드(bard)를 발표합니다. 사실 Google의 기술이나 데이터가 OpenAI보다 부족하여 발표가 늦었다고 생각되지는 않습니다. GPT의 사용된 Transformers 역시 Google에서 발표된 논문이기 때문이죠. 다만 윤리적인 문제와 아직 사회적으로 합의되지 않은 영역에 대해 신중했던 것 같습니다. Google은 2018년에 AI원칙을 발표했으며 이를 바탕으로 AI가 안전하고 유용하게 사용될 수 있도록 책임감 있는 방식으로 변화해 나갈 것이라고 밝혔습니다.
구글 AI 원칙
- 사회적으로 유익할 것
- 불공정한 편견을 만들거나 강화하지 않을 것
- 안전을 지향할 것
- 사람들에게 책임을 다할 것
- 프라이버시 디자인 원칙을 지킬 것
- 과학적 우수성에 대한 높은 기준을 유지할 것
# 슈퍼 컴퓨팅 인프라 (Money..)
초거대 AI의 등장으로 일반 성능의 GPU 서버로는 문제 해결이 거의 불가능해졌습니다. 대규모 AI 모델을 단일 GPU 서버로 학습을 시킨다면 수십에서 수백 년이 걸릴 수도 있지만 수백 수 천 개의 GPU를 병렬로 학습할 경우 시간을 현실적으로 크게 단축할 수 있기 때문에 슈퍼컴퓨팅 인프라 환경 구축은 필수적입니다. 네이버의 경우 하이퍼클로버를 위해 140개의 컴퓨팅 노드에 1,120개의 GPU를 장착한 슈퍼컴퓨팅 인프라를 구축했고 SKT 역시 2021년부터 구축해 운영 중인 슈퍼컴퓨터를 최근 에이닷 서비스를 위해 NVIDIA A100 GPU를 기존 대비 2배인 1,040개로 증설했습니다.
그리고 정확하게 추산할 수는 없지만 부가적인 비용을 제외하고 GPT-3을 학습시키는 데만 대략 150억~340억 원 정도가 소요된 것으로 추정합니다. GPT-3 수준의 오픈소스 언어 모델인 블룸(Bloom)을 학습시키는데 nVidia A100 GPU 384개를 이용하여 3개월 동안 수행해야 했고, 학습된 모델을 수행시키는데 A100 GPU 8개가 장착된 전용 하드웨어가 필요했다고 하니 이를 토대로 계산을 하더라도 막대한 비용이죠. (일부에서 GTP-4는 100조 개의 파라미터 모델이 될 것이라는 예상이 있는데 OpenAI CEO 샘 알트만은 터무니없는 이야기라고 일축했습니다. 100조 개의 파라미터를 가진 모델을 학습시키려면 엄청난 컴퓨팅 리소스가 필요하고 데이터세트 역시 그에 상응하는 양이 필요하기 때문입니다.)
결국 학습을 위해서도 막대한 컴퓨팅 자원이 필요하며, 서비스를 하기 위해서도 역시 막대한 컴퓨팅 자원이 필요합니다. 이는 OpenAI가 비영리 단체에서 영리 기업으로 전환한 이유이기도 합니다.
ChatGPT 이전에는 이미 많은 기업들이 AI 도입 및 상용화 실패를 경험했고, 투자 대비 낮은 효과로 AI에 대한 거부감으로 이어졌습니다. (Gartner의 애널리스트 Svetlana Sicular는 "2020년부터 AI 하강의 해가 본격적으로 시작됐다"라고 말했고, 벤처캐피털 펀드인 MMC Ventures는 유럽의 AI 스타트업을 조사한 뒤 이 중 40%가 아예 AI 기술을 쓰지 않는다고 발표했죠.) 하지만 ChatGPT의 등장 이후 많은 것이 바뀌었죠. 가장 고무적인 것은 과거 AI 서비스와 달리 탄탄한 비즈니스 모델을 가지고 있다는 것입니다. API와 고성능 모델, 비즈니스에 특화된 Fine-tuning 모델 등을 제공하며 이용료를 받을 수 있습니다.
지금의 AI 발전 양상은 빅테크가 아닌 회사나 연구소가 시도할 수 있는 수준을 넘어섰으며 국가와 기업이 협력해 하드웨어를 구축하고 데이터를 준비하여야만 가능한 수준입니다. 하지만 단순히 ChatGPT의 성공만을 보고 자신의 비즈니스에 적용하겠다는 판단을 한다면 또다시 AI 도입 실패, 상용화 실패로 이어질 것입니다. 변화하는 AI에 대응하고 성공적인 도입을 위해서는 반드시 사람, 데이터, 인프라가 필요합니다. 그리고 리더의 최적의 의사결정 역시 필요합니다.